概率图模型学习笔记:HMM、MEMM、CRF
一、Preface
二、Prerequisite
2.1 概率图
2.1.1 概览
2.1.2 有向图 vs. 无向图
2.1.3 马尔科夫假设&马尔科夫性
2.2 判别式模型 vs. 生成式模型
2.3 序列建模
三、HMM
3.1 理解HMM
3.2 模型运行过程
3.2.1 学习过程
3.2.2 序列标注(解码)过程
3.2.3 序列概率过程
四、MEMM
4.1 理解MEMM
4.2 模型运行过程
4.2.1 学习过程
4.2.2 序列标注(解码)过程
4.2.3 序列概率过程
4.3 标注偏置?
五、CRF
5.1 理解CRF
5.2 模型运行过程
5.2.1 学习过程
5.2.2 解码过程
5.2.3 序列概率过程
5.3 CRF++分析
5.4 LSTM+CRF
六、总结
Referrence
一、Preface
之前刚接触NLP时做相关的任务,也必然地涉及到了序列处理任务,然后自然要接触到概率图模型。当时在全网搜中文资料,陆续失望地发现竟然真的没有讲得清楚的博文,发现基本是把李航老师书里或CRF tutorial等资料的文字论述和公式抄来抄去的。当然,没有说别人讲的是错的,只是觉得,要是没有把东西说的让读者看得懂,那也是没意义啊。或者有些吧,就是讲了一大堆的东西,貌似也明白了啥,但还是不能让我很好的理解CRF这些模型究竟是个啥,完了还是有一头雾水散不开的感觉。试想,一堆公式扔过来,没有个感性理解的过渡,怎么可能理解的了。我甚至觉得,如果博客让人看不懂,那说明要么自己没理解透要么就是思维不清晰讲不清楚。所以默想,深水区攻坚还是要靠自己,然后去做调研做research,所以就写了个这个学习记录。
所以概率图的研究学习思考列入了我的任务清单。不过平时的时间又非常的紧,只能陆陆续续的思考着,所以时间拖得也真是长啊。
这是个学习笔记。相比其他的学习模型,概率图貌似确实是比较难以理解的。这里我基本全部用自己的理解加上自己的语言习惯表达出来,off the official form,表达尽量接地气。我会尽量将我所有理解过程中的每个关键小细节都详细描述出来,以使对零基础的初学者友好。包括理论的来龙去脉,抽象具象化,模型的构成,模型的训练过程,会注重类比的学习。
根据现有资料,我是按照概率图模型将HMM,MEMM,CRF放在这里一起对比学习。之所以把他们拿在一起,是因为他们都用于标注问题。并且之所以放在概率图框架下,是完全因为自己top-down思维模式使然。另外,概率图下还有很多的模型,这儿只学习标注模型。
正儿八经的,我对这些个概率图模型有了彻悟,是从我明白了生成式模型与判别式模型的那一刻。一直在思考从概率图模型角度讲他们的区别到底在哪。
另外,篇幅略显长,但咱们不要急躁,好好看完这篇具有良好的上下文的笔记,那肯定是能理解的,或者就多看几遍。
个人学习习惯就是,要尽可能地将一群没有结构的知识点融会贯通,再用一条树状结构的绳将之串起来,结构化,就是说要成体系,这样把绳子头一拎所有的东西都能拿起来。学习嘛,应该要是一个熵减的过程,卓有成效的学习应该是混乱度越来越小!这个思维方式对我影响还是蛮大的。
在正式内容之前,还是先要明确下面这一点,最好脑子里形成一个定势:
统计机器学习所有的模型(个别instant model和优化算法以及其他的特种工程知识点除外)的工作流程都是如此:
a.训练模型参数,得到模型(由参数唯一确定),
b.预测给定的测试数据。
拿这个流程去挨个学习模型,思路上会非常顺畅。这一点可参见我另一篇文字介绍。
除此之外,对初学者的关于机器学习的入门学习方式也顺带表达一下(empirical speaking):
a.完整特征工程竞赛
b.野博客理论入门理解
c.再回到代码深入理解模型内部
d.再跨理论,查阅经典理论巨作。这时感性理性都有一定高度,会遇到很多很大的理解上的疑惑,这时3大经典可能就可以发挥到最大作用了。
很多beginer,就比如说学CRF模型,然后一上来就摆一套复杂的公式,什么我就问,这能理解的了吗?这是正确的开启姿势吗?当然了,也要怪那些博主,直接整一大堆核心公式,实际上读者的理解门槛可能就是一个过渡性的细枝末节而已。没有上下文的教育肯定是失败的(这一点我又想吐槽国内绝大部分本科的院校教育模式)。所以说带有完整上下文信息以及过程来龙去脉交代清楚才算到位吧。
而不是一上来就死啃被人推荐的“经典资料”,这一点相信部分同学会理解。好比以前本科零基础学c++ JAVA,上来就看primr TIJ,结果浪费了时间精力一直在门外兜圈。总结方法吸取教训,应该快速上手代码,才是最高效的。经典最好是用来查阅的工具书,我目前是李航周志华和经典的那3本迭代轮询看了好多轮,经常会反复查询某些model或理论的来龙去脉;有时候要查很多相关的东西,看这些书还是难以贯通,然后发现有些人的博客写的会更容易去理解。所以另外,学习资料渠道也要充分才行。
最后提示一下,请务必按照标题层级结构和目录一级一级阅读,防止跟丢。
二、Prerequisite
2.1 概率图
之前刚接触CRF时,一上来试图越过一堆繁琐的概率图相关概念,不过sad to say, 这是后面的前驱知识,后面还得反过来补这个点。所以若想整体把握,系统地拿下这一块,应该还是要越过这块门槛的。
当然了,一开始只需略略快速看一篇,后面可再返过来补查。
2.1.1 概览
在统计概率图(probability graph models)中,参考宗成庆老师的书,是这样的体系结构(个人非常喜欢这种类型的图):
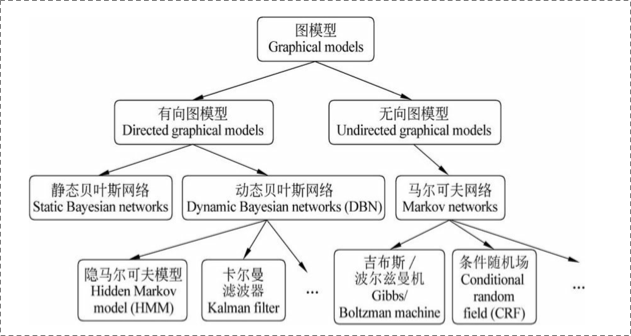
在概率图模型中,数据(样本)由公式 
应该这样表示他们的联合概率:

如果一个graph太大,可以用因子分解将 
2.3 序列建模
为了号召零门槛理解,现在解释如何为序列问题建模。
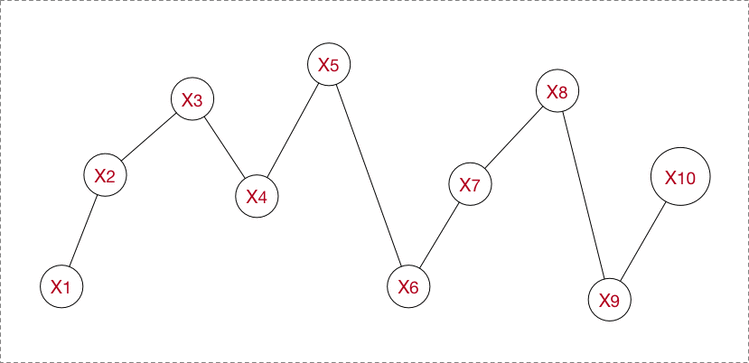
序列包括时间序列以及general sequence,但两者无异。连续的序列在分析时也会先离散化处理。常见的序列有如:时序数据、本文句子、语音数据、等等。
广义下的序列有这些特点:
- 节点之间有关联依赖性/无关联依赖性
- 序列的节点是随机的/确定的
- 序列是线性变化/非线性的
- ……
对不同的序列有不同的问题需求,常见的序列建模方法总结有如下:
- 拟合,预测未来节点(或走势分析):
a. 常规序列建模方法:AR、MA、ARMA、ARIMA
b. 回归拟合
c. Neural Networks
2. 判断不同序列类别,即分类问题:HMM、CRF、General Classifier(ML models、NN models)
3. 不同时序对应的状态的分析,即序列标注问题:HMM、CRF、RecurrentNNs
在本篇文字中,我们只关注在2. & 3.类问题下的建模过程和方法。
三、HMM
最早接触的是HMM。较早做过一个项目,关于声波手势识别,跟声音识别的机制一样,使用的正是HMM的一套方法。后来又用到了kalman filter,之后做序列标注任务接触到了CRF,所以整个概率图模型还是接触的方面还蛮多。
3.1 理解HMM
在2.2、2.3中提序列的建模问题时,我们只是讨论了常规的序列数据,e.g., 
看的很清楚,我的模型先去学习要确定以上5要素,之后在inference阶段的工作流程是:首先,隐状态节点 


2. Baum-Welch(前向后向)
就是一个EM的过程,如果你对EM的工作流程有经验的话,对这个Baum-Welch一看就懂。EM的过程就是初始化一套值,然后迭代计算,根据结果再调整值,再迭代,最后收敛……好吧,这个理解是没有捷径的,去隔壁钻研EM吧。
这里只提一下核心。因为我们手里没有隐状态序列 
关键是注意,每次工作热点区只涉及到t 与 t-1,这对应了DP的无后效性的条件。如果对某些同学还是很难理解,请参考这个答案下@Kiwee的回答吧。
3.2.3 序列概率过程
我通过HMM计算出序列的概率又有什么用?针对这个点我把这个问题详细说一下。
实际上,序列概率过程对应了序列建模问题2.,即序列分类。
在3.2.2第一句话我说,在序列标注问题中,我用一批完整的数据训练出了一支HMM模型即可。好,那在序列分类问题就不是训练一个HMM模型了。我应该这么做(结合语音分类识别例子):
目标:识别声音是A发出的还是B发出的。
HMM建模过程:
1. 训练:我将所有A说的语音数据作为dataset_A,将所有B说的语音数据作为dataset_B(当然,先要分别对dataset A ,B做预处理encode为元数据节点,形成sequences),然后分别用dataset_A、dataset_B去训练出HMM_A/HMM_B
2. inference:来了一条新的sample(sequence),我不知道是A的还是B的,没问题,分别用HMM_A/HMM_B计算一遍序列的概率得到 
MEMM需要两点注意:
- 与HMM的

用Viterbi算法解码MEMM,状态1倾向于转换到状态2,同时状态2倾向于保留在状态2。 解码过程细节(需要会viterbi算法这个前提):
P(1-> 1-> 1-> 1)= 0.4 x 0.45 x 0.5 = 0.09 ,
P(2->2->2->2)= 0.2 X 0.3 X 0.3 = 0.018,
P(1->2->1->2)= 0.6 X 0.2 X 0.5 = 0.06,
P(1->1->2->2)= 0.4 X 0.55 X 0.3 = 0.066
但是得到的最优的状态转换路径是1->1->1->1,为什么呢?因为状态2可以转换的状态比状态1要多,从而使转移概率降低,即MEMM倾向于选择拥有更少转移的状态。
2. 解释原因
直接看MEMM公式:

在2.1.2中有提到过,概率无向图的联合概率分布可以在因子分解下表示为:

2. HMM vs. MEMM vs. CRF
将三者放在一块做一个总结:
- HMM -> MEMM: HMM模型中存在两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关。但实际上序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。MEMM解决了HMM输出独立性假设的问题。因为HMM只限定在了观测与状态之间的依赖,而MEMM引入自定义特征函数,不仅可以表达观测之间的依赖,还可表示当前观测与前后多个状态之间的复杂依赖。
- MEMM -> CRF:
- CRF不仅解决了HMM输出独立性假设的问题,还解决了MEMM的标注偏置问题,MEMM容易陷入局部最优是因为只在局部做归一化,而CRF统计了全局概率,在做归一化时考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置的问题。使得序列标注的解码变得最优解。
- HMM、MEMM属于有向图,所以考虑了x与y的影响,但没讲x当做整体考虑进去(这点问题应该只有HMM)。CRF属于无向图,没有这种依赖性,克服此问题。
3. Machine Learning models vs. Sequential models
为了一次将概率图模型理解的深刻到位,我们需要再串一串,更深度与原有的知识体系融合起来。
机器学习模型,按照学习的范式或方法,以及加上自己的理解,给常见的部分的他们整理分了分类(主流上,都喜欢从训练样本的歧义型分,当然也可以从其他角度来):
一、监督:{1.1 分类算法(线性和非线性):{感知机KNN概率{朴素贝叶斯(NB)Logistic Regression(LR)最大熵MEM(与LR同属于对数线性分类模型)}支持向量机(SVM)决策树(ID3、CART、C4.5)assembly learning{Boosting{Gradient Boosting{GBDTxgboost(传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题);xgboost是Gradient Boosting的一种高效系统实现,并不是一种单一算法。)}AdaBoost} Bagging{随机森林}Stacking}……
}1.2 概率图模型:{HMMMEMM(最大熵马尔科夫)CRF……
}1.3 回归预测:{线性回归树回归Ridge岭回归Lasso回归……
}……
}二、非监督:{
2.1 聚类:{1. 基础聚类K—mean二分k-meanK中值聚类GMM聚类2. 层次聚类3. 密度聚类4. 谱聚类()
}2.2 主题模型:{pLSALDA隐含狄利克雷分析
}2.3 关联分析:{Apriori算法FP-growth算法
}2.4 降维:{PCA算法SVD算法LDA线性判别分析LLE局部线性嵌入
}2.5 异常检测:
……
}三、半监督学习四、迁移学习
(注意到,没有把神经网络体系加进来。因为NNs的范式很灵活,不太适用这套分法,largely, off this framework)
Generally speaking,机器学习模型,尤其是有监督学习,一般是为一条sample预测出一个label,作为预测结果。 但与典型常见的机器学习模型不太一样,序列模型(概率图模型)是试图为一条sample里面的每个基本元数据分别预测出一个label。这一点,往往是beginner伊始难以理解的。
具体的实现手段差异,就是:ML models通过直接预测得出label;Sequential models是给每个token预测得出label还没完,还得将他们每个token对应的labels进行组合,具体的话,用viterbi来挑选最好的那个组合。
over
有了这道开胃菜,接下来,读者可以完成这些事情:完善细节算法、阅读原著相关论文达到彻底理解、理解相关拓展概念、理论创新……
hope those hlpe!
欢迎留言!
有错误之处请多多指正,谢谢!
Referrences:
《统计学习方法》,李航
《统计自然语言处理》,宗成庆
《 An Introduction to Conditional Random Fields for Relational Learning》, Charles Sutton, Andrew McCallum
《Log-Linear Models, MEMMs, and CRFs》,ichael Collins
如何用简单易懂的例子解释条件随机场(CRF)模型?它和HMM有什么区别?
【中文分词】最大熵马尔可夫模型MEMM - Treant - 博客园
【中文分词】最大熵马尔可夫模型MEMM - Treant - 博客园
timvieira/crf
shawntan/python-crf
Log-linear Models and Conditional Random Fields
如何轻松愉快地理解条件随机场(CRF)?
条件随机场CRF(三) 模型学习与维特比算法解码
crf++里的特征模板得怎么理解?
CRF++代码分析-码农场
CRF++源码解读 - CSDN博客
CRF++模型格式说明-码农场
标注偏置问题(Label Bias Problem)和HMM、MEMM、CRF模型比较<转>
作者&#xff1a;Scofield
链接&#xff1a;https://www.zhihu.com/question/35866596/answer/236886066
来源&#xff1a;知乎
著作权归作者所有。商业转载请联系作者获得授权&#xff0c;非商业转载请注明出处。





 京公网安备 11010802041100号
京公网安备 11010802041100号