作者:1986欠我一个拥抱_567 | 来源:互联网 | 2023-10-10 05:04
论文地址:FickleNet:WeaklyandSemi-supervisedSemanticImageSegmentationusingStochasticInfe
论文地址: FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference
1. 简介 弱监督图像语义分割的难点在于如何从粗糙的图像级别的标注中获取像素级别的的信息。大多数基于图像级别标注的方法都利用了从分类器得到的位置图,但是这些方法重点关注目标较小的显著的部分,并不能获得精准的边界。
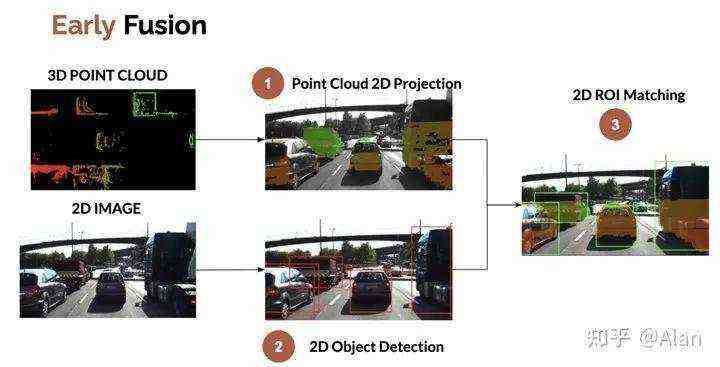
论文提出FickleNet,探索深度卷积神经网络特征图不同位置的组合,学习神经网络各隐藏单元的一致性关系以识别目标的显著部分同时获得精准的边界以及其他部分。FickleNet通过Dropout层实现卷积神经网络隐藏层各单元的随机结合,为单幅图像上产生多个位置图,得到多个形状不同的区域,从而更快地描绘出目标的轮廓,如下图所示。
2. 相关工作 介绍了弱监督近年来的思路和方法,主要有图像层级的区域隐藏或擦除,特征层级的隐藏或擦除以及区域生长的方法。
3. 方法思路 方法主要分为几步:首先通过FickleNet随机选择隐藏单元,用于训练多类别分类器;之后生成位置图;最终使用位置图上的伪标签训练语义分割模型。用x∈Rk×h×wx \in R^{k \times h \times w} x ∈ R k × h × w kk k ww w hh h
3.1 隐藏单元的随机选取 第一步是隐藏单元的随机选取,它通过随机选择不同组合的隐藏单元计算分类的分数以发现不同单元之间的联系,这样的目的是将目标显著的部分和不显著的部分联系器来。这样的操作是通过在特征图xx x
该方法产生了许多不同尺寸和形状的感受野,如下图所示,一些感受野与扩张卷积有些相似,具体地,该选择方法通过带有中心保留dropout的扩张技术来实现。
3.1.1 特征图扩张 论文提出的方法需要在每一个滑动窗口的位置进行采样得到新的组合,无法直接应用通用的深度学习框架,如果按照上面介绍的方式来实现,需要在每一个前向传导中使用w×hw \times h w × h
如下图所示,论文将输入的特征图放大,避免滑动窗口重叠。在特征图扩张之前,论文为其添加zero padding,尺寸变为k×(h+s−1)×(w+s−1)k \times (h+s-1) \times(w+s-1) k × ( h + s − 1 ) × ( w + s − 1 ) ss s xexpandx^{expand} x e x p a n d k×(sh)×(sw)k \times (sh) \times (sw) k × ( s h ) × ( s w ) xexpandx^{expand} x e x p a n d
3.1.2 中心保留空间Dropout 论文在空间位置上应用dropout实现隐藏单元的随机选取,通过在扩张过的特征图上应用dropout,这个dropout操作时保留卷积核中心的,这样核中间和其他位置的关系可以找到。通过一个rate为pp p xpexpandx_p^{expand} x p e x p a n d
3.1.3 分类 为了得到分类分数,使用卷积核尺寸和步长都为ss s xpexpandx_p^{expand} x p e x p a n d c×w×hc \times w \times h c × w × h cc c
3.2 位置图的推理 之后的步骤是从一张图上获得多个分类分数,每一个都产生了一个位置图。下面的两个操作一个是为了从每一个随机选取上获得位置图,一个描述了如何将这些随机选取集成在单个位置图。
3.2.1 Grad-CAM 论文使用基于梯度的CAM方法获取位置图,该方法能够发现每一个隐藏单元对分类分数的贡献,即根据特征图计算目标类别分数的梯度,然后在通道维度把特征图相加,以这些梯度维权中,公式如下:
Grad−CAMc=ReLU(∑kxk×∂Sc∂xk)Grad-CAM^c=ReLU(\sum _k x_k \times \frac{\partial S^c}{\partial x_k}) G r a d − C A M c = R e L U ( k ∑ x k × ∂ x k ∂ S c )
其中xk∈Rw×hx_k \in R^{w \times h} x k ∈ R w × h xx x kk k ScS^c S c cc c
3.2.2 将位置图集成 FickleNet从单张图像上获得多个位置图,因为隐藏单元的不同组合都会用来计算每一个随机选取的分类分数,这样得到了NN N uu u
3.3 训练分割网络 上面提到的位置图带有伪标签,用于分割网络的训练,损失函数如下:
L=Lseed+Lboundary+αLfullL=L_{seed}+L_{boundary}+\alpha L_{full} L = L s e e d + L b o u n d a r y + α L f u l l
LseedL_{seed} L s e e d
Lfull=−1∑c∈C∣Fc∣∑c∈C∑u∈FclogHu,cL_{full}=-\frac{1}{\sum_{c\in C}|F_c|} \sum_{c \in C} \sum_{u \in F_c}logH_{u,c} L f u l l = − ∑ c ∈ C ∣ F c ∣ 1 c ∈ C ∑ u ∈ F c ∑ l o g H u , c
其中Hu,cH_{u,c} H u , c HH H cc c uu u FcF_c F c
4. 实验结果 基础分割网络使用DeepLab-VGG16时VOC2012验证集和测试集上的弱监督结果
础分割网络使用DeepLab-ResNet时VOC2012验证机和测试集上的弱监督结果
DeepLab-based半监督方法在VOC2012验证集上的结果
使用特征图扩张带来的内存占用和时间
不同dropout率的影响
定性分析 不同的N的选取 和DSRG方法对比
5. 结论 论文旨在解决只用图像级别标注的语义分割方法的问题,在训练和推断时随机选择特征,为单幅图像获得多个不同的位置图,最后集成在一张位置图中。GPU占用有些许增加但是可以接受,并且在许多弱监督和半监督方法上取得了更好的效果。
欢迎扫描二维码关注微信公众号 深度学习与数学 [每天获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]
























 京公网安备 11010802041100号
京公网安备 11010802041100号