分布式协调服务
维护:
1、配置信息
2、命名
3、分布式同步
4、组服务
大多分布式应用都需要处理以上的问题,不同的应用实现在或作或者存在缺陷,即便正确因为不用的实现导致管理的复杂性。
zookeeper-动物园管理员
1、提供以上通用的服务
2、接口简单易用,无需重新编写
概述
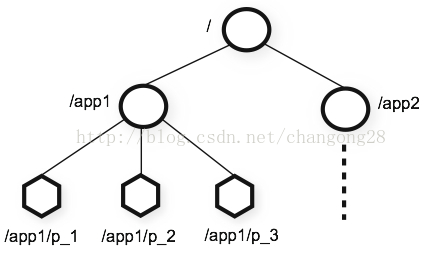
1、共享树状结构结构的命名树(类似文件系统结构)
2、zookeeper的数据保存在内存可以获得好吞吐低延迟的性能
3、高性能,高可用(无单点故障),严格顺序访问(复杂的同步原语在客户端实现)
冗余备份:
1、服务端将状态信息保存在内存并将事务日志和快照持久化。
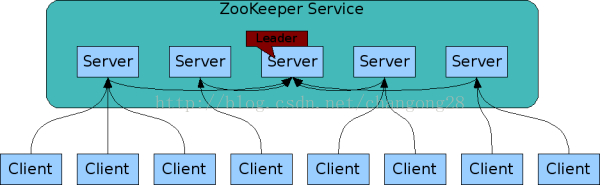
2、客户端和服务端保持tcp连接,同过它进行发送请求、获取响应,获得观察事件(watch),发送心跳。如果断开连接,将连接到其他服务上上。
3、zookeeper读取速度很快,读的性能大于写入的性能,比率为10:1
数据模型和层级结构的命名空间
1、每一个zookeeper的命名空间由一个路径指定。
2、每个节点由数据和孩子节点关联。
3、znodes维持一个状态结构。
4、zookeeper支持对一个znode进行观察(watch),当znodes改变时候会触发watch,watch触发后
客户端会接受到一个事件,告诉说znode发生了变化。
保证:
1、顺序一致性,客户端的更新请求会有序执行
2、原子性,更新要么成功,要么失败
3、单一系统镜像。
4、可靠性、当发生更新操作时将马上持久化
5、实时性
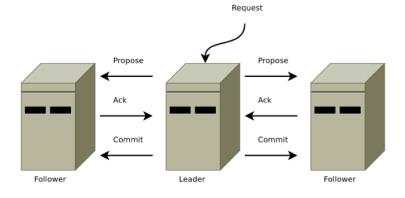
写入操作流程:
客户端发送写入请求后,zookeeper的server端将写入请求转发给lead的server,更新自己内存数据库然后将更新数据广播给其他的
server,接受后的follower更新自己内存数据库。客户端发送读请求后,服务端直接将结果返回。所以读取要比写入高效。
zookeeper读-写吞吐量
参考:
http://zookeeper.apache.org/doc/trunk/zookeeperOver.html











 京公网安备 11010802041100号
京公网安备 11010802041100号