从问题开始
先来抛一块砖,对于静态编译的应用程序,比如用C、C++、Golang或者其它的语言编写的程序,如果我们修改一个BUG或者添加一个新的特性后,如何在服务不下线的情况下更远应用程序呢?
抛出了一个问题,一个很平常的问题,有人对问题思考比较透彻,比如牛顿,被苹果砸中了之后,引起了很多的思考,最后发现了万有引力定律。

玩笑话一句,那我们如果被苹果砸中了会不死变成智障呢?

那么我们回到刚才这个问题 :
当我们修复BUG,添加新的需求后,如何如丝般顺滑地升级服务器应用程序,而不会中断服务?
这个问题意味着:
C / C++ / GO都是静态语言,所有的指令都编译在可执行文件,升级就意味着编译新的执行文件替换旧的执行文件,已经运行的进程如何加载新的image(可执行程序文件)去执行呢?
正在处理的业务逻辑不能中断,正在处理的连接不能暴力中断?
这种如丝般顺滑地升级应用程序,我们称之为热更新。
用个形象上的比喻表示就是:
你现在在坐卡车,卡车开到了150KM/H
然后,有个轮胎,爆了
然后,司机说,你就直接换吧,我不停车。你小心点换
哦,Lee哥,我明白了,在这些情况下,我们是不能使用哪个万能地“重启”去解决问题的。
第一种解决方案:灰度发布和A/B测试引起的思考
灰度发布(又名金丝雀发布)是指在黑与白之间,能够平滑过渡的一种发布方式。在其上可以进行A/B testing,即让一部分用户继续用产品特性A,一部分用户开始用产品特性B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B 上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。利用nginx做灰度发布的方案如下图:
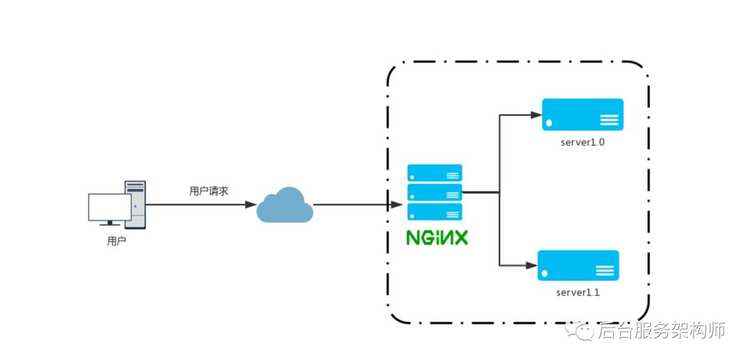
nginx是一个反向代理软件,可以把外网的请求转发到内网的业务服务器上,系统的分层的设计,一般我们把nginx归为接入层,当然LVS/F5/Apache等等都能去转发用户请求。比如我们来看一个nginx的配置:
http {
upstream cluster {
ip_hash;
server 192.168.2.128:8086 weight=1 fail_timeout=15 max_fails =3;
server 192.168.2.130:8086 weight=2 fail_timeout=15 max_fails =3;
}
server {
listen 8080;
location / {
proxy_pass http://cluster;
}
}
}
我们对8080端口的访问,都会转发到cluster说定义的upstream里,upstream里会根据IP hash的策略转发给192.168.2.128和192.168.2.130的8086端口的服务上。这里配置的是ip hash,当然nginx还支持其他策略。
那么通过nginx如何去如丝般升级服务程序呢?

比如nginx的配置:
http {
upstream cluster {
ip_hash;
server 192.168.2.128:8086 weight=1 fail_timeout=15 max_fails =3;
server 192.168.2.130:8086 weight=2 fail_timeout=15 max_fails =3;
}
server {
listen 80;
location / {
proxy_pass http://cluster;
}
}
}
假如我们的服务部署在192.168.2.128上,现在我们修复BUG或者增加新的特性后,我们重新部署了一台服务(比如192.168.2.130上),那么我们就可以修改nginx配置如上,然后执行nginx -s reload加载新的配置,这样我们现有的连接和服务都没有断掉,但是新的业务服务已经可以开始服务了,这就是通过nginx做的灰度发布,依据这样的方法做的测试称之为A/B测试,好了,那如何让老的服务彻底停掉呢?
可以修改nginx的配置如下,即在对应的upstream的服务器上添加down字段:
http {
upstream cluster {
ip_hash;
server 192.168.2.128:8086 weight=1 fail_timeout=15 max_fails =3 down;
server 192.168.2.130:8086 weight=2 fail_timeout=15 max_fails =3;
}
server {
listen 80;
location / {
proxy_pass http://cluster;
}
}
}
这样等过一段时间,就可以把192.168.2.128上的服务给停掉了。
这就是通过接入层nginx的一个如丝般顺滑的一个方案,这种思想同样可以应用于其他的比如LVS、apache等,当然还可以通过DNS,zookeeper,etcd等,就是把流量全都打到新的系统上去。
灰度发布解决的流量转发到新的系统中去,但是如果对于nginx这样的应用程序,或者我就是要在这台机器上升级image,那怎么办呢?这就必须要实现热更新,这里需要考虑的问题是旧的服务如果缓存了数据怎么办?如果正在处理业务逻辑怎么办?
第二种解决方案:nginx的热更新方案
nginx采用Master/Worker的多进程模型,Master进程负责整个nginx进程的管理,比如停机、日志重启和热更新等等,worker进程负责用户的请求处理。
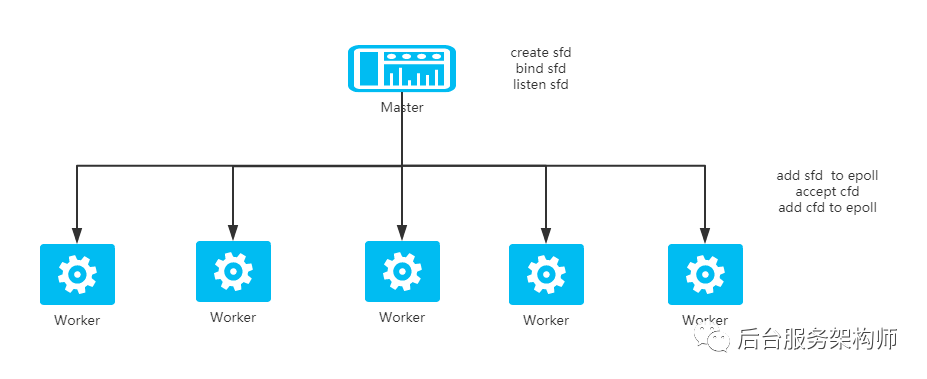
如上一个nginx里配置的所有的监听端口都是首先在Master进程里create的socket(sfd)、bind、listen,然后Master在创建worker进程的时候把这些socket通过unix domain socket复制给了Worker进程,Worker进程把这些socket全都添加到epoll,之后如果有客户端连接进来了,则由worker进程负责处理,那么也就是说用户的请求是由worker进程处理的。
先交代了nginx的IO处理模型的背景,然后我们再看nginx的热更新方案:
升级的步骤:
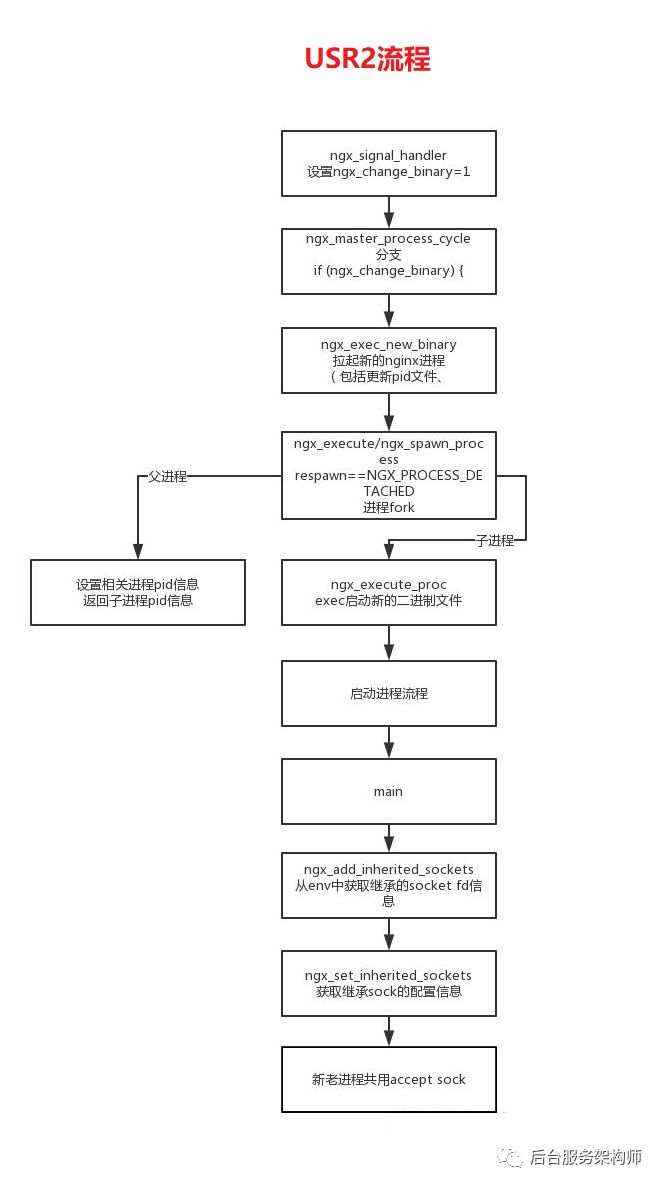
第一步:升级nginx二进制文件,需要先将新的nginx可执行文件替换原有旧的nginx文件,然后给nginx master进程发送USR2信号,告知其开始升级可执行文件;nginx master进程会将老的pid文件增加.oldbin后缀,然后调用exec函数拉起新的master和worker进程,并写入新的master进程的pid。
UID PID PPID C STIME TTY TIME CMD
root 4584 1 0 Oct17 ? 00:00:00 nginx: master process /usr/local/apigw/apigw_nginx/nginx
root 12936 4584 0 Oct26 ? 00:03:24 nginx: worker process
root 12937 4584 0 Oct26 ? 00:00:04 nginx: worker process
root 12938 4584 0 Oct26 ? 00:00:04 nginx: worker process
root 23692 4584 0 21:28 ? 00:00:00 nginx: master process /usr/local/apigw/apigw_nginx/nginx
root 23693 23692 3 21:28 ? 00:00:00 nginx: worker process
root 23694 23692 3 21:28 ? 00:00:00 nginx: worker process
root 23695 23692 3 21:28 ? 00:00:00 nginx: worker process
关于exec家族的函数说明见下:
NAME
execl, execlp, execle, execv, execvp, execvpe - execute a file
SYNOPSIS
#include
extern char **environ;
int execl(const char *path, const char *arg, ...
/* (char *) NULL */);
int execlp(const char *file, const char *arg, ...
/* (char *) NULL */);
int execle(const char *path, const char *arg, ...
/*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],
char *const envp[]);
Feature Test Macro Requirements for glibc (see feature_test_macros(7)):
execvpe(): _GNU_SOURCE
DESCRIPTION
The exec() family of functions replaces the current process image with a new process image. The functions described in this manual page are front-ends for execve(2).
(See the manual page for execve(2) for further details about the replacement of the current process image.)
The initial argument for these functions is the name of a file that is to be executed.
The const char *arg and subsequent ellipses in the execl(), execlp(), and execle() functions can be thought of as arg0, arg1, ..., argn. Together they describe a list
of one or more pointers to null-terminated strings that represent the argument list available to the executed program. The first argument, by convention, should point
to the filename associated with the file being executed. The list of arguments must be terminated by a null pointer, and, since these are variadic functions, this
pointer must be cast (char *) NULL.
The execv(), execvp(), and execvpe() functions provide an array of pointers to null-terminated strings that represent the argument list available to the new program.
The first argument, by convention, should point to the filename associated with the file being executed. The array of pointers must be terminated by a null pointer.
The execle() and execvpe() functions allow the caller to specify the environment of the executed program via the argument envp. The envp argument is an array of point‐
ers to null-terminated strings and must be terminated by a null pointer. The other functions take the environment for the new process image from the external variable
environ in the calling process.
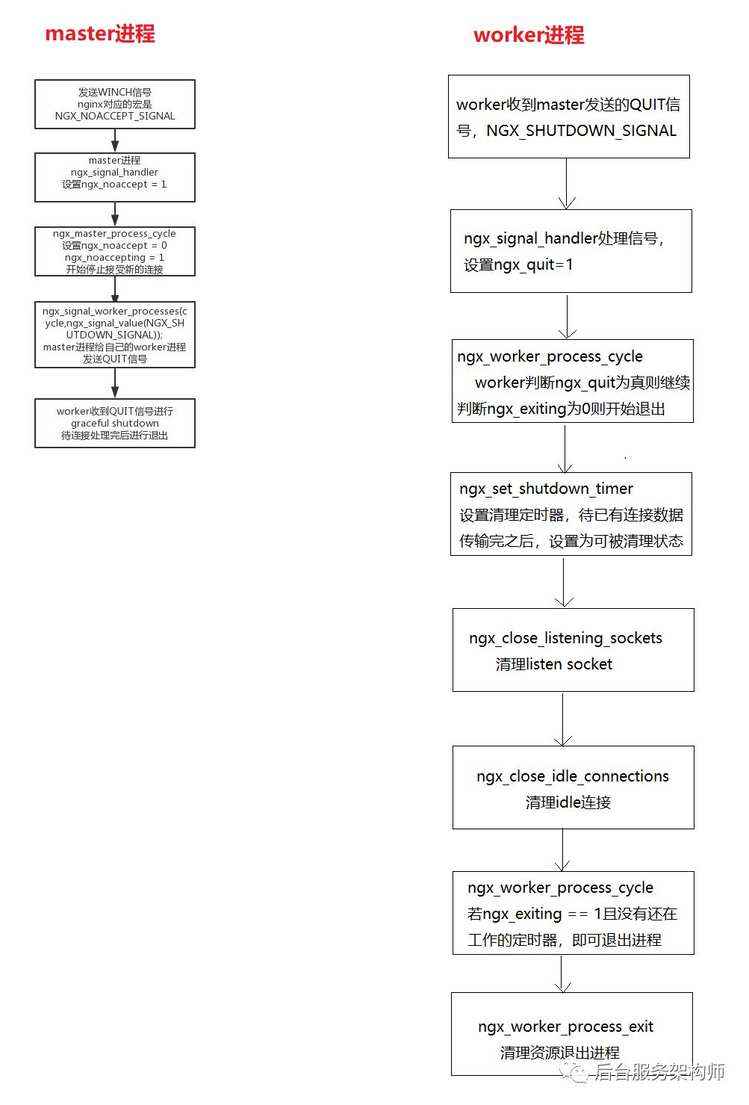
第二步:在此之后,所有工作进程(包括旧进程和新进程)将会继续接受请求。这时候,需要发送WINCH信号给nginx master进程,master进程将会向worker进程发送消息,告知其需要进行graceful shutdown,worker进程会在连接处理完之后进行退出。
UID PID PPID C STIME TTY TIME CMD
root 4584 1 0 Oct17 ? 00:00:00 nginx: master process /usr/local/apigw/apigw_nginx/nginx
root 12936 4584 0 Oct26 ? 00:03:24 nginx: worker process
root 12937 4584 0 Oct26 ? 00:00:04 nginx: worker process
root 12938 4584 0 Oct26 ? 00:00:04 nginx: worker process
root 23692 4584 0 21:28 ? 00:00:00 nginx: master process /usr/local/apigw/apigw_nginx/nginx
如果旧的worker进程还需要处理连接,则worker进程不会立即退出,需要待消息处理完后再退出。
第三步:经过一段时间之后,将会只会有新的worker进程处理新的连接。
注意,旧master进程并不会关闭它的listen socket;因为如果出问题后,需要回滚,master进程需要法重新启动它的worker进程。
第四步:如果升级成功,则可以向旧master进程发送QUIT信号,停止老的master进程;如果新的master进程(意外)退出,那么旧master进程将会去掉自己的pid文件的.oldbin后缀。
几个核心的步骤和命令说明如下:
master进程相关信号
USR2 升级可执行文件
WINCH 优雅停止worker进程
QUIT 优雅停止master进程
worker进程相关信号
TERM, INT 快速退出进程
QUIT 优雅停止进程
如何启动新的的image:
好了,以上就是zero down-time update的一些方案,如果还有不明白可以看下面这个视频。
https://www.bilibili.com/video/av57429199




![基于Linux开源VOIP系统LinPhone[四]](https://img.php1.cn/3cd4a/1eebe/cd5/ed19db63ee478b98.png)


 京公网安备 11010802041100号
京公网安备 11010802041100号