用java模拟词频统计。
有3个文件:text1: hello world
text2:hello hadoop
text3:hello mapreduce
对上面的文件进行词频统计:结果应该是:hello:3; hadoop:1; world:1; mapreduce:1
代码实现如下:
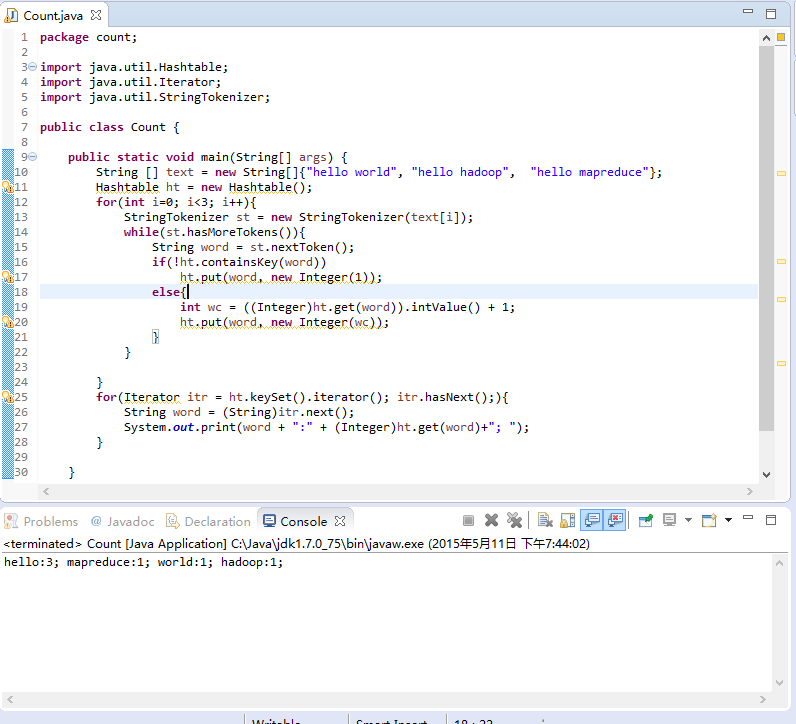
package count;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.StringTokenizer;
public class Count {
public static void main(String[] args) {
String [] text = new String[]{"hello world", "hello hadoop", "hello mapreduce"};
Hashtable ht = new Hashtable();
for(int i&#61;0; i<3; i&#43;&#43;){
StringTokenizer st &#61; new StringTokenizer(text[i]);
while(st.hasMoreTokens()){
String word &#61; st.nextToken();
if(!ht.containsKey(word))
ht.put(word, new Integer(1));
else{
int wc &#61; ((Integer)ht.get(word)).intValue() &#43; 1;
ht.put(word, new Integer(wc));
}
}
}
for(Iterator itr &#61; ht.keySet().iterator(); itr.hasNext();){
String word &#61; (String)itr.next();
System.out.print(word &#43; ":" &#43; (Integer)ht.get(word)&#43;"; ");
}
}
}








 京公网安备 11010802041100号
京公网安备 11010802041100号