作者:cutepingge | 来源:互联网 | 2023-05-17 21:44
安装spark(单机环境)
cd /soft
tar -zxvf spark-2.2.1-bin-hadoop2.7.tgz -C /usr/local/
/usr/local/spark-2.2.1-bin-hadoop2.7
环境变量:
echo "export SPARK_HOME=/usr/local/spark-2.2.1-bin-hadoop2.7" >> /etc/profile
echo -e 'export PATH=$PATH:$SPARK_HOME/bin'>> /etc/profile
source /etc/profile
对/usr/local/spark-2.2.1-bin-hadoop2.7/conf目录下的文件进行配置:
cd /usr/local/spark-2.2.1-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
编辑spark-env.sh:vim /usr/local/spark-2.2.1-bin-hadoop2.7/conf/spark-env.sh
添加:
export SCALA_HOME=/usr/local/scala-2.12.4
export JAVA_HOME=/usr/java/jdk1.8.0
export SPARK_HOME=/usr/local/spark-2.2.1-bin-hadoop2.7
export SPARK_MASTER_IP=node1
export SPARK_EXECUTOR_MEMORY=250m
export SPARK_WORKER_MEMORY=250m
编辑slaves:vim /usr/local/spark-2.2.1-bin-hadoop2.7/conf/slaves
里面的内容设置为:
localhost
进入到主目录,也就是执行下面的命令:
cd /usr/local/spark-2.2.1-bin-hadoop2.7
执行命令运行计算圆周率的Demo程序:
/usr/local/spark-2.2.1-bin-hadoop2.7/./bin/run-example SparkPi 10
执行命令,启动脚本:
/usr/local/spark-2.2.1-bin-hadoop2.7/./bin/spark-shell

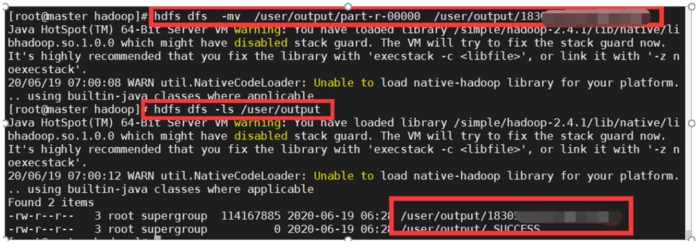




 京公网安备 11010802041100号
京公网安备 11010802041100号