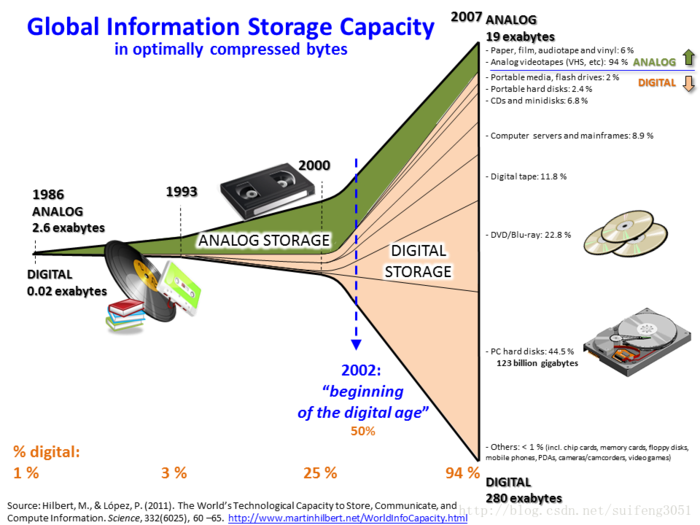
1.2 信息技术发展带来的数据爆炸
- 纽约证券所交易 每天 1TB
- FaceBook一千亿照片 1PB
- 腾讯 每天 300TB
- 淘宝 每天 pv20亿 数据量 50TB
- ......
1.3 数据存储与分析
问题:数据量指数添加,磁盘訪问速度未能与时俱进
- 1990 年 一个磁盘 1370MB 速度4.4MB/s 用时5分钟
- 2010 年 一个磁盘 1TB 速度 100MB/s 用时两个半
分析:读一个非常慢。那么能够同一时候读多个
- 假设把1TB存储到100个磁盘,每一个存储1%。并行读取,用时不到两分钟。
- 假设一个我们有100个1TB数据集,100个1TB磁盘,那么我们以磁盘共享的方式把每一个数据集分布到100个磁盘中,这样边会大大提高每一个数据集的读取速率。
假设实现此类文件系统须要解决哪些问题?
- 硬盘故障:由于文件系统有多个磁盘,那么随意一个磁盘发生问题的概率就变得非常高。(採取数据备份)
- 数据分析:某些分析任务须要结合大部分数据共同完毕,那么我们的文件系统就要保证对来自多个数据源的数据进行分析的准确性。
1.4 Hadoop-一个可靠的分布式共享存储和分析系统
简要介绍:Hadoop 是Apache基金会下一个开源的分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心。为用户提供了系统底层细节透明的分布式基础架构。
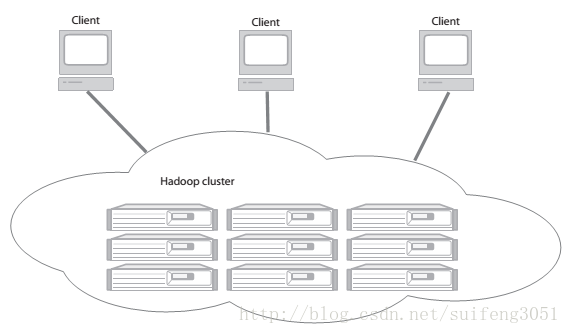
如上图Hadoop集群中有非常多并行的机器来存储和分析数据,client把任务提交到集群。集群计算返回结果。
历史起源:Apache的子项目的子项目
雄心勃勃的Doug Cutting:他先领导创立了Apache的项目Lucene,然后Lucene又衍生出子项目Nutch,Nutch又衍生了子项目Hadoop。Lucene是一个功能全面的文本搜索和查询库,Nutch目标就是要视图以Lucene为核心建立一个完整的搜索引擎,而且能达到提到Google商业搜索引擎的目标。
网络搜索引擎和基本文档搜索差别就在规模上,Lucene目标是索引数百万文档,而Nutch应该能处理数十亿的网页。
因此Nutch就面临了一个极大的挑战,即在Nutch中建立一个层。来负责分布式处理、冗余、故障恢复及负载均衡等等一系列问题。
。。
曙光的到来:2004年,Google发表了两篇论文来论述Google文件系统(GFS)和MapReduce框架,而且使用了这两项技术来拓展自己的搜索系统,于是Doug Cutting看到了这两篇论文的价值并带领他的团队便实现了这个框架,并将Nutch移植上去,于是Nutch的可扩展性得到极大的提高。
Hadoop的诞生:Doug Cutting逐渐认识到急须要成立一个专门的项目来充实这两种技术。于是就诞生了Hadoop。
2006年1月,雅虎雇佣Doug Cutting。并让他和一个专门的团队来一起改进Hadoop。并将其作为一个开源项目。
2008年2月19日,雅虎正式宣布。其索引网页的生产系统採用的就是在10000多个核的Linux系统上执行的Hadoop。
ps:关于Doug Cutting它三个项目的名字由来。这个人非常有意思,三个项目的名字都来源于他家庭,Lucene是他妻子的中间名也是她外祖母的名字,他儿子在非常小的时候总是把吃饭的词叫做Nutch,后来,他又把一个黄色大象毛绒玩具叫做Hadoop,这样大家就明确了为何好多关于Hadoop的资料中都能看到个黄色的大象。
长处:Hadoop是一个开源框架,可编写和执行分布式应用来处理大规模数据,分布式计算是一个不断变化且宽泛的领域,长处例如以下:
1.易用性。Hadoop执行在由一般商用机器构成的大型集群上。
2.可靠性。Hadoop致力于一般商用机器上。其架构如果硬件会频繁出现失效,它能够从容处理大多数此类故障。
3.可扩展。Hadoop通过添加集群节点。能够线性地拓展以处理更大数据集。
4.简单。Hadoop同意用户高速的编写出高效地并行代码。
了解分布式系统和Hadoop:
摩尔定律:当价格不变时,集成电路上可容纳的晶体管数目。约每隔18个月便会添加一倍,性能也将提升一倍,但解决大规模数据计算问题不能单纯依赖制造越来越大型的server。
分布式系统(向外拓展scale-out)与大型server(向上拓展scale-up),从IO性价比层面分析:
一个四IO通道的高端机。每一个通道的吞吐量各为100MB/sec,读取4TB数据也要接近3小时,而用Hadoop。相同的数据被划分为较小的块(通常为64MB)。通过HDFS分不到群内的多台计算机上,集群能够并行存取数据,这样。一组通用的计算机比一台高端机要廉价。
Hadoop与其他分布式系统比較,如SETI@home,它的一台中间server存储了来自太空的无线电信号。并把这些信号数据发给分布在世界各地的client计算,再将计算返回的结果存储起来。
Hadoop对待数据的理念与其不同。SETI@home须要server和client反复地数据传输。这样的方式在处理密集数据时。会使得数据迁移变得十分困难。
而Hadoop则强调把代码向数据迁移,即Hadoop集群中既包括数据又包括运算环境,而且尽可能让一段数据的计算发生在同一台机器上,代码比数据更加easy移动。Hadoop的设计理念即是把要运行的计算代码移动到数据所在的机器上去。
比較Hadoop和SQL数据库
从整体上看,如今大多数数据应用处理的主力是关系型数据库,即SQL面向的是结构化的数据。而Hadoop则针对的是非结构化的数据,从这一角度看,Hadoop提供了对数据处理的一种更为通用的方式。
以下。我们从特定的视角将Hadoop与SQL数据库做具体比較:
1. 用scale-out取代scale-up
拓展商用server的代价是很昂贵的。要执行一个更大的数据库,就要一个更大的server,其实,各server厂商往往会把其昂贵的高端机标称为“数据库级server”。只是有时候有可能须要处理更大的数据集,但却找不到更大的机器,而更为重要的是。高端机对于很多应用并不经济。
2.用键值对取代关系表
关系型数据库须要将数据依照某种模式存放到具有关系型数据结构表中,可是很多当前的数据模型并不能非常好的适应这些模型。如文本、图片、xml等。此外,大型数据集往往是非结构化或半结构化的。而Hadoop以键值对作为最主要的数据单元,可以灵活的处理较少结构化的数据类型。
3.用函数式编程(MapReduce)取代声明式查询(SQL)
SQL从根本上说是一个高级声明式语言。它的手段是声明你想要的结果。并让数据库引擎推断怎样获取数据。而在MapReduce程序中,实际的数据处理步骤是由你指定的。
SQL使用查询语句,而MapReduce使用程序和脚本。MapReduce还能够建立复杂的数据统计模型,或者改变图像数据的处理格式。
4.用离线批量处理取代在线处理
Hadoop并不适合处理那种对几条记录读写的在线事务处理模式。而适合一次写入多次读取的数据需求。
1.5 理解MapReduce
或许你知道管道和消息队列数据处理模型,管道有助于进程原语的重用,用已有模块的简单连接就可组成一个新的模块。消息队列则有助于进程原语的同步。
相同,MapReduce也是一种数据处理模型 。它的最大的特点就是easy拓展到多个计算机节点上处理数据。在MapReduce中,原语通常被称作Mapper和Reducer。
或许讲一个数据处理应用分解为一个Mapper和Reducer是很繁琐的,可是一旦你写好了一个Mapreduce应用程序,仅需通过配置,就可将其拓展到集群的成百上千个节点上执行,这样的简单的可拓展性使得Mapreduce吸引了大量程序猿。
手动拓展一个简单单词计数程序
统计一个单词的出现次数。单词仅仅有一句话:"do as i say , not as i do"。
假设文档非常小。一段简单的代码就可以实现,以下是一段伪代码:
define wordCount as Multiset;
for each document in documentSet {
T = tokenize(document);
for each token in T {
wordCount[token]++;
}
}
display(wordCount);
可是这个程序仅仅适合处理少了文档,我们试着重敲代码。使它能够分布在多个计算机上,每台机器处理文档的不同部分,在把这些机器处理的结果放到第二阶段。由第二阶段来合并第一阶段的结果。
第一阶段要分布到多台机器上的代码为:
defi ne wordCount as Multiset;
for each document in documentSet {
T = tokenize(document);
for each token in T {
wordCount[token]++;
}
}
sendToSecondPhase(wordCount);
第二阶段伪代码:
defi ne totalWordCount as Multiset;
for each wordCount received from firstPhase { multisetAdd (totalWordCount, wordCount); }
假设这么设计的话还有什么其它困难吗?一些细节可能会妨碍它按预期工作,
1.假设数据集非常大,中心存储server性能可能会跟不上,因此我们须要把文档分不到多台机器上存储。
2.另一个缺陷是wordcount被存放在内存其中,相同,假设数据集非常大一个wordcount就有可能超过内存容量,因此我们不能将其放在内存中,我们需实现一个基于磁盘的散列表。其中当然涉及大量编码。
3.第二阶段假设仅仅有一台计算机。显然不太合理。若依照第一阶段的设计把第二阶段的任务也分布到多台计算机上呢?答案当然是能够的,可是我们必须将第一阶段的结果按某种方式分区。使其每一个分区能够独立执行在第二阶段的各个计算机上。
比方第二阶段的A计算机仅仅统计以a开头的wordcount,计算机B统计wordcount-b分区,依次类推。
如今这个单词统计程序正在变得复杂,为了使它可以执行在一个分布式计算机集群中,我们发现须要加入下面功能:
1. 存储文件到多台计算机上
2.编写一个基于磁盘的散列表,使其不受计算机内存限制
3.划分来自第一阶段的中间数据
4.洗牌第一阶段分区到第二阶段合适的计算机上
只这一个简单的小问题就须要考虑这么多细节处理,这就是我们为什么须要一个Hadoop框架,当我们用MapReduce模型编敲代码时,Hadoop框架能够管理全部与可拓展性相关的底层问题。
同样程序在MapReduce中拓展
Map和Reduce程序必须遵循下面键和值类型的约束
1.应用的输入必须组织为一个键值对列表List
,输入格式不受约束。比如处理多个文件的输入格式能够使List。
2.含键值对的列表被拆分。进而通过调用Mapper的Map函数对每一个键值对
进行处理,Mapper 转换每一个,并将其结果并入。
在上面样例中,Mapper转换成的是一个的列表。
3.全部Mapper的输出被聚合在一个巨大的列表中,全部共享K2的对被组织在一起成为一个新的键值对列表,让reducer来处理每个聚合起来的,并将处理转换成。MapReduce框架自己主动搜索全部并将其写入文件里。
1.6 执行第一个Hadoop程序——用Hadoop框架来统计单词
在linux环境下配置Hadoop执行环境
首先安装JAVA JDK
Hadoop须要1.6或更高版本号
1.到oracle官网下载Linux版java安装包(rpm包)
2.查看是否已安装:java or java -version
3.卸载老版本号 rpm -e jdk
4.安装jdk rpm -ivh jdk
5.配置环境变量
下载一个Hadoop稳定版本号
# mkdir /usr/hadoop
# cd /usr/hadoop/
# wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
# tar -xzf hadoop-1.2.1.tar.gz
# mv hadoop-1.2.1 hadoop
# cd /usr/hadoop/hadoop/
# bin/hadoop
配置 Hadoop
First edit hadoop configuration files and make following changes.
Edit core-site.xml
# vim conf/core-site.xml
#Add the following inside the configuration tag
fs.default.name
hdfs://localhost:9000/
dfs.permissions
false
Edit hdfs-site.xml
# vim conf/hdfs-site.xml
# Add the following inside the configuration tag
dfs.data.dir
/opt/hadoop/hadoop/dfs/name/data
true
dfs.name.dir
/opt/hadoop/hadoop/dfs/name
true
dfs.replication
2
Edit mapred-site.xml
# vim conf/mapred-site.xml
# Add the following inside the configuration tag
mapred.job.tracker
localhost:9001
Edit hadoop-env.sh
# vim conf/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.7.0_17
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
Set JAVA_HOME path as per your system configuration for java.
Next to format Name Node
$ cd /usr/hadoop/hadoop
$ bin/hadoop namenode -format
启动 Hadoop Services
Use the following command to start all hadoop services.
$ bin/start-all.sh
输入网址查看一下效果:
http://localhost:50030(MapReduce 的web页面)
http://localhost:50070(HDFS 的web页面)
1.7 Setting up SSH for a Hadoop cluster
安装Hadoop集群时须要一个server做主节点,常驻NameNode和JobTracker进程,也将作为一个基站,负责联络并激活从节点上的DataNode和TaskTracker守护进程。
因此我们须要为主节点定制一种手段,使他能够訪问到集群中的每一个节点。
为此,Hadoop使用无口令的SSH协议。SSH採用标准公钥加密来生成一对用户验证秘钥,私钥存储到主节点,公钥存储到从节点。
定义一个公共账号
我们所从一个节点訪问还有一个节点的说法一直被作为通用语言使用。事实上更详细的说法应该是从一个账户訪问还有一个账户。对于在Hadoop集群中的全部节点都应该有同样的账户,为了安全考虑,建议把这些账户级别设置为用户级别。
验证SSH安装
使用Linux的which命令
which ssh
which sshd
which ssh-keygen
生成ssh秘钥对
未完待续。。。







 京公网安备 11010802041100号
京公网安备 11010802041100号