作者:澄墙_168 | 来源:互联网 | 2023-08-28 12:04
一、背景
使用Python,打通Impala通道,实现取数自动化,或是作为数据分析的数据源。
二、Apache Impala
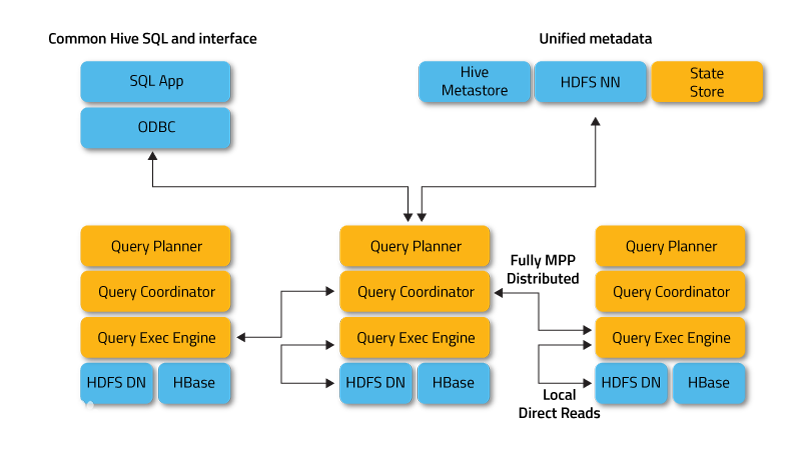
Impala是一个开源的,基于Hadoop的分析型数据库。
Impala可以查询存储在HDFS或者HBase中的数据。
Impala通过专用分布式查询引擎,绕过MapReduce直接访问数据,查询性能远高于Hive。
三、impyla
基于HiveServer2 实现的分布式查询引擎(如Impala、Hive)的Python客户端。
完全符合DB API 2.0(PEP 249)规范。
使用Kerberos、LDAP、SSL。
支持将数据转换为pandas的DataFrame,轻松集成到Python数据栈(如scikit-learn、matplotlib等)。
四、类封装
from impala.dbapi import connect
from impala.error import ProgrammingError
from utils.db.sql import SQLclass Impala(SQL):DESC_EXEC_SUCCESS = "执行成功"def __init__(self, host, port, database, user, password=None):"""Impala工具类:param host: IP:param port: 端口:param database: 数据库名:param user: 用户名:param password: 密码"""self.host = hostself.port = portself.database = databaseself.user = userself.password = passwordself.cOnnect= Noneself.cursor = Nonedef get_connect(self, timeout=600):"""获取连接:param timeout: 超时时间"""self.cOnnect= connect(host=self.host, # IP port=self.port, # 端口timeout=timeout, # 超时时间database=self.database # 数据库名)def get_cursor(self):"""获取游标"""self.cursor = self.connect.cursor(user=self.user # 用户名)def close(self):"""关闭连接"""self.cursor.close()self.connect.close()self.cursor = Noneself.cOnnect= Nonedef execute(self, sql, auto_close=True):"""执行sql:param auto_close: 执行结束是否自动关闭连接"""if not self.connect: self.get_connect()if not self.cursor: self.get_cursor()self.cursor.execute(sql)try:result = self.cursor.fetchall()except ProgrammingError:result = self.DESC_EXEC_SUCCESSif auto_close: self.close()return result
五、使用例子
from utils.db.impala import Impalaimpala = Impala(host="10.123.0.11",port=123456,database="fields",user="unclebean"
)
sql = "select 1 as a, 2 as b union all select 3 as a, 4 as b"
result = impala.execute(sql, auto_close=True)
print(result)
默认的返回结果是一个列表,列表中每个元素代表一行结果,类型为元组,如上面返回的结果:[(1, 2), (3, 4)]
若想行结果变为字典,而非元组,则获取游标时需传入参数dictify=True,如
sql = "select 1 as a, 2 as b union all select 3 as a, 4 as b"
result = impala.execute(sql, auto_close=True, dictify=True)
print(result)
则返回结果变为:[{'a': 1, 'b': 2}, {'a': 3, 'b': 4}]
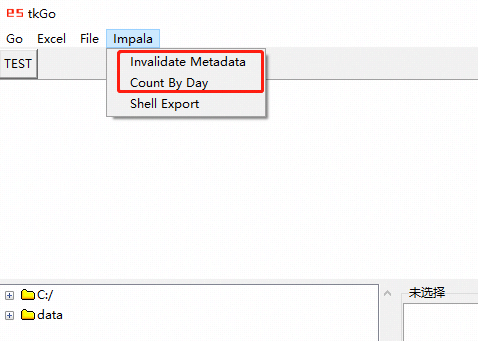
六、tkinter封装,实现一键刷新元数据和按日统计数据量
import os
from datetime import datetime
from menu.menu import EMenu
from utils.db.impala import Impalaclass MenuImpala(EMenu):LABEL_NAME = "Impala"LABEL_NAME_INVALIDATE_METADATA = "Invalidate Metadata"LABEL_NAME_COUNT_BY_DAY = "Count By Day"DESC_SSH_CMD_FAILED = "执行错误"def __init__(self, master=None, cnf={}, **kw):super().__init__(master=master, cnf=cnf, **kw)self.impala = Impala(host = self.conf.impala.HOST,port = self.conf.impala.PORT,database = self.conf.impala.DATABASE,user = self.conf.impala.USER)master.add_cascade(label=self.LABEL_NAME, menu=self) # 添加主菜单self.add_command( # 添加子菜单-刷新元数据label=self.LABEL_NAME_INVALIDATE_METADATA, command=self.invalidate_metadata)self.add_command( # 添加子菜单-按日统计数据量label=self.LABEL_NAME_COUNT_BY_DAY, command=self.count_by_day)@EMenu.thread_run(LABEL_NAME_COUNT_BY_DAY)def count_by_day(self):"""菜单命令:按日统计数据量"""table_name = self.get_table_name_from_clip() # 从剪贴板中获取表名self.invalidate_table(table_name, auto_close=False) # 先刷新元数据sql = "select data_date,count(1) from {} group by data_date order by data_date desc".format(table_name)self.stdout(sql, with_time=" - ")result = self.impala.execute(sql) # 再按日统计数据量result = "\n".join([str(row) for row in result])self.stdout("{} -> {}".format(sql, result), with_time=" - ")self.msg_box_info(result)@EMenu.thread_run(LABEL_NAME_INVALIDATE_METADATA)def invalidate_metadata(self):"""菜单命令:刷新元数据"""self.invalidate_table(self.get_table_name_from_clip()) # 从剪贴板中获取表名,然后刷新元数据def invalidate_table(self, table_name, auto_close=True):sql = "invalidate metadata {}".format(table_name)self.stdout(sql, with_time=" - ")result = self.impala.execute(sql=sql, auto_close=auto_close)self.stdout("{} -> {}".format(sql, result), with_time=" - ")def get_table_name_from_clip(self):table_name = self.paste()if len(table_name.split(".")) == 1: table_name = table_name.split("_")[0] + "." + table_namereturn table_name
七、完整代码
GitHub上搜索TheUncleWhoGrowsBeans










 京公网安备 11010802041100号
京公网安备 11010802041100号