摘要: 2017年深度学习框架关注度排名tensorflow以绝对的优势占领榜首,本文通过一个小例子介绍了TensorFlow在时序预测上的应用。
TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
时间序列分析在计量经济学和财务分析中具有重要意义,但也可以应用于了解趋势做决策和对行为模式的变化做出反应的领域。其中例如,作为主要石油和天然气供应商的MapR融合数据平台客户将传感器放在井上,将数据发送到MapR Streams,然后将其用于趋势监测井的状况,如体积和温度。在金融方面,时间序列分析用于股票价格,资产和商品的价格的预测。计量经济学家长期利用“差分自回归移动平均模型”(ARIMA)模型进行单变量预测。
ARIMA模型已经使用了几十年,并且很好理解。然而,随着机器学习的兴起,以及最近的深度学习,其他模式正在被探索和利用。
深度学习(DL)是基于一组算法的机器学习的分支,它通过使用由多个非线性变换组成的人造神经网络(ANN)架构来尝试对数据进行高级抽象然后建模。更为流行的DL神经网络之一是循环神经网络(RNN)。RNN是依赖于其输入的顺序性质的一类神经网络。这样的输入可以是文本,语音,时间序列,以及序列中的元素的出现取决于在它之前出现的元素。例如,一句话中的下一个字,如果有人写“杂货”最有可能是“商店”而不是“学校”。在这种情况下,给定这个序列,RNN可能预测是商店而不是学校。
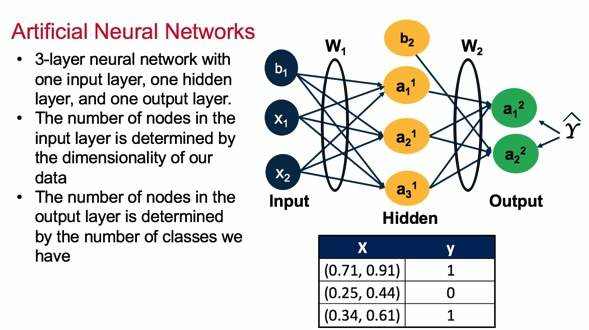
人工神经网络
实际上,事实证明,虽然神经网络有时是令人畏惧的结构,但使它们工作的机制出奇地简单:随机梯度下降。对于我们网络中的每个参数(如权重或偏差),我们所要做的就是计算相对于损耗的参数的导数,并在相反方向微调一点。
ANNs使用称为反向传播(有想了解BP算法的可以参考BP算法双向传,链式求导最缠绵)的方法来调整和优化结果。反向传播是一个两步过程,其中输入通过正向传播馈送到神经网络中,并且在通过激活函数变换之前与(最初随机的)权重和偏差相乘。你的神经网络的深度将取决于你的输入应该经过多少变换。一旦正向传播完成,反向传播步骤通过计算产生误差的权重的偏导数来调整误差。一旦调整权重,模型将重复正向和反向传播步骤的过程,以最小化误差率直到收敛。下图中你看到这是一个只有一个隐藏层的ANN,所以反向传播不需要执行多个梯度下降计算。
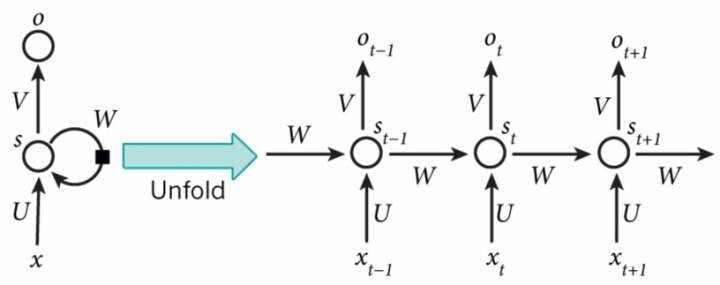
循环神经网络
循环神经网络(RNN)被称为循环是因为它们对输入序列中的所有元素执行相同的计算。由于RNN的广泛应用,RNN正在变得非常受欢迎。它们可以分析时间序列数据,如股票价格,并提供预测。在自动驾驶系统中,他们可以预测汽车轨迹并帮助避免事故。他们可以将句子,文档或音频样本作为输入,它们也可以应用于自然语言处理(NLP)系统,如自动翻译,语音对文本或情感分析。
上图是RNN架构的示例,并且我们看到xt是时间步长t的输入。例如,x1可能是时间段1中的股票的第一个价格。st是在时间步长tn处的隐藏状态,并且使用激活函数基于先前的隐藏状态和当前步骤的输入来计算。St-1通常被初始化为零。ot是步骤t的输出。例如,如果我们想预测序列中的下一个值,那么它将是我们时间序列中概率的向量。
RNN隐藏层的成长是依赖于先前输入的隐藏状态或记忆,捕获到目前为止所看到的内容。任何时间点的隐藏状态的值都是前一时间步骤中的隐藏状态值和当前时间的输入值进行函数计算的结果。RNN具有与ANN不同的结构,并且通过时间(BPTT)使用反向传播来计算每次迭代之后的梯度下降。
一个小例子:
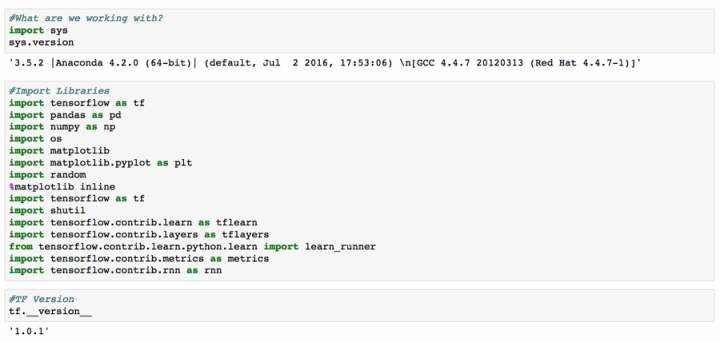
此示例使用3个节点的小型MapR群集完成。此示例将使用以下内容:
- Python 3.5
- TensorFlow 1.0.1
- Red Hat 6.9
如果你使用Anaconda&#xff0c;你需要保证你能够安装TensorFlow 1.0.1版本在你本地的机器上。此代码将不能在TensorFlow <1.0版本上使用。如果TensorFlow版本相同&#xff0c;则可以在本地机器上运行并传输到集群。其他需要考虑的深度学习库是MXNet&#xff0c;Caffe2&#xff0c;Torch和Theano。Keras是另一个为TensorFlow或Theano提供python包的深度学习库。
MapR提供了用户喜好的集成Jupyter Notebook&#xff08;或Zeppelin&#xff09;的功能。我们将在这里显示的是数据管道的尾端。在分布式环境中运行RNN时间序列模型的真正价值是你可以构建的数据流水线&#xff0c;将聚合的系列数据推送到可以馈送到TensorFlow计算图中的格式。
如果我正在聚合来自多个设备&#xff08;IDS&#xff0c;syslogs等&#xff09;的网络流&#xff0c;并且我想预测未来的网络流量模式行为&#xff0c;我可以使用MapR Streams建立一个实时数据管道&#xff0c;将这些数据聚合成一个队列&#xff0c;进入我的TensorFlow模型。对于这个例子&#xff0c;我在集群上只使用一个节点&#xff0c;但是我可以在其他两个节点上安装TensorFlow&#xff0c;并且可以有三个TF模型运行不同的超参数。
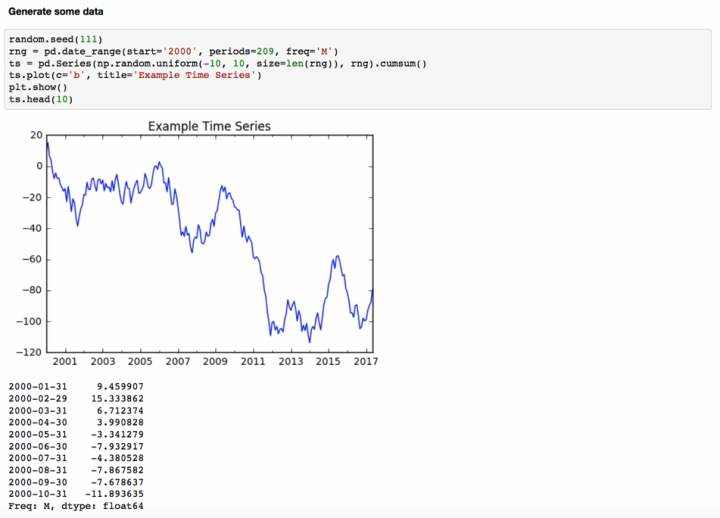
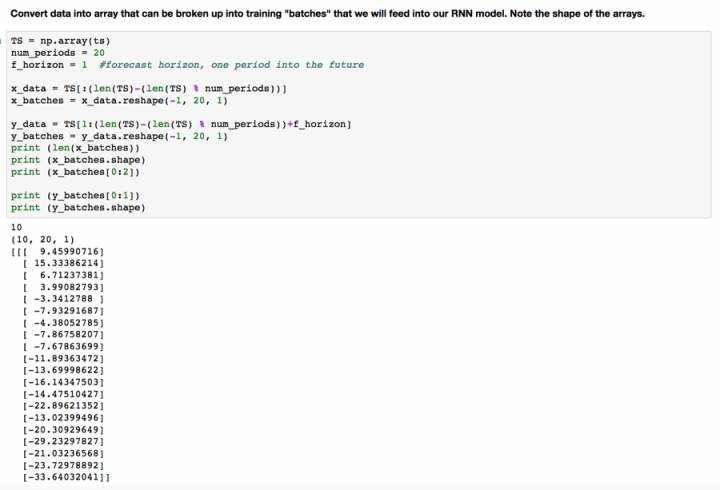
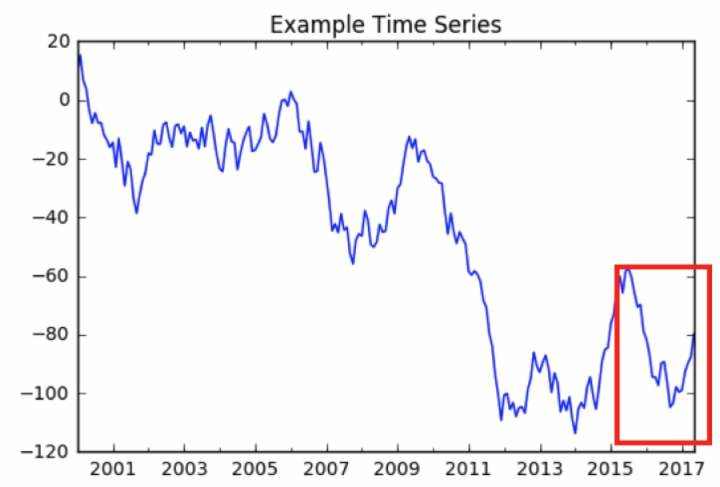
对于这个例子&#xff0c;我生成了一些虚拟数据。
我们在我们的数据中有209个观察结果。我want确保我对每个批次输入都有相同的观察次数。
我们看到的是我们的训练数据集由10个批次组成&#xff0c;包含20个观测值。每个观察值是单个值的序列。
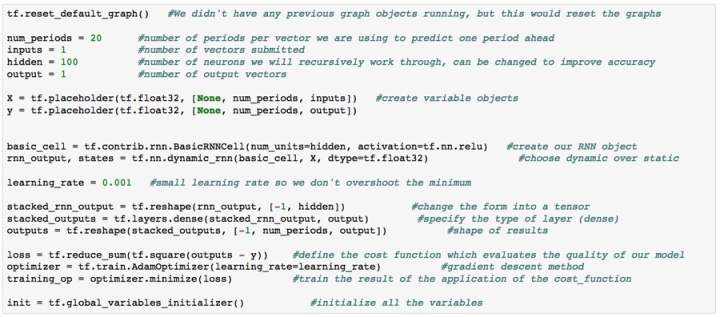
现在我们有了我们的数据&#xff0c;我们来创建一个将执行计算的TensorFlow图。
这里有很多事情需要处理。例如我们正在指定我们用来预测的周期数。我们指定我们的变量占位符。我们初始化一种使用的RNN单元格&#xff08;大小100&#xff09;和我们想要的激活函数的类型。ReLU代表“整流线性单元”&#xff0c;是默认的激活功能&#xff0c;但如果需要&#xff0c;可以更改为Sigmoid&#xff0c;Hyberbolic Tangent&#xff08;Tanh&#xff09;等。
我们希望我们的输出与我们的输入格式相同&#xff0c;我们可以使用损失函数来比较我们的结果。在这种情况下&#xff0c;我们使用均方误差&#xff08;MSE&#xff09;&#xff0c;因为这是一个回归问题&#xff0c;我们的目标是最小化实际和预测之间的差异。如果我们处理分类结果&#xff0c;我们可能会使用交叉熵。现在我们定义了这个损失函数&#xff0c;可以定义TensorFlow中的训练操作&#xff0c;这将优化我们的输入和输出网络。要执行优化&#xff0c;我们将使用Adam优化器。Adam优化器是一个很好的通用优化器&#xff0c;可以通过反向传播实现渐变下降。
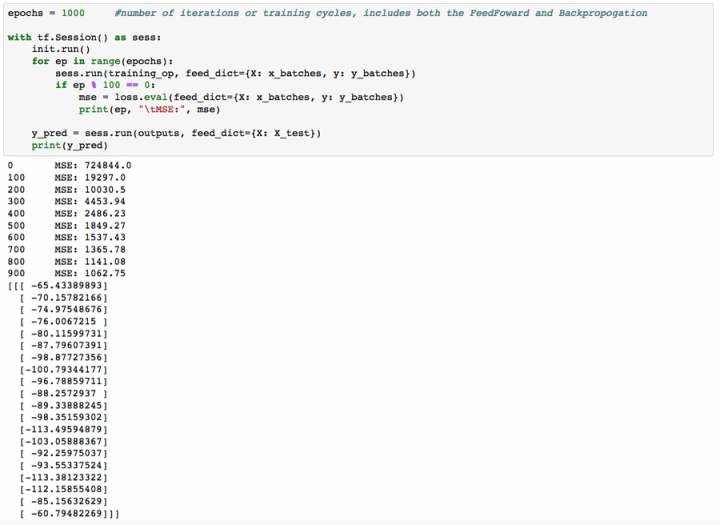
现在是时候在我们的训练数据上实施这个模型了。
我们将指定我们的批次训练序列循环的迭代/纪元的数量。接着&#xff0c;我们创建我们的图形对象&#xff08;tf.Session&#xff08;&#xff09;&#xff09;&#xff0c;并初始化我们的数据&#xff0c;以便在我们遍历历元时被馈送到模型中。缩写输出显示每100个纪元后的MSE。随着我们的模型提供数据向前和反向传播运行&#xff0c;它调整应用于输入的权重并运行另一个训练时期&#xff0c;我们的MSE得到了持续改善&#xff08;减少&#xff09;。最后&#xff0c;一旦模型完成&#xff0c;它将接受参数并将其应用于测试数据中&#xff0c;以Y的预测输出。
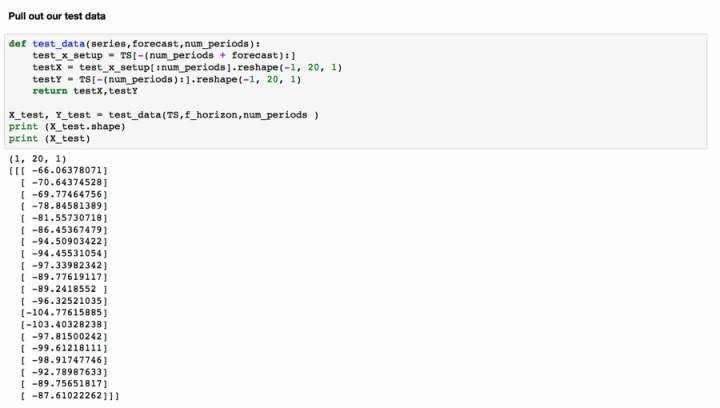
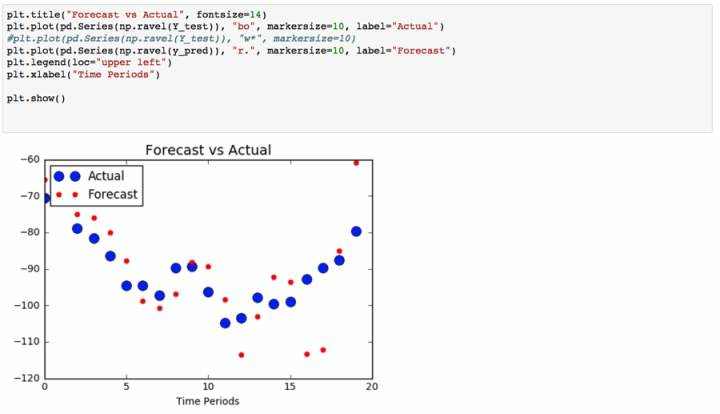
我们来看看我们的预测跟实际相差多少。对于我们的测试数据&#xff0c;我们集中在整个209个周期的最后20个时期。
看来这还有一些改进的空间。这可以通过改变隐藏的神经元的数量或增加迭代的数量来完成。优化我们的模式是一个试错的过程&#xff0c;但我们有一个好的开始。这是随机数据&#xff0c;所以我们期待着很好的结果&#xff0c;但是也许将这个模型应用到实时系列中会给ARIMA模型带来一些竞争压力。
数据科学家因为RNN&#xff08;和深度学习&#xff09;的出现&#xff0c;有了更多可用的选项以此来解决更多有趣的问题。许多数据科学家面临的一个问题是&#xff0c;一旦我们进行了优化&#xff0c;我们如何自动化我们的分析运行&#xff1f;拥有像MapR这样的平台允许这种能力&#xff0c;因为你可以在大型数据环境中构建&#xff0c;训练&#xff0c;测试和优化你的模型。在这个例子中&#xff0c;我们只使用了10个训练批次。如果我的数据允许我利用数百批次&#xff0c;而不仅仅是20个时期&#xff0c;我想我一定能改进这种模式。一旦我做到了&#xff0c;我可以把它打包成一个自动化脚本&#xff0c;在一个单独的节点&#xff0c;一个GPU节点&#xff0c;一个Docker容器中运行。这就是在融合数据平台上进行数据科学和深度学习的力量。
希望上述的文章能够帮到你理解TensorFlow。
文章原标题《Applying Deep Learning to Time Series Forecasting with TensorFlow》&#xff0c;
作者&#xff1a;Justin Brandenburg 译者&#xff1a;袁虎









 京公网安备 11010802041100号
京公网安备 11010802041100号