机器翻译(machine translation, MT)是用计算机来实现不同语言之间翻译的技术。需要翻译的语言通常称为源语言(source language),翻译成的结果语言称为目标语言(target language)。机器翻译即实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一。
本文将带领大家了解经典的端到端神经网络机器翻译Seq2Seq模型,以及如何用PaddlePaddle来训练。如果您想要实践效果更佳的翻译模型,请参考GitHub模型库中Transformer实现。
Seq2Seq项目地址:
https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/README.cn.md
Transformer项目地址:
https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/neural_machine_translation/transformer
早期机器翻译系统多为基于规则的翻译系统,需要由语言学家编写两种语言之间的转换规则,再将这些规则录入计算机。该方法对语言学家的要求非常高,而且我们几乎无法总结一门语言会用到的所有规则,更何况两种甚至更多的语言。因此统计机器翻译(Statistical Machine Translation, SMT)技术应运而生。
在统计机器翻译技术中,转化规则是由机器自动从大规模的语料中学习得到的,而非我们人主动提供规则。因此,它克服了基于规则的翻译系统所面临的知识获取瓶颈的问题,但仍然存在许多挑战:1)人为设计许多特征(feature),但永远无法覆盖所有的语言现象;2)难以利用全局的特征;3)依赖于许多预处理环节,如词语对齐、分词或符号化(tokenization)、规则抽取、句法分析等,而每个环节的错误会逐步累积,对翻译的影响也越来越大。
近年来,深度学习技术的发展为解决上述挑战提供了新的思路。将深度学习应用于机器翻译任务的方法大致分为两类:1)仍以统计机器翻译系统为框架,只是利用神经网络来改进其中的关键模块,如语言模型、调序模型等(见图1的左半部分);2)不再以统计机器翻译系统为框架,而是直接用神经网络将源语言映射到目标语言,即端到端的神经网络机器翻译(End-to-End Neural MachineTranslation, End-to-End NMT)(见图1的右半部分),简称为NMT模型。作为经典模型的实现,可以帮助大家更好的理解机器翻译。
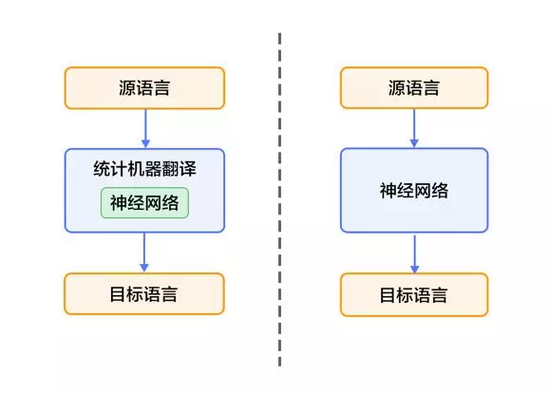
图1:基于神经网络的机器翻译系统
以中英翻译(中文翻译到英文)的模型为例,当模型训练完毕时,如果输入如下已分词的中文句子:
这些 是 希望 的 曙光 和 解脱 的 迹象 .
如果设定显示翻译结果的条数为3,生成的英语句子如下:
0 -5.36816 These are signs of hope and relief .1 -6.23177 These are the light of hope and relief .2 -7.7914 These are the light of hope and the relief of hope .
左起第一列是生成句子的序号;左起第二列是该条句子的得分(从大到小),分值越高越好;左起第三列是生成的英语句子。
另外有两个特殊标志:
本节依次介绍双向循环神经网络(Bi-directional Recurrent Neural Network),NMT模型中典型的编码器-解码器(Encoder-Decoder)框架以及柱搜索(beam search)算法。
我们这里介绍Bengio团队在论文[2,4]中提出的另一种结构。该结构的目的是输入一个序列,得到其在每个时刻的特征表示,即输出的每个时刻都用定长向量表示到该时刻的上下文语义信息。
具体来说,该双向循环神经网络分别在时间维以顺序和逆序——即前向(forward)和后向(backward)——依次处理输入序列,并将每个时间步RNN的输出拼接成为最终的输出层。这样每个时间步的输出节点,都包含了输入序列中当前时刻完整的过去和未来的上下文信息。下图展示的是一个按时间步展开的双向循环神经网络。该网络包含一个前向和一个后向RNN,其中有六个权重矩阵:输入到前向隐层和后向隐层的权重矩阵 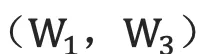 ,隐层到隐层自己的权重矩阵
,隐层到隐层自己的权重矩阵 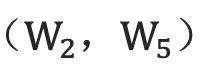 ,前向隐层和后向隐层到输出层的权重矩阵
,前向隐层和后向隐层到输出层的权重矩阵 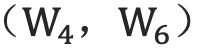 。注意,该网络的前向隐层和后向隐层之间没有连接。
。注意,该网络的前向隐层和后向隐层之间没有连接。
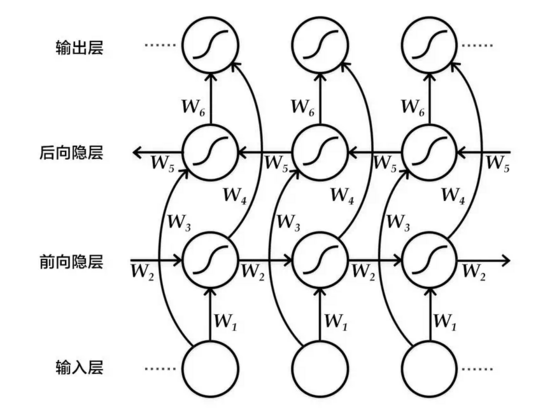
图2:按时间步展开的双向循环神经网络
编码器-解码器(Encoder-Decoder)[2]框架用于解决由一个任意长度的源序列到另一个任意长度的目标序列的变换问题。即编码阶段将整个源序列编码成一个向量,解码阶段通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用RNN实现。
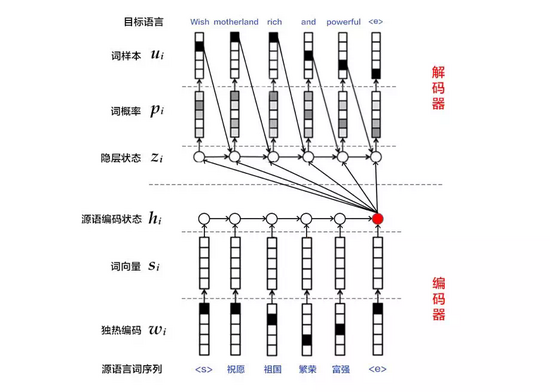
图3:编码器-解码器框架
编码器
编码阶段分为三步:
1. one-hot vector表示:将源语言句子
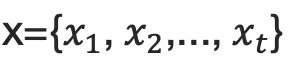
的每个词 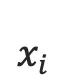 表示成一个列向量
表示成一个列向量 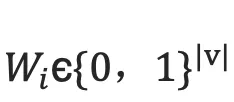 ,i=1,2,...,T。这个向量
,i=1,2,...,T。这个向量 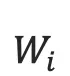 的维度与词汇表大小|V| 相同,并且只有一个维度上有值1(该位置对应该词在词汇表中的位置),其余全是0。
的维度与词汇表大小|V| 相同,并且只有一个维度上有值1(该位置对应该词在词汇表中的位置),其余全是0。
2. 映射到低维语义空间的词向量:one-hot vector表示存在两个问题,1)生成的向量维度往往很大,容易造成维数灾难;2)难以刻画词与词之间的关系(如语义相似性,也就是无法很好地表达语义)。因此,需再one-hot vector映射到低维的语义空间,由一个固定维度的稠密向量(称为词向量)表示。记映射矩阵为 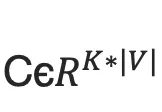 ,用
,用 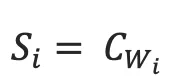 表示第i个词的词向量,K为向量维度。
表示第i个词的词向量,K为向量维度。
3.用RNN编码源语言词序列:这一过程的计算公式为
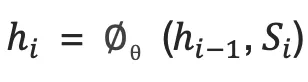
,其中 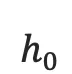 是一个全零的向量,
是一个全零的向量,  是一个非线性激活函数,最后得到的
是一个非线性激活函数,最后得到的
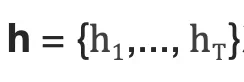
就是RNN依次读入源语言T个词的状态编码序列。整句话的向量表示可以采用h在最后一个时间步T的状态编码,或使用时间维上的池化(pooling)结果。
第3步也可以使用双向循环神经网络实现更复杂的句编码表示,具体可以用双向GRU实现。前向GRU按照词序列  的顺序依次编码源语言端词,并得到一系列隐层状态
的顺序依次编码源语言端词,并得到一系列隐层状态 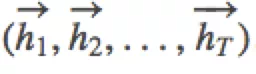 。类似的,后向GRU按照(,...,)的顺序依次编码源语言端词,得到
。类似的,后向GRU按照(,...,)的顺序依次编码源语言端词,得到 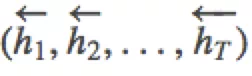 。最后对于词
。最后对于词 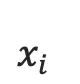 ,通过拼接两个GRU的结果得到它的隐层状态,即
,通过拼接两个GRU的结果得到它的隐层状态,即 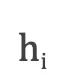 =
= 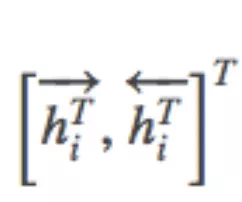 。
。
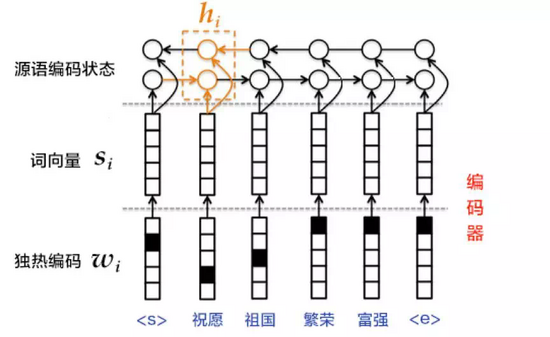
图4:使用双向GRU的编码器
解码器
机器翻译任务的训练过程中,解码阶段的目标是最大化下一个正确的目标语言词的概率。思路是: 每一个时刻,根据源语言句子的编码信息(又叫上下文向量,context vector)c、真实目标语言序列的第i个 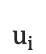 和i时刻RNN的隐层状态
和i时刻RNN的隐层状态 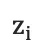 ,计算出下一个隐层状态。计算公式如下:
,计算出下一个隐层状态。计算公式如下:
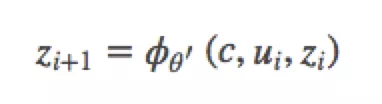
其中 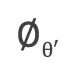 是一个非线性激活函数;c是源语言句子的上下文向量,在不使用注意力机制时,如果编码器的输出是源语言句子编码后的最后一个元素,则可以定义
是一个非线性激活函数;c是源语言句子的上下文向量,在不使用注意力机制时,如果编码器的输出是源语言句子编码后的最后一个元素,则可以定义
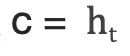
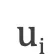 是目标语言序列的第i个单词,
是目标语言序列的第i个单词, 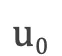 是目标语言序列的开始标记
是目标语言序列的开始标记,表示解码开始; 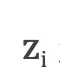 是i时刻解码RNN的隐层状态,
是i时刻解码RNN的隐层状态, 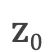 是一个全零的向量。
是一个全零的向量。
1.将 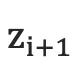 通过softmax归一化,得到目标语言序列的第i+1个单词的概率分布
通过softmax归一化,得到目标语言序列的第i+1个单词的概率分布 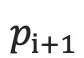 。概率分布公式如下:
。概率分布公式如下:
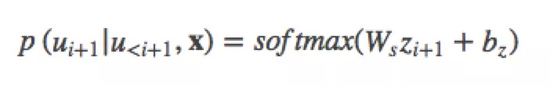
其中 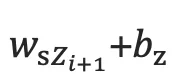 是对每个可能的输出单词进行打分,再softmax归一化就可以得到第i+1个词的概率
是对每个可能的输出单词进行打分,再softmax归一化就可以得到第i+1个词的概率 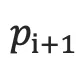 。
。
2.根据 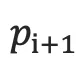 和
和 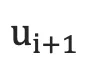 计算代价。
计算代价。
3.重复步骤1~2,直到目标语言序列中的所有词处理完毕。
机器翻译任务的生成过程,通俗来讲就是根据预先训练的模型来翻译源语言句子。生成过程中的解码阶段和上述训练过程的有所差异,具体介绍请见柱搜索算
柱搜索(beam search)是一种启发式图搜索算法,用于在图或树中搜索有限集合中的最优扩展节点,通常用在解空间非常大的系统(如机器翻译、语音识别)中,原因是内存无法装下图或树中所有展开的解。如在机器翻译任务中希望翻译“你好hello ),也可能生成无限句话(hello循环出现的次数不定),为了找到其中较好的翻译结果,我们可采用柱搜索算法。
柱搜索算法使用广度优先策略建立搜索树,在树的每一层,按照启发代价(heuristic cost)(本教程中,为生成词的log概率之和)对节点进行排序,然后仅留下预先确定的个数(文献中通常称为beam width、beam size、柱宽度等)的节点。只有这些节点会在下一层继续扩展,其他节点就被剪掉了,也就是说保留了质量较高的节点,剪枝了质量较差的节点。因此,搜索所占用的空间和时间大幅减少,但缺点是无法保证一定获得最优解。
使用柱搜索算法的解码阶段,目标是最大化生成序列的概率。思路是:
1.每一个时刻,根据源语言句子的编码信息cc、生成的第ii个目标语言序列单词 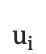 和i时刻RNN的隐层状态
和i时刻RNN的隐层状态 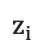 ,计算出下一个隐层状态
,计算出下一个隐层状态 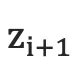 。
。
2.将 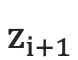 通过softmax归一化,得到目标语言序列的第i+1个单词的概率分布
通过softmax归一化,得到目标语言序列的第i+1个单词的概率分布 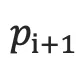 。
。
3.根据 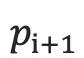 采样出单词
采样出单词 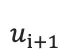 。
。
4.重复步骤1~3,直到获得句子结束标记
注意: 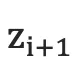 和
和 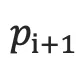 的计算公式同解码器中的一样。且由于生成时的每一步都是通过贪心法实现的,因此并不能保证得到全局最优解。
的计算公式同解码器中的一样。且由于生成时的每一步都是通过贪心法实现的,因此并不能保证得到全局最优解。
本教程使用WMT-14数据集中的bitexts(afterselection)作为训练集,dev+test data作为测试集和生成集。
我们的预处理流程包括两步:
将每个源语言到目标语言的平行语料库文件合并为一个文件:
合并每个XXX.src和XXX.trg文件为XXX。
XXX中的第i行内容为XXX.src中的第i行和XXX.trg中的第i行连接,用't'分隔。
创建训练数据的“源字典”和“目标字典”。每个字典都有DICTSIZE个单词,包括:语料中词频最高的(DICTSIZE - 3)个单词,和3个特殊符号(序列的开始)、
因为完整的数据集数据量较大,为了验证训练流程,PaddlePaddle接口paddle.dataset.wmt14中默认提供了一个经过预处理的较小规模的数据集。
该数据集有193319条训练数据,6003条测试数据,词典长度为30000。因为数据规模限制,使用该数据集训练出来的模型效果无法保证。
下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量。
from __future__ import print_functionimport paddleimport paddle.fluid as fluidimport paddle.fluid.layers as pdimport osimport systry:from paddle.fluid.contrib.trainer import *from paddle.fluid.contrib.inferencer import *except ImportError:print("In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",file=sys.stderr)from paddle.fluid.trainer import *from paddle.fluid.inferencer import *dict_size = 30000 # 字典维度source_dict_dim = target_dict_dim = dict_size # 源/目标语言字典维度hidden_dim = 32 # 编码器中的隐层大小word_dim = 16 # 词向量维度batch_size = 2 # batch 中的样本数max_length = 8 # 生成句子的最大长度topk_size = 50beam_size = 2 # 柱宽度is_sparse = Truedecoder_size = hidden_dim # 解码器中的隐层大小model_save_dir = "machine_translation.inference.model"
然后如下实现编码器框架:
def encoder(is_sparse): # 定义源语言id序列的输入数据 src_word_id = pd.data( name="src_word_id", shape=[1], dtype='int64', lod_level=1) # 将上述编码映射到低维语言空间的词向量 src_embedding = pd.embedding( input=src_word_id, size=[dict_size, word_dim], dtype='float32', is_sparse=is_sparse, param_attr=fluid.ParamAttr(name='vemb')) # LSTM层:fc + dynamic_lstm fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh') lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4) # 取源语言序列编码后的最后一个状态 encoder_out = pd.sequence_last_step(input=lstm_hidden0) return encoder_out
再实现训练模式下的解码器:
def train_decoder(context):# 定义目标语言id序列的输入数据,并映射到低维语言空间的词向量trg_language_word = pd.data(name="target_language_word", shape=[1], dtype='int64', lod_level=1)trg_embedding = pd.embedding(input=trg_language_word,size=[dict_size, word_dim],dtype='float32',is_sparse=is_sparse,param_attr=fluid.ParamAttr(name='vemb'))rnn = pd.DynamicRNN()with rnn.block(): # 使用 DynamicRNN 定义每一步的计算# 获取当前步目标语言输入的词向量current_word = rnn.step_input(trg_embedding)# 获取隐层状态pre_state = rnn.memory(init=context)# 解码器计算单元:单层前馈网络current_state = pd.fc(input=[current_word, pre_state],size=decoder_size,act='tanh')# 计算归一化的单词预测概率current_score = pd.fc(input=current_state,size=target_dict_dim,act='softmax')# 更新RNN的隐层状态rnn.update_memory(pre_state, current_state)# 输出预测概率rnn.output(current_score)return rnn()
实现推测模式下的解码器:
def decode(context):init_state = context# 定义解码过程循环计数变量array_len = pd.fill_constant(shape=[1], dtype='int64', value=max_length)counter = pd.zeros(shape=[1], dtype='int64', force_cpu=True)# 定义 tensor array 用以保存各个时间步的内容,并写入初始id,score和statestate_array = pd.create_array('float32')pd.array_write(init_state, array=state_array, i=counter)ids_array = pd.create_array('int64')scores_array = pd.create_array('float32')init_ids = pd.data(name="init_ids", shape=[1], dtype="int64", lod_level=2)init_scores = pd.data(name="init_scores", shape=[1], dtype="float32", lod_level=2)pd.array_write(init_ids, array=ids_array, i=counter)pd.array_write(init_scores, array=scores_array, i=counter)# 定义循环终止条件变量cOnd= pd.less_than(x=counter, y=array_len)# 定义 while_opwhile_op = pd.While(cOnd=cond)with while_op.block(): # 定义每一步的计算# 获取解码器在当前步的输入,包括上一步选择的id,对应的score和上一步的statepre_ids = pd.array_read(array=ids_array, i=counter)pre_state = pd.array_read(array=state_array, i=counter)pre_score = pd.array_read(array=scores_array, i=counter)# 更新输入的state为上一步选择id对应的statepre_state_expanded = pd.sequence_expand(pre_state, pre_score)# 同训练模式下解码器中的计算逻辑,包括获取输入向量,解码器计算单元计算和# 归一化单词预测概率的计算pre_ids_emb = pd.embedding(input=pre_ids,size=[dict_size, word_dim],dtype='float32',is_sparse=is_sparse,param_attr=fluid.ParamAttr(name='vemb'))current_state = pd.fc(input=[pre_state_expanded, pre_ids_emb],size=decoder_size,act='tanh')current_state_with_lod = pd.lod_reset(x=current_state, y=pre_score)current_score = pd.fc(input=current_state_with_lod,size=target_dict_dim,act='softmax')topk_scores, topk_indices = pd.topk(current_score, k=beam_size)# 计算累计得分,进行beam searchaccu_scores = pd.elementwise_add(x=pd.log(topk_scores), y=pd.reshape(pre_score, shape=[-1]), axis=0)selected_ids, selected_scores = pd.beam_search(pre_ids,pre_score,topk_indices,accu_scores,beam_size,end_id=10,level=0)with pd.Switch() as switch:with switch.case(pd.is_empty(selected_ids)):pd.fill_constant(shape=[1], value=0, dtype='bool', force_cpu=True, out=cond)with switch.default():pd.increment(x=counter, value=1, in_place=True)pd.array_write(current_state, array=state_array, i=counter)pd.array_write(selected_ids, array=ids_array, i=counter)pd.array_write(selected_scores, array=scores_array, i=counter)length_cOnd= pd.less_than(x=counter, y=array_len)finish_cOnd= pd.logical_not(pd.is_empty(x=selected_ids))pd.logical_and(x=length_cond, y=finish_cond, out=cond)translation_ids, translation_scores = pd.beam_search_decode(ids=ids_array, scores=scores_array, beam_size=beam_size, end_id=10)return translation_ids, translation_scores
进而,我们定义一个train_program来使用inference_program计算出的结果,在标记数据的帮助下来计算误差。我们还定义了一个optimizer_func来定义优化器:
def train_program():cOntext= encoder()rnn_out = train_decoder(context)label = pd.data(name="target_language_next_word", shape=[1], dtype='int64', lod_level=1)cost = pd.cross_entropy(input=rnn_out, label=label)avg_cost = pd.mean(cost)return avg_costdef optimizer_func():return fluid.optimizer.Adagrad(learning_rate=1e-4,regularization=fluid.regularizer.L2DecayRegularizer(regularization_coeff=0.1))
定义您的训练环境,可以指定训练是发生在CPU还是GPU上。
if use_cuda and not fluid.core.is_compiled_with_cuda():returnplace = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
下一步是为训练和测试定义数据提供器。提供器读入一个大小为 BATCH_SIZE的数据。paddle.dataset.wmt.train 每次会在乱序化后提供一个大小为BATCH_SIZE的数据,乱序化的大小为缓存大小buf_size。
train_reader = paddle.batch(paddle.reader.shuffle(paddle.dataset.wmt14.train(dict_size), buf_size=1000),batch_size=batch_size)
训练器需要一个训练程序和一个训练优化函数。
trainer = Trainer(train_func=train_program, place=place, optimizer_func=optimizer_func)
feed_order用来定义每条产生的数据和paddle.layer.data之间的映射关系。比如,wmt14.train产生的第一列的数据对应的是src_word_id这个特征。
feed_order = ['src_word_id', 'target_language_word', 'target_language_next_word']
回调函数event_handler在一个之前定义好的事件发生后会被调用。例如,我们可以在每步训练结束后查看误差。
def event_handler(event):if isinstance(event, EndStepEvent):if event.step % 10 == 0:print('pass_id=' + str(event.epoch) + ' batch=' + str(event.step))if isinstance(event, EndEpochEvent):trainer.save_params(model_save_dir)
最后,我们传入训练循环数(num_epoch)和一些别的参数,调用 trainer.train 来开始训练
trainer = Trainer(train_func=train_program, place=place, optimizer_func=optimizer_func)trainer.train(reader=train_reader,num_epochs=EPOCH_NUM,event_handler=event_handler,feed_order=feed_order)
使用上面定义的 encoder 和 decoder 函数来推测翻译后的对应id和分数。
cOntext= encoder()translation_ids, translation_scores = decode(context)
我们先初始化id和分数来生成tensors来作为输入数据。在这个预测例子中,我们用 wmt14.test 数据中的第一个记录来做推测,最后我们用"源字典"和"目标字典"来列印对应的句子结果。
init_ids_data = np.array([1 for _ in range(batch_size)], dtype='int64')init_scores_data = np.array([1. for _ in range(batch_size)], dtype='float32')init_ids_data = init_ids_data.reshape((batch_size, 1))init_scores_data = init_scores_data.reshape((batch_size, 1))init_lod = [1] * batch_sizeinit_lod = [init_lod, init_lod]init_ids = fluid.create_lod_tensor(init_ids_data, init_lod, place)init_scores = fluid.create_lod_tensor(init_scores_data, init_lod, place)test_data = paddle.batch(paddle.reader.shuffle(paddle.dataset.wmt14.test(dict_size), buf_size=1000),batch_size=batch_size)feed_order = ['src_word_id']feed_list = [framework.default_main_program().global_block().var(var_name)for var_name in feed_order]feeder = fluid.DataFeeder(feed_list, place)src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
现在我们可以进行预测了。我们要在 feed_order 提供对应参数,放在 executor 上运行以取得id和分数结果:
for data in test_data():feed_data = map(lambda x: [x[0]], data)feed_dict = feeder.feed(feed_data)feed_dict['init_ids'] = init_idsfeed_dict['init_scores'] = init_scoresresults = exe.run(framework.default_main_program(),feed=feed_dict,fetch_list=[translation_ids, translation_scores],return_numpy=False)result_ids = np.array(results[0])result_ids_lod = results[0].lod()result_scores = np.array(results[1])print("Original sentence:")print(" ".join([src_dict[w] for w in feed_data[0][0][1:-1]]))print("Translated score and sentence:")for i in xrange(beam_size):start_pos = result_ids_lod[1][i] + 1end_pos = result_ids_lod[1][i+1]print("%d\t%.4f\t%s\n" % (i+1, result_scores[end_pos-1]," ".join([trg_dict[w] for w in result_ids[start_pos:end_pos]])))break
端到端的神经网络机器翻译是近几年兴起的一种全新的机器翻译方法。在本文中,我们介绍了NMT中典型的“编码器-解码器”框架。由于NMT是一个典型的Seq2Seq(Sequence to Sequence,序列到序列)学习问题,因此,Seq2Seq中的query改写(query rewriting)、摘要、单轮对话等问题都可以用本教程的模型来解决。
1. Koehn P. Statistical machine translation[M]. Cambridge University Press, 2009.
2. Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoderfor statistical machine translation[C]//Proceedings of the 2014 Conference on Empirical Methods inNatural Language Processing (EMNLP), 2014: 1724-1734.
3.Chung J, Gulcehre C, Cho K H, et al. Empiricalevaluation of gated recurrent neural networks on sequence modeling[J]. arXiv preprint arXiv:1412.3555, 2014.
4.Bahdanau D, Cho K, Bengio Y. Neuralmachine translation by jointly learning to align and translate[C]//Proceedings of ICLR 2015, 2015.
5.Papineni K, Roukos S, Ward T, et al. BLEU:a method for automatic evaluation of machine translation[C]//Proceedings of the 40th annual meeting on association forcomputational linguistics. Association for Computational Linguistics, 2002:311-318.
以上所述就是小编给大家介绍的《如何用PaddlePaddle实现机器翻译?》,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对 我们 的支持!






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有