Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,它提供了一个分布式多用户能力的全文搜索引擎,搜索速度很快。例如百度搜索那样,全文搜索,有匹配的就查出来,且高亮显示。
为啥不用sql 去like查询?
如我们在淘宝搜索框输入
小米手机,那 like 只能 搜索到卖小米手机的店,搜不到小米10手机、小米12等相关店铺,且数据量大时,搜索速度慢。
使用场景
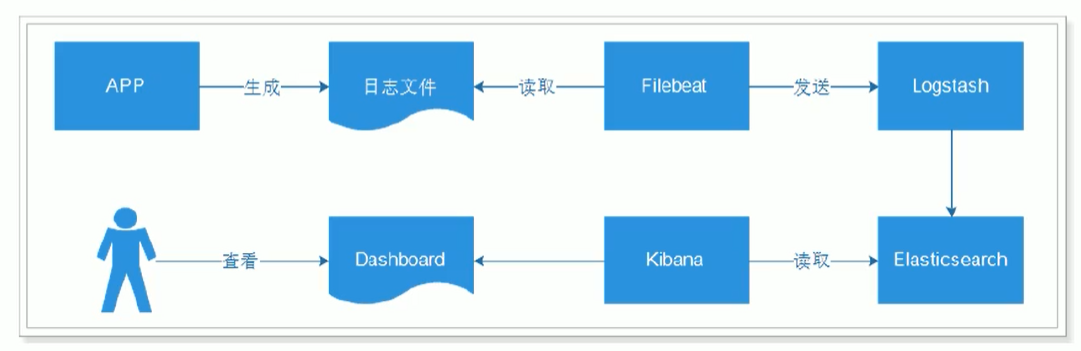
一般我们可以把ES配合logstash,kibana来做日志分析系统,或者是搜索方面的系统功能,比如在网上商城系统里实现搜索商品的功能也会用到ES。
ELK由Elasticsearch、Logstash和Kibana三部分组件组成;
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用
kibana 是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。

链接: https://www.elastic.co/cn/downloads/elasticsearch
选择自己想要的版本

启动:双击bin目录下的elasticsearch.bat文件
启动成功,访问http://localhost:9200/
1、使用谷歌插件
能打开谷歌商店的可以直接搜索elasticsearch head下载插件
2、或者下载项目
链接: https://github.com/mobz/elasticsearch-head/ 1、打开crx文件夹,将.crx文件复制出来改为.rar文件
1、打开crx文件夹,将.crx文件复制出来改为.rar文件
2、解压成文件夹
3、打开谷歌更多工具–》扩展程序–》开发者模式–》加载已解压工具
4、打开插件 熟悉插件
熟悉插件
概述:连接本地9200端口后,可以概述可以看状态信息,与访问9200的信息
索引:索引可以当成数据库,所有的数据存在索引里,不是sql的提高效率的数据结构
数据浏览:就是浏览我们建的索引里的数据
链接: https://www.elastic.co/cn/downloads/kibana
版本要与es一致
启动:打开bin目录底下的kibana.bat
访问 http://localhost:5601

点击config–>编辑kibana.yml 关掉kibana,重开生效
关掉kibana,重开生效

1、分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2、实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
负载再平衡和路由在大多数情况下自动完成。
3、可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
4、支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
分词就是把一段中文或者别的划分成一个个关键字,我们在搜索时会把自己的信息进行分词,会把数据库中的或者索引库种得数据进行分词,然后进行一个匹配操作,默认得中文分词是将每个字堪称一个词,比如:“好好学习”,会被划分为“好”“好”“学”“习”,这不符合我们中文得要求,所以我们需要安装IK分词器来分词中文。
IK分词算法:ik_smart 最少切分 和 ik_max_word最细粒度划分。
链接: https://github.com/medcl/elasticsearch-analysis-ik/releases
注意版本也要对应es
下载好后,在es得 plugins文件夹下建个ik文件夹,直接解压在这,重启,即可。
查询是否安装成功
测试、点击开发工具


进入ik插件–》点击config–>新建myik.dic–>输入想划分的词
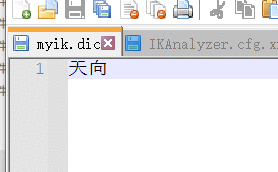
打开IKAnalyzer.cfg.xml–》添加我们的新字典 重启es,再次分词,会将我们自己写的词进行分词
重启es,再次分词,会将我们自己写的词进行分词

1、创建一个索引
// PUT /索引名/类型名(默认_doc)/ 文档id {请求体}
PUT /test/typeTest/1
{
"name":"测试",
"age":"18"
}
运行
可看到我们新建的索引 自动增加了索引,添加了数据
自动增加了索引,添加了数据
| 类型 | 字段 |
|---|---|
| 字符串 | text、keyword(整体,不会分词) |
| 数值 | long、integer、short、byte、double、float、half float、scaled float |
| 日期 | date |
| 布尔值 | boolean |
| 二进制 | binary |
…
测试
get /test/typeTest/1 查询某个文档 get /索引名
get /索引名
GET /user/_doc/_search?q=age:22
搜索年龄22岁的人员
修改信息后、直接再put一次
PUT /test/typeTest/1
{
"name":"测试123",
"age":"18"
}
 用POST 后缀加 /_update
用POST 后缀加 /_update
POST /test/typeTest/1/_update
{
"doc":{
"name":"测试321"
}
}

直接 DELETE
DELETE test // 删除索引
DELETE /test/typeTest/1 //删除id为1的文档
GET /user/_doc/_search
{
"query":{ // 查询参数体
"match":{
"name":"张三"
}
}
}

GET /user/_doc/_search
{
"query":{
"match":{
"name":"张三"
}
},
"_source":["name","age"] // 只查这两个字段
}
GET /user/_doc/_search
{
"query":{
"match":{
"name":"张三"
}
},
"sort":[ // 排序
{
"age":{
"order":"desc" // asc
}
}
]
}
GET /user/_doc/_search
{
"query":{
"match":{
"name":"张三"
}
},
"from":0, // 第几页
"size":4 // 每页个数
}
1、must
以下条件要符合相当于 sql and (where name=“张三” and age=“20”)
GET /user/_doc/_search
{
"query":{
"bool":{
"must":[// 以下条件要符合相当于 sql where name="张三" and age="20"
{
"match":{
"name":"张三"
}
},
{
"match":{
"age":"20"
}
}
]
}
}
}
2、should
满足其一,相当于 sql or (where name=“张三” or age=“20”)
GET /user/_doc/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"张三"
}
},
{
"match":{
"age":"20"
}
}
]
}
}
}
3、must_not
不满足,相当于 sql not (where name!=“张三” or age!=“20”)
GET /user/_doc/_search
{
"query":{
"bool":{
"must_not":[
{
"match":{
"name":"张三"
}
},
{
"match":{
"age":"20"
}
}
]
}
}
}
6、过滤
GET /user/_doc/_search六、整合springboot
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"张三"
}
},
],
"filter":{
"range":{
"age":{
"gt":10
}
}
}
}
}
}
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
@SpringBootTest
class ElasticsearchApplicationTests {
@Resource
private RestHighLevelClient restHighLevelClient;
/**
* 创建索引 request put test_index
*/
@Test
public void createIndex() throws IOException {
// 1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest("test_index");
// 2、执行请求
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println("createIndexRespOnse= " + createIndexResponse);
}
/**
* 判断索引是否存在
* @throws IOException
*/
@Test
public void existIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("test_index");
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("exists = " + exists);
}
/**
* 测试删除索引
*/
@Test
public void deleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("test_index");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
System.out.println("delete = " + delete);
}
}
执行结果
@SpringBootTest
public class DucumentTests {
@Autowired
RestHighLevelClient restHighLevelClient;
/**
* 添加文档(如果没有索引自己会建)
* @throws IOException
*/
@Test
public void addDocument() throws IOException {
// 创建对象
User user = new User("test",18,new Date());
// 创建请求
IndexRequest indexRequest = new IndexRequest("es_index");
// 规则 put /es_index/_doc/1
indexRequest.id("1");
// 将我们的数据放入请求 json
String jsonUser = JSON.toJSONString(user);
indexRequest.source(jsonUser, XContentType.JSON);
// 客户端发送请求
IndexResponse index = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println("index = " + index);
System.out.println("indexStatus = " + index.status());
}
/**
* 获取文档
* @throws IOException
*/
@Test
public void getDocument() throws IOException {
// get /index/_doc/1
GetRequest getRequest = new GetRequest("es_index", "1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println("getResponse.getSourceAsString() = " + getResponse.getSourceAsString());
System.out.println("getRespOnse= " + getResponse);
}
/**
* 更新文档
*/
@Test
public void updateDocument() throws IOException {
// post /index/_doc/1/_update
UpdateRequest updateRequest = new UpdateRequest("es_index", "1");
// 修改内容
User user = new User("test2",20,new Date());
String jsonUser = JSON.toJSONString(user);
updateRequest.doc(jsonUser,XContentType.JSON);
UpdateResponse update = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println("update = " + update);
}
/**
* 删除文档
*/
@Test
public void deleteDodument() throws IOException {
// DELETE /index/_doc/1
DeleteRequest deleteRequest = new DeleteRequest("es_index", "1");
DeleteResponse delete = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println("delete.status() = " + delete.status());
}
}
/**
* 批量插入数据
*/
@Test
public void bulk() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
List<User> userList = new ArrayList<>();
userList.add(new User("h1",3,new Date()));
userList.add(new User("h2",4,new Date()));
userList.add(new User("h3",5,new Date()));
userList.add(new User("h4",6,new Date()));
userList.add(new User("h5",7,new Date()));
// 批处理请求
int size = userList.size();
for (int i = 0; i < size; i++) {
// 如果是批量更新、删除改这里就可以
bulkRequest.add(new IndexRequest("es_index")
.id(""+(i+1))
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
}

/**
* 搜索
* searchRequest 搜索请求
* sourceBuilder 条件构造
* TermQueryBuilder 精确查询
* MatchAllQueryBuilder 查询所有
*/
@Test
public void search1() throws IOException {
SearchRequest searchRequest = new SearchRequest("es_index");
// 使用搜索条件构造器,构造搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件,使用QueryBuilders 工具类,来实现
// QueryBuilders.termQuery 精确查询
TermQueryBuilder queryBuilder = QueryBuilders.termQuery("username", "h1");
// QueryBuilders.matchAllQuery 匹配所有
// MatchAllQueryBuilder allQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(queryBuilder);
// 分页
// sourceBuilder.from(); // 默认 0
// sourceBuilder.size(); // 默认 10
// 高亮
// HighlightBuilder highlightBuilder = new HighlightBuilder(); //高亮构造器
// highlightBuilder.field("username"); //设置高亮字段
// highlightBuilder.requireFieldMatch(false); // 关闭多个高亮
// highlightBuilder.preTags(""); //设置前缀
// highlightBuilder.postTags(""); //设置后缀
// sourceBuilder.highlighter(highlightBuilder);
searchRequest.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("search.getHits() = " + JSON.toJSONString(search.getHits()));
System.out.println("==============================");
for (SearchHit hits:search.getHits().getHits()){
System.out.println("hits.getSourceAsString() = " + hits.getSourceAsString());
}
}









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有