Apache Spark最初在2009年诞生于美国加州大学伯克利分校的APM实验室,并于2010年开源,如今是Apache软件基金会下的顶级开源项目之一。Spark的目标是设计一种编程模型,能够快速地进行数据分析。Spark提供了内存计算,减少了IO开销。另外Spark是基于Scala编写的,提供了交互式的编程体验。经过10年的发展,Spark成为了炙手可热的大数据处理平台,目前最新的版本是Spark3.0。本文主要是对Spark进行一个总体概览式的介绍,后续内容会对具体的细节进行展开讨论。本文的主要内容包括:
- √Spark的关注度分析
- √Spark的特点
- √Spark的一些重要概念
- √Spark组件概览
- √Spark运行架构概览
- √Spark编程小试牛刀
Spark的关注热度分析概况
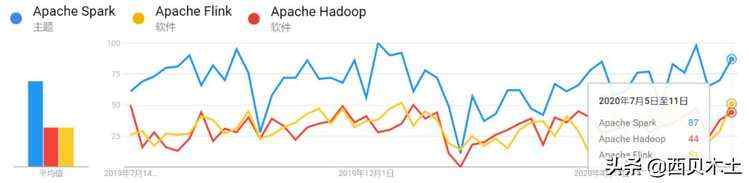
下图展示了近1年内在国内关于Spark、Hadoop及Flink的搜索趋势
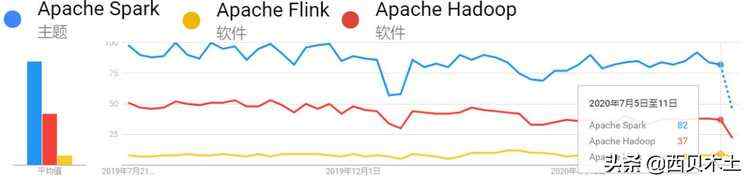
近1年内全球关于Spark、Hadoop及Flink的搜索趋势,如下:
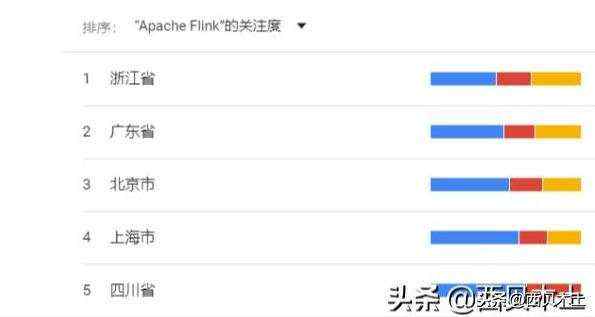
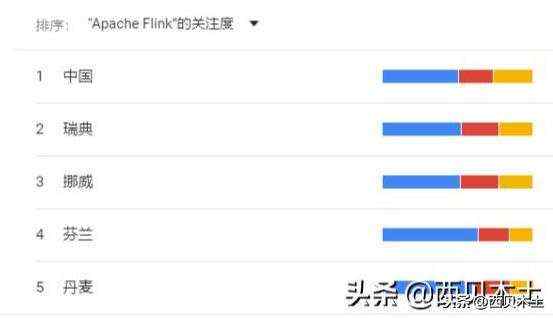
近1年国内关于Spark、Hadoop及Flink的搜索热度区域分布情况(按Flink搜索热度降序排列):
近1年全球关于Spark、Hadoop及Flink的搜索热度区域分布情况(按Flink搜索热度降序排列):
分析
从上面的4幅图可以看出,近一年无论是在国内还是全球,关于Spark的搜索热度始终是比Hadoop和Flink要高。近年来Flink发展迅猛,其在国内有阿里的背书,Flink天然的流处理特点使其成为了开发流式应用的首选框架。可以看出,虽然Flink在国内很火,但是放眼全球,热度仍然不及Spark。所以学习并掌握Spark技术仍然是一个不错的选择,技术有很多的相似性,如果你已经掌握了Spark,再去学习Flink的话,相信你会有种似曾相识的感觉。
Spark的特点- 速度快Apache Spark使用DAG调度程序、查询优化器和物理执行引擎,为批处理和流处理提供了高性能。
- 易于使用支持使用Java,Scala,Python,R和SQL快速编写应用程序。Spark提供了80多个高级操作算子,可轻松构建并行应用程序。
- 通用性Spark提供了非常丰富的生态栈,包括SQL查询、流式计算、机器学习和图计算等组件,这些组件可以无缝整合在一个应用中,通过一站部署,可以应对多种复杂的计算场景
- 运行模式多样Spark可以使用Standalone模式运行,也可以运行在Hadoop,Apache Mesos,Kubernetes等环境中运行。并且可以访问HDFS、Alluxio、Apache Cassandra、Apache HBase、Apache Hive等多种数据源中的数据。
Spark的一些重要概念- RDD弹性分布式数据集(Resilient Distributed Dataset),是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
- DAG有向无环图(Directed Acyclic Graph),反映RDD之间的依赖关系
- Application用户编写的Spark程序,由 driver program 和 executors 组成
- Application jar用户编写的应用程序JAR包
- Driver program用程序main()函数的进程,可以创建SparkContext
- Cluster manager集群管理器,属于一个外部服务,用于资源请求分配(如:standalone manager, Mesos, YARN)
- Deploy mode部署模式,决定Driver进程在哪里运行。如果是cluster模式,会由框架本身在集群内部某台机器上启动Driver进程。如果是client模式,会在提交程序的机器上启动Driver进程
- Worker node集群中运行应用程序的节点Executor运行在Worknode节点上的一个进程,负责运行具体的任务,并为应用程序存储数据
- Task运行在executor中的工作单元
- Job一个job包含多个RDD及一些列的运行在RDD之上的算子操作,job需要通过action操作进行触发(比如save、collect等)
- Stage每一个作业会被分成由一些列task组成的stage,stage之间会相互依赖
Spark组件概览
Spark生态系统主要包括Spark Core、SparkSQL、SparkStreaming、MLlib和GraphX等组件,具体如下图所示:
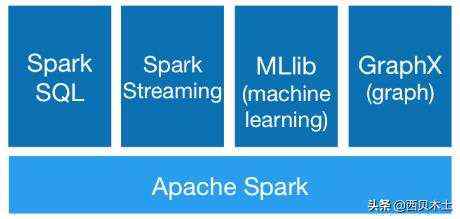
- Spark CoreSpark core是Spark的核心,包含了Spark的基本功能,如内存计算、任务调度、部署模式、存储管理等。SparkCore提供了基于RDD的API是其他高级API的基础,主要功能是实现批处理。
- Spark SQLSpark SQL主要是为了处理结构化和半结构化数据而设计的,SparkSQL允许用户在Spark程序中使用SQL、DataFrame和DataSetAPI查询结构化数据,支持Java、Scala、Python和R语言。由于DataFrame API提供了统一的访问各种数据源的方式(包括Hive、Avro、Parquet、ORC和JDBC),用户可以通过相同的方式连接任何数据源。另外,Spark SQL可以使用hive的元数据,从而实现了与Hive的完美集成,用户可以将Hive的作业直接运行在Spark上。Spark SQL可以通过spark-sql的shell命令访问。
- SparkStreamingSparkStreaming是Spark很重要的一个模块,可实现实时数据流的可伸缩,高吞吐量,容错流处理。在内部,其工作方式是将实时输入的数据流拆分为一系列的micro batch,然后由Spark引擎进行处理。SparkStreaming支持多种数据源,如kafka、Flume和TCP套接字等
- MLlibMLlib是Spark提供的一个机器学习库,用户可以使用Spark API构建一个机器学习应用,Spark尤其擅长迭代计算,性能是Hadoop的100倍。该lib包含了常见机器学习算法,比如逻辑回归、支持向量机、分类、聚类、回归、随机森林、协同过滤、主成分分析等。
- GraphXGraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,GraphX性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。GraphX内置了许多图算法,比如著名的PageRank算法。
Spark运行架构概览
从整体来看,Spark应用架构包括以下几个主要部分:
- Driver program
- Master node
- Work node
- Executor
- Tasks
- SparkContext
在Standalone模式下,运行架构如下图所示:
Driver program
Driver program是Spark应用程序的main()函数(创建SparkContext和Spark会话)。运行Driver进程的节点称之为Driver node,Driver进程与集群管理器(Cluster Manager)进行通信,向Executor发送调度的task。
Cluster Manager
称之为集群管理器,主要用于管理集群。常见的集群管理器包括YARN、Mesos和Standalone,Standalone集群管理器包括两个长期运行的后台进程,其中一个是在Master节点,另外一个是在Work节点。在后续集群部署模式篇,将详细探讨这一部分的内容,此处先有有一个大致印象即可。
Worker node
熟悉Hadoop的朋友应该知道,Hadoop包括namenode和datanode节点。Spark也类似,Spark将运行具体任务的节点称之为Worker node。该节点会向Master节点汇报当前节点的可用资源,通常在每一台Worker node上启动一个work后台进程,用于启动和监控Executor。
Executor
Master节点分配资源,使用集群中的Work node创建Executor,Driver使用这些Executor分配运行具体的Task。每一个应用程序都有自己的Executor进程,使用多个线程执行具体的Task。Executor主要负责运行任务和保存数据。
Task
Task是发送到Executor中的工作单元
SparkContext
SparkContext是Spark会话的入口,用于连接Spark集群。在提交应用程序之前,首先需要初始化SparkContext,SparkContext隐含了网络通信、存储体系、计算引擎、WebUI等内容。值得注意的是,一个JVM进程中只能有一个SparkContext,如果想创建新的SparkContext,需要在原来的SparkContext上调用stop()方法。
Spark编程小试牛刀Spark实现分组取topN案例
描述:在HDFS上有订单数据order.txt文件,文件字段的分割符号",",其中字段依次表示订单id,商品id,交易额。样本数据如下:
Order_00001,Pdt_01,222.8Order_00001,Pdt_05,25.8Order_00002,Pdt_03,522.8Order_00002,Pdt_04,122.4Order_00002,Pdt_05,722.4Order_00003,Pdt_01,222.8
问题:使用sparkcore,求每个订单中成交额最大的商品id
实现代码
import org.apache.spark.sql.Rowimport org.apache.spark.sql.hive.HiveContextimport org.apache.spark.sql.types.{StringType, StructField, StructType}import org.apache.spark.{SparkConf, SparkContext}object TopOrderItemCluster { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("top n order and item") val sc = new SparkContext(conf) val hctx = new HiveContext(sc) val orderData = sc.textFile("data.txt") val splitOrderData = orderData.map(_.split(",")) val mapOrderData = splitOrderData.map { arrValue => val orderID = arrValue(0) val itemID = arrValue(1) val total = arrValue(2).toDouble (orderID, (itemID, total)) } val groupOrderData = mapOrderData.groupByKey() /** ***groupOrderData.foreach(x => println(x)) ***(Order_00003,CompactBuffer((Pdt_01,222.8))) ***(Order_00002,CompactBuffer((Pdt_03,522.8), (Pdt_04,122.4), (Pdt_05,722.4))) ***(Order_00001,CompactBuffer((Pdt_01,222.8), (Pdt_05,25.8))) */ val topOrderData = groupOrderData.map(tupleData => { val orderid = tupleData._1 val maxTotal = tupleData._2.toArray.sortWith(_._2 > _._2).take(1) (orderid, maxTotal) } ) topOrderData.foreach(value => println("最大成交额的订单ID为:" + value._1 + " ,对应的商品ID为:" + value._2(0)._1) /** ***最大成交额的订单ID为:Order_00003 ,对应的商品ID为:Pdt_01 ***最大成交额的订单ID为:Order_00002 ,对应的商品ID为:Pdt_05 ***最大成交额的订单ID为:Order_00001 ,对应的商品ID为:Pdt_01 */ ) //构造出元数据为Row的RDD val RowOrderData = topOrderData.map(value => Row(value._1, value._2(0)._1)) //构建元数据 val structType = StructType(Array( StructField("orderid", StringType, false), StructField("itemid", StringType, false)) ) //转换成DataFrame val orderDataDF = hctx.createDataFrame(RowOrderData, structType) // 将数据写入Hive orderDataDF.registerTempTable("tmptable") hctx.sql("CREATE TABLE IF NOT EXISTS orderid_itemid(orderid STRING,itemid STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ''") hctx.sql("INSERT INTO orderid_itemid SELECT * FROM tmptable") }}
将上述代码打包,提交到集群运行,可以进入hive cli或者spark-sql的shell查看Hive中的数据。
总结
本文主要从整体上对Spark进行了介绍,主要包括Spark的搜索热度分析、Spark的主要特点、Spark的一些重要概念以及Spark的运行架构,最后给出了一个Spark编程案例。本文是Spark系列分享的第一篇,可以先感受一下Spark的全局面貌,下一篇将分享Spark Core编程指南。









 京公网安备 11010802041100号
京公网安备 11010802041100号