从本篇文章开始,将开启 spark 学习和总结之旅,专门针对如何提高 spark 性能进行总结,力图总结出一些干货。
无论你是从事算法工程师,还是数据分析又或是其他与数据相关工作,利用 spark 进行海量数据处理和建模都是非常重要和必须掌握的一门技术,我感觉编写 spark 代码是比较简单的,特别是利用 Spark SQL 下的 DataFrame 接口进行数据处理,只要有 python 基础都是非常容易入门的,但是在性能调优上,许多人都是一知半解,写的 spark 程序经常陷入 OOM 或卡死状态。这时深入了解 spark 原理就显得非常有必要了。
本系列总结主要针对 Hadoop YARN 模式。
RDD(Resilient Distributed Datasets)
RDD 是 spark 中最基本的数据抽象,存储在 exector 或 node 中,它代表一个 “惰性,”“静态”,“不可变”,“分布式“的数据集合,RDD 基本介绍在网上上太多了,这里就不做详细介绍了,主要讲下以下内容:
transform(转换)与 action(执行)的区别
转换操作:返回的是一个新的 RDD,常见的如:map、filter、flatMap、groupByKey 等等
执行操作:返回的是一个结果,一个数值或者是写入操作等,如 reduce、collect、count、first 等等
惰性计算
spark 中计算 RDD 是惰性的,也即 RDD 真正被计算(执行操作,例如写入存储操作、collect 操作等)时,其转换操作才会真正被执行。 spark 为什么采用惰性计算:
spark 为什么采用惰性计算:
在 MapReduce 中,大量的开发人员浪费在最小化 MapReduce 通过次数上。通过将操作合并在一起来实现。在 Spark 中,我们不创建单个执行图,而是将许多简单的操作结合在一起。因此,它造成了 Hadoop MapReduce 与 Apache Spark 之间的差异。
惰性设计的好处:
① 提高可管理性
可以查看整个 DAG(将对数据执行的所有转换的图形),并且可以使用该信息来优化计算。
② 降低时间复杂度和加快计算速度
只运算真正要计算的转换操作,并且可以根据 DAG 图,合并不需要与 drive 通信的操作(连续的依赖转换),例如在一个 RDD 上同时调用 map 和 filter 转换操作,spark 可以将 map 和 filter 指令发送到每个 executor 上,spark 程序在真正执行 map 和 filter 时,只需访问一次 record,而不是发送两组指令并两次访问分区。理论上相对于非惰性,将时间复杂度降低了一半。例如:
val list1 = list.map(i -> i * 3) // Transformation1
val list2 = list1.map(i -> i + 3) // Transformation1
val list3 = list1.map(i -> i / 3) // Transformation1
list3.collect() // ACTION
假设原始列表(list) 很大,其中包含数百万个元素。如果没有懒惰的评估,我们将完成三遍如此庞大的计算。如果我们假设一次这样的列表迭代需要 10 秒,那么整个评估就需要 30 秒。并且每个 RDD 都会缓存下来,浪费内存。使用惰性评估,Spark 可以将这三个转换像这样合并到一个转换中,如下:
val list3 = list.map(i -> i + 1)
它将只执行一次该操作。只需一次迭代即可完成,这意味着只需要 10 秒的时间。
容错性
RDD 本身包含其复制所需的所有依赖信息,一旦该 RDD 中某个分区丢失了,该 RDD 有足够需要重新计算的信息,可以去并行的,很快的重新计算丢失的分区。
运行在内存
在 spark application 的生命周期中,RDD 始终常驻内存(在所在的节点内存),这也是其比 MapReduce 更快的重要原因。
spark 中提供了三种内存管理机制:
① in-memory as deserialized data
这种常驻内存方式速度快(因为去掉了序列化时间),但是内存利用效率低。
② in-memory as serialized data
该方法内存利用效率高,但是速度慢
③ 直接存在 disk 上
对于那些较大容量的 RDD,没办法直接存在内存中,需要写入到 DISK 上。该方法仅适用于大容量 RDD。要持久化一个 RDD,只要调用其 cache()或者 persist()方法即可。在该 RDD 第一次被计算出来时,就会直接缓存在每个节点中。而且 Spark 的持久化机制还是自动容错的,如果持久化的 RDD 的任何 partition 丢失了,那么 Spark 会自动通过其源 RDD,使用 transformation 操作重新计算该 partition。
cache()和 persist()的区别在于,cache()是 persist()的一种简化方式,cache()的底层就是调用的 persist()的无参版本,同时就是调用 persist(MEMORY_ONLY),将数据持久化到内存中。如果需要从内存中清楚缓存,那么可以使用 unpersist()方法。
我们来仔细分析下持久化和非持久化的区别:
非持久化: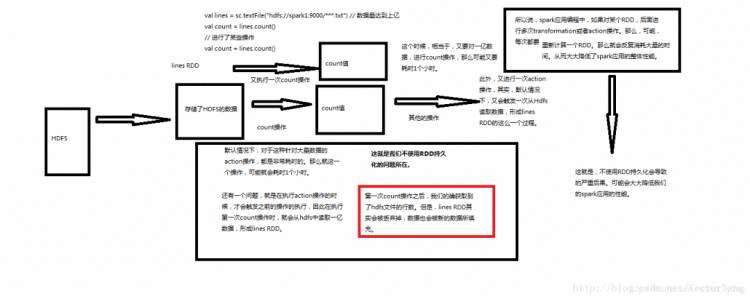 持久化:
持久化: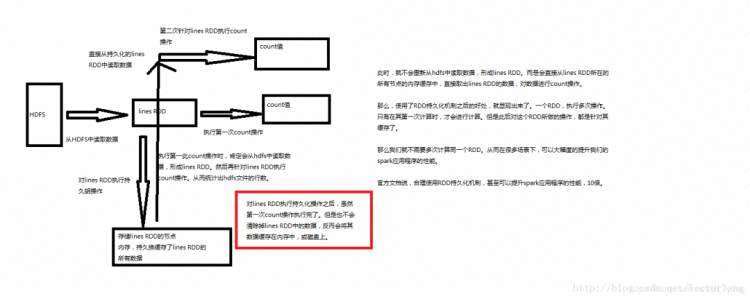
显然对于要复用多次的 RDD,要将其进行持久化操作,此时 Spark 就会根据你的持久化策略,将 RDD 中的数据保存到内存或者磁盘中。以后每次对这个 RDD 进行算子操作时,都会直接从内存或磁盘中提取持久化的 RDD 数据,然后执行算子,而不会从源头处重新计算一遍这个 RDD,再执行算子操作。 所以在写 spark 代码时:尽可能复用同一个 RDD。
这里常有个误区:
val rdd1 = ... // 读取hdfs数据,加载成RDD
rdd1.cache // 持久化操作
val rdd2 = rdd1.map(...)
val rdd3 = rdd1.filter(...)
rdd1.unpersist // 释放缓存
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
如果按上述代码进行持久化,则效果就如同没有持久化一样。原因就在于 spark 的 lazy 计算。
代码应该如下:
val rdd1 = ... // 读取hdfs数据,加载成RDD
rdd1.cache
val rdd2 = rdd1.map(...)
val rdd3 = rdd1.filter(...)
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
rdd1.unpersist
rdd2 执行 take 时,会先缓存 rdd1,接下来直接 rdd3 执行 take 时,直接利用缓存的 rdd1,最后,释放掉 rdd1。所以在何处释放 RDD 也是非常需要细心的。 请在 action 之后 unpersisit!!!
Spark Job Scheduling
窄依赖 与 宽依赖
shuffle 过程,简单来说,就是将分布在集群中多个节点上的同一个 key,拉取到同一个节点上,进行聚合或 join 等操作。比如 reduceByKey、join 等算子,都会触发 shuffle 操作。shuffle 操作需要将数据进行重新聚合和划分,然后分配到集群的各个节点上进行下一个 stage 操作,这里会涉及集群不同节点间的大量数据交换。由于不同节点间的数据通过网络进行传输时需要先将数据写入磁盘,因此集群中每个节点均有大量的文件读写操作,从而导致 shuffle 操作十分耗时(相对于 map 操作)。
窄依赖:父 RDD 与 子 RDD 的分区是一对一(map 操作)或多对一(coalesce)的,不会有 shuffle 过程;并且子 RDD 的分区结果与其 key 和 value 值无关,每个分区与其他分区亦无关。
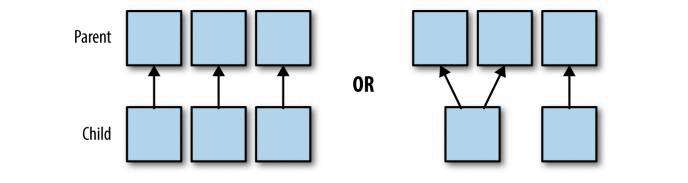 上面左图可对应 map 操作分区,右图对应 coalesce 操作。
上面左图可对应 map 操作分区,右图对应 coalesce 操作。
宽依赖:父 RDD 与子 RDD 的分区是一对多的关系,并且是按一定方式进行重分区,会有 shuffle 过程产生,比较耗时,可能会引发 spark 性能问题。常见的宽依赖操作如:groupByKey、reduceByKey、sort、sortByKey 等等。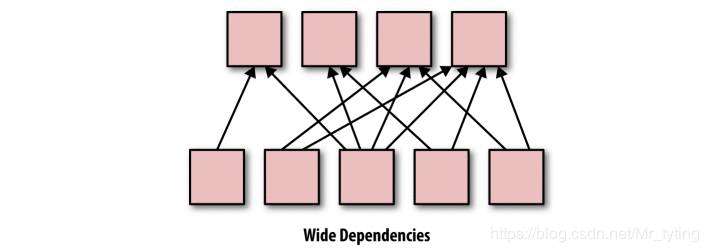 注意:coalesce 操作如果是将 10 个分区换成 100 个分区,由少分区转成大分区将会发生 shuffle 过程。coalesce 操作场景主要是 rdd 经过多层过滤后的小文件合并。rdd 的 reparation 方法与 coalesce 相反,主要是为了 处理数据倾斜,增加 partiton 的数量使得每个 task 处理的数据量减少,肯定会有 shuffle 过程产生(repartition 其实调用的就是 coalesce,只不过 shuffle = true (coalesce 中 shuffle: Boolean = false))。
注意:coalesce 操作如果是将 10 个分区换成 100 个分区,由少分区转成大分区将会发生 shuffle 过程。coalesce 操作场景主要是 rdd 经过多层过滤后的小文件合并。rdd 的 reparation 方法与 coalesce 相反,主要是为了 处理数据倾斜,增加 partiton 的数量使得每个 task 处理的数据量减少,肯定会有 shuffle 过程产生(repartition 其实调用的就是 coalesce,只不过 shuffle = true (coalesce 中 shuffle: Boolean = false))。
Spark Application
一个 spark 应用主要由一系列的 spark Job 组成,而这些 spark Job 由 sparkContext 定义而来。当 SparkContent 启动时,一个 driver 和一系列的 executor 会在集群的工作节点上启动。每个 executor 都有个 JVM 虚拟环境,一个 executor 不能跨越多个节点。
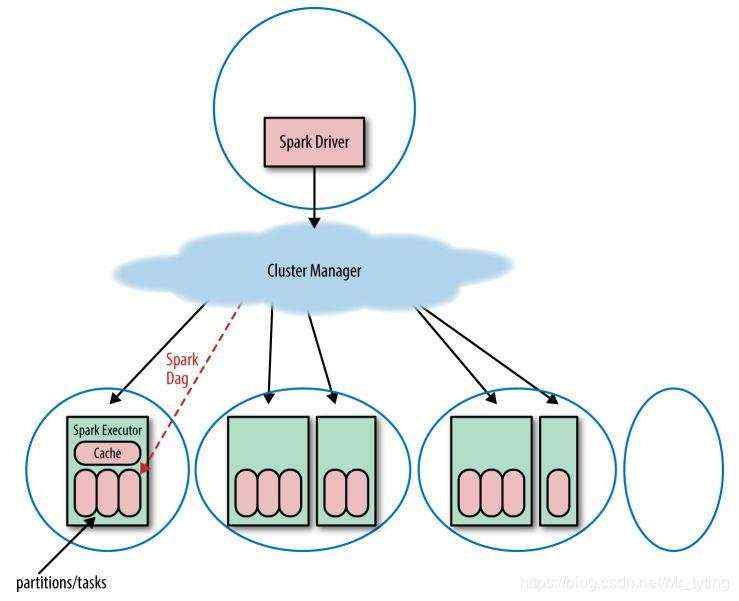 上图表示在一个分布式系统上启动一个 spark application 的物理硬件层面流程。
上图表示在一个分布式系统上启动一个 spark application 的物理硬件层面流程。
- 驱动程序(driver program)会定义一个集群管理(cluster manager)
- cluster manager 会在工作节点上启动一些 executor,运行提交的代码(注意:一个节点 node 上会有多个 executor,但是一个 executor 不能跨越多个 node)
需要注意以下两点:
- 一个节点 node 上会有多个 executor,但是一个 executor 不能跨越多个 node
- 每个 executor 会有多个分区,但是一个分区不能跨越多个 executor
DAG(Directed Acyclic Graph)详解
spark Application tree
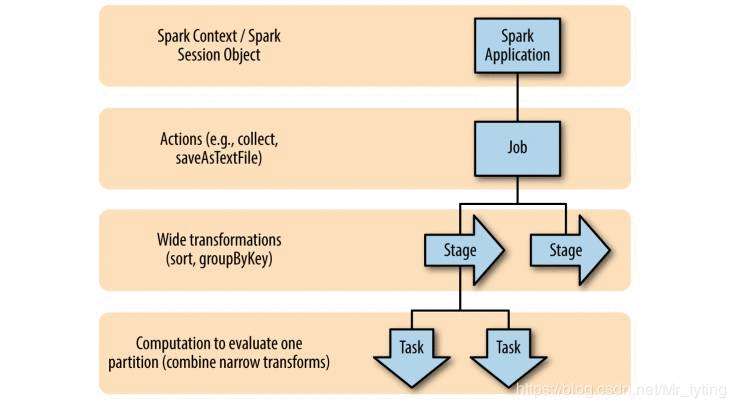 简而言之:一个 spark Application 由多个 Job 组成,Job 由提交代码中的 Action 操作定义,而一个 Action 操作由多个 Stage 组成,Stage 的分割由宽依赖进行分割的,而每个 Stage 又由多个 Task 组成。一个 Task 对应一个分区,一个 task 会被分配到一个 executor 上执行。
简而言之:一个 spark Application 由多个 Job 组成,Job 由提交代码中的 Action 操作定义,而一个 Action 操作由多个 Stage 组成,Stage 的分割由宽依赖进行分割的,而每个 Stage 又由多个 Task 组成。一个 Task 对应一个分区,一个 task 会被分配到一个 executor 上执行。
每个 Job 都对应一个 DAG 图,每个 DAG 有一系列的 Stage 组成。
- Job:每个 Job 对应一个 Action 操作,在 spark execution Graph 中,其边是基于代码中的 transform 操作的依赖关系定义的。
- Stages:每个 Action 中可能包含一个或多个 transform 操作,其中宽依赖又将 Job 划分成多个 Stage。因为 Stages 的边缘需要和 driver 进行通信,故通常一个 Job 里,必须顺序的执行 Stages 而非并行。并且会将多个窄依赖步骤合并成一个步骤,因为其中没有的转换操作没有 shuffle 过程,可以通过只访问一次数据,连续执行多个 transform 操作,这也是上面提到的惰性计算的优点。
def simpleSparkProgram(rdd : RDD[Double]): LOng={
//stage1
rdd.filter(_<1000.0)
.map(x => (x, x) )
//stage2
.groupByKey()
.map{ case(value, groups) => (groups.sum, value)}
//stage 3
.sortByKey()
.count()
}
其代码中对应的 Stage 如下: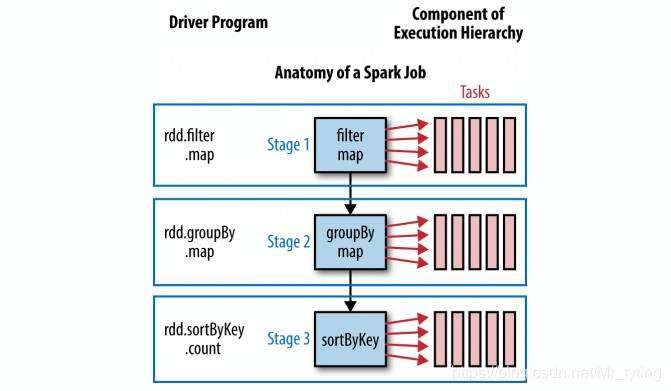
- Task:task 是 spark 中最小最基本的执行单元,每个 task 代表一个局部的计算任务。在 executor 中可以有多个 core,而每个 core 可以对应一个 task,每个 task 针对一个分区。 每次针对不同的一块分区,执行相同的代码。
注意:
- spark 中同时并行的 task 数量不能超过所有 executor core 数量。 其中 所有 executor cores 数量= 每个 executor 中 core 数量 * executor 数量。
- task 的并行化是有 executor 数量 × core 数量决定的。task 过多,并行化过小,就会浪费时间;反之就会浪费资源。所以设置参数是一个需要权衡的过程,原则就是在已有的资源情况下,充分利用内存和并行化。
总结
对于 DAG 的深刻理解非常重要,如果理解不深刻则可能定位问题的效率不高。比如常见的数据倾斜。当理解了这些,如果出现了数据倾斜,可以分析 job,stage 和 task,找到部分 task 输入的严重不平衡,最终定位是数据问题或计算逻辑问题。
参考
- https://www.quora.com/What-is-the-reason-behind-keeping-lazy-evaluation-in-Apache-Spark
- https://data-flair.training/blogs/apache-spark-lazy-evaluation/
- http://bourneli.github.io/scala/spark/2016/06/17/spark-unpersist-after-action.html



![Spark中使用map或flatMap将DataSet[A]转换为DataSet[B]时Schema变为Binary的问题及解决方案](https://img6.php1.cn/3cdc5/9b0d/243/f27d40b3b7e4b51b.png)



 京公网安备 11010802041100号
京公网安备 11010802041100号