原文地址:http://blog.csdn.net/hjimce/article/details/50098483
作者:hjimce
一、相关理论
本篇博文主要讲解2015年CVPR的一篇关于图像相似度计算的文章:《Learning to Compare Image Patches via Convolutional Neural Networks》,本篇文章对经典的算法Siamese Networks 做了改进。学习这篇paper的算法,需要熟悉Siamese Networks(经典老文献《Signature Verification Using a Siamese Time Delay Neural Network》)、以及大神何凯明提出来的空间金字塔池化(2015年CVPR 文献《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》),因为文献基本上是在 Siamese Networks的基础上做修改,然后也要借助于空间金字塔池化实现不同大小图片的输入网络。
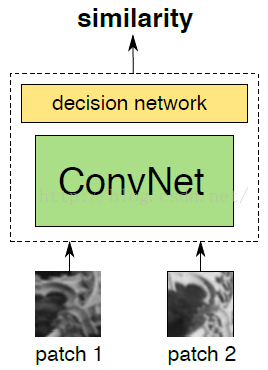
网络总结构
如上图所示,我们的目的是比较两幅图片是否相似,或者说相似度是多少,因此我们构建的卷积神经网络模型的输入就是:两幅图片,然后网络的输出是一个相似度数值。其实我觉得,用“计算相似度”这个词有点不合适,我觉得应该翻译为匹配程度。因为文献所采用的训练数据中,如果两张图片匹配,输出值标注为y=1,如果两张图片不匹配,那么训练数据标注为y=-1,也就是说,这个训练数据的标注方法,根本就不是一个相似度数值,而是一个是否匹配的数值。我们打个比方,有三样物体:钢笔、铅笔、书包,那么在训练数据中,就把钢笔和铅笔标注为y=1,而不是用一个相似度数值来衡量,比我钢笔和铅笔的相似度我们把它标注为y=0.9……,所以说用于用相似度这个词有点不合理,即使我们最后计算出来的值是一个-1~1之间的数……
paper主要创新点:在创新点方面,我觉得主要是把Siamese 网络的双分支,合在一起,从而提高了精度,如下图所示

Siamese 网络
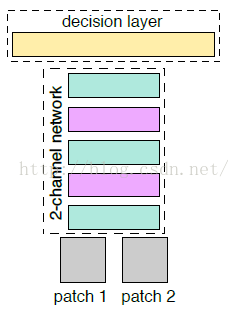
paper算法2-channel 网络
先在这里解释下为什么作者要把它称之为:2-channel networks。理解了2-channel这个词,有助于我们后面理解算法。从上面Siamese 网络,我们可以看到这个网络有两个分支组成,因为我们是要比较两张图片patch1、patch2的相似度,所以Siamese 网络的大体思路,就是让patch1、patch2分别经过网络,进行提取特征向量,然后在最后一层对两个两个特征向量做一个相似度损失函数,进行网络训练,这个后面在给进行比较详细的讲解,总的来说Siamese 对于两张图片patch1、patch2的特征提取过程是相互独立的,我们也可以把Siamese 网络称之为“2-branches networks”。那么paper所提出的算法:2-channel networks 又是什么意思呢?本来patch1、patch2是两张单通道灰度图像、它们各不相干,于是作者的想法就是把patch1、patch2合在一起,把这两张图片,看成是一张双通道的图像。也就是把两个(1,64,64)单通道的数据,放在一起,成为了(2,64,64)的双通道矩阵,然后把这个矩阵数据作为网络的输入,这就是所谓的:2-channel。
OK,这就是文献的主要创新点,懂得了这个,后面看paper就容易多了,可以说已经把paper的总思路领悟了一半了,是不是感觉貌似很简单的样子。
二、Siamese网络相关理论
本部分是为了了解经典的Siamese网络,如果已经知道Siamese网络的结构的,请跳过这一部分。
1、《Learning a similarity metric discriminatively, with application to face verification》
Siamese网络:这个是一个曾经用于签字认证识别的网络,也就是我们平时说笔迹识别。这个算法可以用于判断签名笔迹,n年前的一个算法。算法的原理利用神经网络提取描述算子,得到特征向量,然后利用两个图片的特征向量判断相似度,这个有点像sift,只不过是利用CNN进行提取特征,并且用特征向量进行构造损失函数,进行网络训练。下面引用2005年CVPR上的一篇文献《Learning a similarity metric discriminatively, with application to face verification》,进行简单讲解,这篇paper主要是利用Siamese网络做人脸相似度判别,可以用于人脸识别哦,因为我觉得这篇文献的网络结构图画的比较漂亮,比较容易看懂,所以就用这一篇文章,简单讲解Siamese网络的思想。其网络如下图所示,有两个分支分别输入图片x1、x2(须知:这两个分支其实是相同的,同一个cnn模型,同样的参数,文献只是为了方便阅读,所以才画成两个分支,因为他们采用的是权重共享),包含卷积、池化等相关运算。双分支有点难理解,我们还是用单分支来理解吧,说的简单一点把,siamese 网络分成前半部分、后半部分。前半部分用于特征提取,我们可以让两张图片,分别输入我们这个网络的前半部分,然后分别得到一个输出特征向量Gw(x1)、Gw(x2),接着我们构造两个特征向量距离度量,作为两张图片的相似度计算函数(如公式1所示)。

Siamese网络
如上图所示,我们要判断图片X1和X2是否相似,于是我们构建了一个网络映射函数Gw(x),然后把x1、x2分别作为参数自变量,我们可以得到Gw(x1)、Gw(x2),也就是得到用于评价X1、X2是否相似的特征向量。然后我们的目的就是要使得函数:
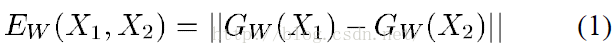
然后利用这个损失函数,对网络进行训练,就可以判别两张人脸的相似度了。上面过程中网络的两个分支所用的是同一个函数,也就是权值、网络结构是同一个,我们完全可以把Gw(x)看成是一个特征提取器,因此siamese network网络其实就是一个提取一直图片的特征算子的过程,然后再网络的最后一层,是用于定义了特征向量间相似度的损失函数。
2、Siamese网络
OK,我们回到本篇博文的主题,下面是paper所用的Siamese网络(shared weights)。在网络的最后顶层,由线性全连接和ReLU激活函数,构成输出层。在paper中,采用的最后是包含两个全连接层,每个隐层包含512个神经元。

除了Siamese网络,文献还提了另外一种Pseudo-siamese网络,这个网络与siamese network网络最大的区别在于两个分支是权值不共享的,是真正的双分支网络模型。Pseudo-siamese在网络的两个分支上,每个分支是不同的映射函数,也就是说它们提取特征的结构是不一样的,左右两个分支,有不同的权值、或者不同的网络层数等,两个函数互不相关,只是在最后的全连接层,将他们连接在一起了。这个网络相当于训练参数比Siamese网络的训练参数多了将近一倍,当然它比Siamese网络更加灵活。
其实到了这里,我们提到了原始的Siamese、以及Pseudo-siamese,都只是为了衬托后面作者所提出的算法:2-channel networks,因为最后我们要做算法精度对比,所以作者就啰嗦了这么多。这一部分我觉得啰嗦的太多反而会乱掉,所以还是不细讲,以为这个不是重点。下面要讲解的2-channel 网络才是paper的主要创新点,所以才是我们需要好好细读的部分。因为paper的讲解方法,是根据一步一步改进网络的,所以我就根据文献的思路进行讲解,以siamese network为基础:paper首先提出了把siamese 改成2-channel ,这个是第一次对算法的进化,提高了精度。接着提出Central-surround two-stream network,这个算法只是在网络的输入上做了改变,没有改变网络的结构,可以与2-channel、siamese 结合在一起,提高精度
三、第一次进化,从siamese 到2-channel (创新点1)
网络总体结构,2-channel:与前面讲的Siamese网络、Pseudo-siamese网络本质上每个分支就相当于一个特征提取的过程,然后最后一层就相当计算特征向量相似度的函数一样。于是接着作者提出了2-channel网络结构,跳过了分支的显式的特征提取过程,而是直接学习相似度评价函数。双通道网络结构,就相当于把输入的两张灰度图片看成是一张双通道的图片一样。
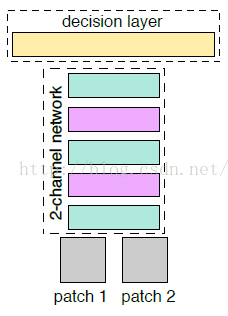
这样算法的最后一层直接是全连接层,输出神经元个数直接为1,直接表示两张图片的相似度。直接用双通道图片进行训练会比较快,比较方便,当然CNN,如果输入的是双通道图片,也就是相当于网络的输入的是2个feature map,经过第一层的卷积后网,两张图片的像素就进行了相关的加权组合并映射,这也就是说,用2-channel的方法,经过了第一次的卷积后,两张输入图片就不分你我了。而Siamese网络是到了最后全连接的时候,两张图片的相关神经元才联系在一起,这就是2-channel 与Siamese给我感觉最大的区别。这个作者后面通过试验,验证了从第一层开始,就把两张图片关联在一起的好处,作者的原话:This is something that indicates that it is important to jointly use information from both
patches right from the first layer of the network.
这边顺便提一下文献的一个网络架构细节,卷积核大小:Paper所有的卷积核大小都是采用3*3的,因为在《Very Deep Convolutional Networks for Large-Scale Image Recognition》文献中提到,对于小的卷积核来说,比大尺寸的卷积核有更多的非线性,效果更牛逼,总之就是以后遇到CNN,建议用卷积核比较小的,好处多多。
四、第二次进化,结合Central-surround two-stream network(创新点2)
这个创新点,需要对上面的网络结构稍作修改。假设我们输入的是大小为64*64的一张图片,那么Central-surround two-stream network的意思就是把图片64*64的图片,处理成两张32*32图片,然后再输入网络,那么这两张32*32的图片是怎么计算得到的?这就是Central-surround方法,也就是第一张图片是通过以图片中心,进行裁剪出32*32的图片,也就是下图的浅蓝色区域的图片。

那么第二张图片是怎么计算的:这张图片是直接通过对整张图片下采样的方法得到的,也就是说直接把64*64的图片进行下采样得到32*32的图片。那么作者为什么要把一张64*64的图片,拆分成两张32*32的图片。其实这个就像多尺度一样,在图片处理领域经常采用多分辨率、多尺度,比如什么sift、还有什么高斯金字塔什么的,总之作者说了,多分辨率可以提高两张图片的match效果。这个Central-surround two-stream network可以和上面提到的2-channel、Siamese结合在一起,提高精度。下面就是Siamese和Central-surround two-stream network结合在一起的网络结构:

上面是Siamese网络模型,利用Central-surround two-stream network构建新的网络模型,就是在网络输入部分,把输入图片改成多尺度输入。
五、第三次进化,结合空间金字塔池化SPP
空间金字塔池化采样:这个又称之为SPP(Spatial pyramid pooling)池化,这个又什么用呢?这个跟上面的有点类似,这个其实就类似于多图片多尺度处理,我们知道现有的卷积神经网络中,输入层的图片的大小一般都是固定的,这也是我之前所理解的一个神经网络。直到知道SPP,感觉视觉又开阔了许多,菜鸟又长见识了。我们知道现在的很多算法中,讲到的训练数据图片的大小,都是什么32*32,96*96,227*227等大小,也就是说训练数据必须归一化到同样的大小,那么假设我的训练数据是各种各样的图片大小呢?我是否一定要把它裁剪成全部一样大小的图片才可以进入卷积神经网络训练呢?这就是SPP算法所要解决的问题,训练数据图片不需要归一化,而且江湖传说,效果比传统的方法的效果还好。下面是Siamese和SPP结合在一起的网络结构:
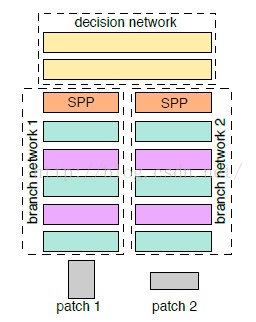
就是在全连接层的前面加了个SPP层。
关于SPP池化方法,大牛何凯明发表了好几篇文章《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》、《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,SSP的相关实现以后再进行讲解,一篇博文一口气如果讲的太多,看着也会觉得累。
总之这一步是为了使得网络可以输入各种大小的图片,提高网络的实用性,鲁棒性等。
OK,经过上面的三次进化,网络最后的结构,也就是精度最高,paper最后的算法就是:2-channel+Central-surround two-stream+SPP 的网络结构,因为文献没有把这个网络的结构图画出来,我也懒得画,所以不能给大家提供最后的网络结构图。
六、网络训练
首先paper采用了如下损失函数:
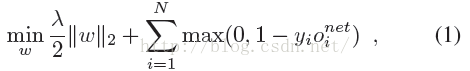
公式第一部分就是正则项,采用L2正则项。第二部分误差损失部分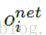 是网络第i对训练图片的输出神经元,然后yi的取值是-1或1,当输入图片是matching的时候,为1,当non-matching的时候是-1。
是网络第i对训练图片的输出神经元,然后yi的取值是-1或1,当输入图片是matching的时候,为1,当non-matching的时候是-1。
参数训练更新方法采用ASGD,其学习率恒为1.0,动量参数选择0.9,然后权重衰减大小选择:
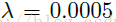
训练的min-batch大小选择128。权重采用随机初始化方法。
OK,上面是一些网络参数设置。接着就是数据处理部分了,一般就是数据扩充,也就是给图片加上旋转、镜像、等操作。Paper采用的数据扩充,包含水平翻转、垂直翻转、还有就是旋转,包含90、180、270角度的旋转。训练迭代终止的方法不是采用什么early stop,而是启动让电脑跑个几天的时间,等到闲的时候,回来看结果,做对比(ps:这个有点low)。如果你是刚入门CNN的,还没听过数据扩充,可以看看:http://blog.csdn.net/tanhongguang1/article/details/46279991。Paper也是采用了训练过程中,随机数据的扩充的方法。
参考文献:
1、《Learning to Compare Image Patches via Convolutional Neural Networks》
2、《Discriminative Learning of Local Image Descriptors》
3、《signature verification using a siamese time delay neural network_bromley》
4、《Learning visual similarity for product design with convolutional neural networks》
5、《Learning a similarity metric discriminatively, with application to face verification》
**********************作者:hjimce 时间:2015.10.25 联系QQ:1393852684 原创文章,转载请保留原文地址、作者等信息***************



 京公网安备 11010802041100号
京公网安备 11010802041100号