摘要:WeNet是一款开源端到端ASR工具包,它与ESPnet等开源语音项目相比,最大的优势在于提供了从训练到部署的一整套工具链,使ASR服务的工业落地更加简单。
本文分享自华为云社区《WeNet云端推理部署代码解析》,作者:xiaoye0829 。
WeNet是一款开源端到端ASR工具包,它与ESPnet等开源语音项目相比,最大的优势在于提供了从训练到部署的一整套工具链,使ASR服务的工业落地更加简单。如图1所示,WeNet工具包完全依赖于PyTorch生态:使用TorchScript进行模型开发,使用Torchaudio进行动态特征提取,使用DistributedDataParallel进行分布式训练,使用torch JIT(Just In Time)进行模型导出,使用LibTorch作为生产环境运行时。本系列将对WeNet云端推理部署代码进行解析。

图1:WeNet系统设计[1]
WeNet云端推理和部署代码位于wenet/runtime/server/x86路径下,编程语言为C++,其结构如下所示:

其中:
WeNet提供了CMakeLists.txt和Dockerfile,使得用户能方便地进行项目编译和镜像构建。
WeNet只支持44字节header的wav格式音频数据,wav header定义在WavHeader结构体中,包括音频格式、声道数、采样率等音频元信息。WavReader类用于语音文件读入,调用fopen打开语音文件后,WavReader先读入WavHeader大小的数据(也就是44字节),再根据WavHeader中的元信息确定待读入音频数据的大小,最后调用fread把音频数据读入buffer,并通过static_cast把数据转化为float类型。
struct WavHeader { char riff[4]; // "riff" unsigned int size; char wav[4]; // "WAVE" char fmt[4]; // "fmt " unsigned int fmt_size; uint16_t format; uint16_t channels; unsigned int sample_rate; unsigned int bytes_per_second; uint16_t block_size; uint16_t bit; char data[4]; // "data" unsigned int data_size; };这里存在的一个风险是,如果WavHeader中存放的元信息有误,则会影响到语音数据的正确读入。
WeNet使用的特征是fbank,通过FeaturePipelineConfig结构体进行特征设置。默认帧长为25ms,帧移为10ms,采样率和fbank维数则由用户输入。
用于特征提取的类是FeaturePipeline。为了同时支持流式与非流式语音识别,FeaturePipeline类中设置了input_finished_属性来标志输入是否结束,并通过set_input_finished()成员函数来对input_finished_属性进行操作。
提取出来的fbank特征放在feature_queue_中,feature_queue_的类型是BlockingQueue
通过torch::jit::load对存在磁盘上的模型进行反序列化,得到一个ScriptModule对象。
torch::jit::script::Module model = torch::jit::load(model_path);WeNet推理支持的解码方式都继承自基类SearchInterface,如果要新增解码算法,则需继承SearchInterface类,并提供该类中所有纯虚函数的实现,包括:
// 解码算法的具体实现 virtual void Search(const torch::Tensor& logp) = 0; // 重置解码过程 virtual void Reset() = 0; // 结束解码过程 virtual void FinalizeSearch() = 0; // 解码算法类型,返回一个枚举常量SearchType virtual SearchType Type() cOnst= 0; // 返回解码输入 virtual const std::vector>& Inputs() cOnst= 0; // 返回解码输出 virtual const std::vector>& Outputs() cOnst= 0; // 返回解码输出对应的似然值 virtual const std::vector& Likelihood() cOnst= 0; // 返回解码输出对应的次数 virtual const std::vector>& Times() cOnst= 0; 目前WeNet只提供了SearchInterface的两种子类实现,也即两种解码算法,分别定义在CtcPrefixBeamSearch和CtcWfstBeamSearch两个类中。
WeNet支持语音端点检测,提供了一种基于规则的实现方式,用户可以通过CtcEndpointConfig结构体和CtcEndpointRule结构体进行规则配置。WeNet默认的规则有三条:
WeNet提供的解码器定义在TorchAsrDecoder类中。如图3所示,WeNet支持双向解码,即叠加从左往右解码和从右往左解码的结果。在CTC beam search之后,用户还可以选择进行attention重打分。

图2:WeNet解码计算流程[2]
可以通过DecodeOptions结构体进行解码参数配置,包括如下参数:
struct DecodeOptions { int chunk_size = 16; int num_left_chunks = -1; float ctc_weight = 0.0; float rescoring_weight = 1.0; float reverse_weight = 0.0; CtcEndpointConfig ctc_endpoint_config; CtcPrefixBeamSearchOptions ctc_prefix_search_opts; CtcWfstBeamSearchOptions ctc_wfst_search_opts; };其中,ctc_weight表示CTC解码权重,rescoring_weight表示重打分权重,reverse_weight表示从右往左解码权重。最终解码打分的计算方式为:
final_score = rescoring_weight * rescoring_score + ctc_weight * ctc_score; rescoring_score = left_to_right_score * (1 - reverse_weight) + right_to_left_score * reverse_weightTorchAsrDecoder对外提供的解码接口是Decode(),重打分接口是Rescoring()。Decode()返回的是枚举类型DecodeState,包括三个枚举常量:kEndBatch,kEndpoint和kEndFeats,分别表示当前批数据解码结束、检测到端点、所有特征解码结束。
为了支持长语音识别,WeNet还提供了连续解码接口ResetContinuousDecoding(),它与解码器重置接口Reset()的区别在于:连续解码接口会记录全局已经解码的语音帧数,并保留当前feature_pipeline_的状态。
由于流式ASR服务需要在客户端和服务端之间进行双向的流式数据传输,WeNet实现了两种支持双向流式通信的服务化接口,分别基于WebSocket和gRPC。
WebSocket是基于TCP的一种新的网络协议,与HTTP协议不同,WebSocket允许服务器主动发送信息给客户端。 在连接建立后,客户端和服务端可以连续互相发送数据,而无需在每次发送数据时重新发起连接请求。因此大大减小了网络带宽的资源消耗 ,在性能上更有优势。
WebSocket支持文本和二进制两种格式的数据传输 。
WeNet使用了boost库的WebSocket实现,定义了WebSocketClient(客户端)和WebSocketServer(服务端)两个类。
在流式ASR过程中,WebSocketClient给WebSocketServer发送数据可以分为三个步骤:1)发送开始信号与解码配置;2)发送二进制语音数据:pcm字节流;3)发送停止信号。从WebSocketClient::SendStartSignal()和WebSocketClient::SendEndSignal()可以看到,开始信号、解码配置和停止信号都是包装在json字符串中,通过WebSocket文本格式传输。pcm字节流则通过WebSocket二进制格式进行传输。
void WebSocketClient::SendStartSignal() { // TODO(Binbin Zhang): Add sample rate and other setting surpport json::value start_tag = {{"signal", "start"}, {"nbest", nbest_}, {"continuous_decoding", continuous_decoding_}}; std::string start_message = json::serialize(start_tag); this->SendTextData(start_message); } void WebSocketClient::SendEndSignal() { json::value end_tag = {{"signal", "end"}}; std::string end_message = json::serialize(end_tag); this->SendTextData(end_message); }WebSocketServer在收到数据后,需要先判断收到的数据是文本还是二进制格式:如果是文本数据,则进行json解析,并根据解析结果进行解码配置、启动或停止,处理逻辑定义在ConnectionHandler::OnText()函数中。如果是二进制数据,则进行语音识别,处理逻辑定义在ConnectionHandler::OnSpeechData()中。
WebSocket需要开发者在WebSocketClient和WebSocketServer写好对应的消息构造和解析代码,容易出错。另外,从以上代码来看,服务需要借助json格式来序列化和反序列化数据,效率没有protobuf格式高。
对于这些缺点,gRPC框架提供了更好的解决方法。
gRPC是谷歌推出的开源RPC框架,使用HTTP2作为网络传输协议,并使用protobuf作为数据交换格式,有更高的数据传输效率。在gRPC框架下,开发者只需通过一个.proto文件定义好RPC服务(service)与消息(message),便可通过gRPC提供的代码生成工具(protoc compiler)自动生成消息构造和解析代码,使开发者能更好地聚焦于接口设计本身。
进行RPC调用时,gRPC Stub(客户端)向gRPC Server(服务端)发送.proto文件中定义的Request消息,gRPC Server在处理完请求之后,通过.proto文件中定义的Response消息将结果返回给gRPC Stub。
gRPC具有跨语言特性,支持不同语言写的微服务进行互动,比如说服务端用C++实现,客户端用Ruby实现。protoc compiler支持12种语言的代码生成。
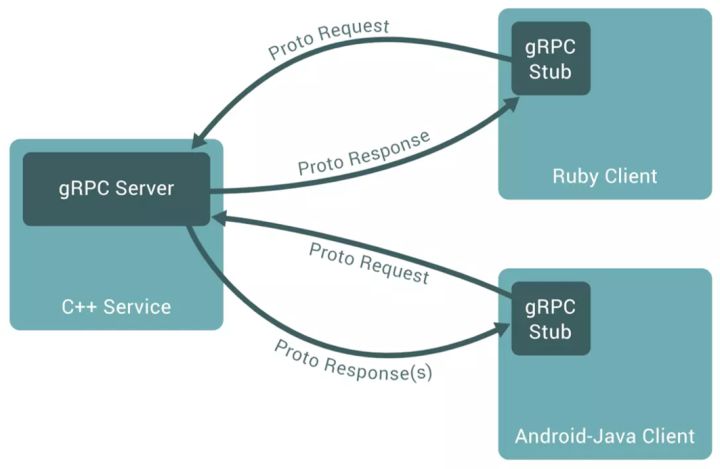
图1:gRPC Server和gRPC Stub交互[1]
WeNet定义的服务为ASR,包含一个Recognize方法,该方法的输入(Request)、输出(Response)都是流式数据(stream)。在使用protoc compiler编译proto文件后,会得到4个文件:wenet.grpc.pb.h,http://wenet.grpc.pb.cc,wenet.pb.h,http://wenet.pb.cc。其中,wenet.pb.h/cc中存储了protobuf数据格式的定义,wenet.grpc.pb.h中存储了gRPC服务端/客户端的定义。通过在代码中包括wenet.pb.h和wenet.grpc.pb.h两个头文件,开发者可以直接使用Request消息和Response消息类,访问其字段。
service ASR { rpc Recognize (stream Request) returns (stream Response) {} } message Request { message DecodeConfig { int32 nbest_cOnfig= 1; bool continuous_decoding_cOnfig= 2; } oneof RequestPayload { DecodeConfig decode_cOnfig= 1; bytes audio_data = 2; } } message Response { message OneBest { string sentence = 1; repeated OnePiece wordpieces = 2; } message OnePiece { string word = 1; int32 start = 2; int32 end = 3; } enum Status { ok = 0; failed = 1; } enum Type { server_ready = 0; partial_result = 1; final_result = 2; speech_end = 3; } Status status = 1; Type type = 2; repeated OneBest nbest = 3; }WeNet gRPC服务端定义了GrpcServer类,该类继承自wenet.grpc.pb.h中的纯虚基类ASR::Service。
语音识别的入口函数是GrpcServer::Recognize,该函数初始化一个GRPCConnectionHandler实例来进行语音识别,并通过ServerReaderWriter类的stream对象来传递输入输出。
Status GrpcServer::Recognize(ServerContext* context, ServerReaderWriter* stream) { LOG(INFO) <<"Get Recognize request" <(); auto respOnse= std::make_shared(); GrpcConnectionHandler handler(stream, request, response, feature_config_, decode_config_, symbol_table_, model_, fst_); std::thread t(std::move(handler)); t.join(); return Status::OK; } WeNet gRPC客户端定义了GrpcClient类。客户端在建立与服务端的连接时需实例化ASR::Stub,并通过ClientReaderWriter类的stream对象,实现双向流式通信。
void GrpcClient::Connect() { channel_ = grpc::CreateChannel(host_ + ":" + std::to_string(port_), grpc::InsecureChannelCredentials()); stub_ = ASR::NewStub(channel_); context_ = std::make_shared(); stream_ = stub_->Recognize(context_.get()); request_ = std::make_shared(); response_ = std::make_shared(); request_->mutable_decode_config()->set_nbest_config(nbest_); request_->mutable_decode_config()->set_continuous_decoding_config( continuous_decoding_); stream_->Write(*request_); } http://grpc_client_main.cc中,客户端分段传输语音数据,每0.5s进行一次传输,即对于一个采样率为8k的语音文件来说,每次传4000帧数据。为了减小传输数据的大小,提升数据传输速度,先在客户端将float类型转为int16_t,服务端在接受到数据后,再将int16_t转为float。c++中float为32位。
int main(int argc, char *argv[]) { ... // Send data every 0.5 second const float interval = 0.5; const int sample_interval = interval * sample_rate; for (int start = 0; start data; data.reserve(end - start); for (int j = start; j (pcm_data[j])); } // Send PCM data client.SendBinaryData(data.data(), data.size() * sizeof(int16_t)); ... } 本文主要对WeNet云端部署代码进行解析,介绍了WeNet基于WebSocket和基于gRPC的两种服务化接口。
WeNet代码结构清晰,简洁易用,为语音识别提供了从训练到部署的一套端到端解决方案,大大促进了工业落地效率,是非常值得借鉴学习的语音开源项目。
[1] https://grpc.io/docs/what-is-grpc/introduction/
[2]WeNet: Production First and Production Ready End-to-End Speech Recognition Toolkit
[3]WeNet源码
[4]WeNet: Production First and Production Ready End-to-End Speech Recognition Toolkit
[5] U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition
点击关注,第一时间了解华为云新鲜技术~









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 ![[翻译]微服务设计模式5. 服务发现服务端服务发现](https://img7.php1.cn/3cdc5/ca23/525/3af55d7cf19345b9.jpeg)