如何将pytorch中mnist数据集的图像可视化及保存
导出一些库
import torch import torchvision import torch.utils.data as Data import scipy.misc import os import matplotlib.pyplot as plt BATCH_SIZE = 50 DOWNLOAD_MNIST = True
数据集的准备
#训练集测试集的准备
train_data = torchvision.datasets.MNIST(root='./mnist/', train=True,transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST, ) test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
将训练及测试集利用dataloader进行迭代
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1), requires_grad=True).type(torch.FloatTensor)[:20]/255 test_y = test_data.test_labels[:20]#前两千张 #具体查看图像形式为: a_data, a_label = train_data[0] print(type(a_data))#tensor 类型 #print(a_data) print(a_label) #把原始图片保存至MNIST_data/raw/下 save_dir="mnist/raw/" if os.path.exists(save_dir)is False: os.makedirs(save_dir) for i in range(20): image_array,_=train_data[i]#打印第i个 image_array=image_array.resize(28,28) filename=save_dir + 'mnist_train_%d.jpg' % i#保存文件的格式 print(filename) print(train_data.train_labels[i])#打印出标签 scipy.misc.toimage(image_array,cmin=0.0,cmax=1.0).save(filename)#保存图像
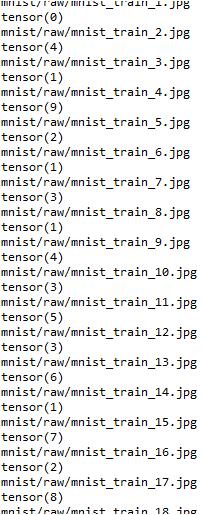

以上这篇pytorch实现mnist数据集的图像可视化及保存就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。


![[TensorFlow系列3]:初学者是选择Tensorflow2.x还是1.x? 2.x与1.x的主要区别?](https://img.php1.cn/3cd4a/189d8/978/7dbdf0f38ad53545.jpeg)


 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有