作者:wuli空空以空空 | 来源:互联网 | 2024-09-25 12:24
列表基础
if __name__ == '__main__':myList = ['hello', True, 98]print( id(myList)) print( type(myList)) print(myList)
创建列表
if __name__ == '__main__':myList = ['hello', True, 98]print( id(myList)) print( type(myList)) print(myList)
列表的特点
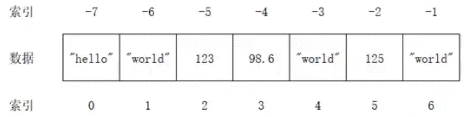
if __name__ == '__main__':a = ['hello', True, 1]print(a[0], a[-3])b = ['hello', True, 1, 1]print( list(b))
查询列表
if __name__ == '__main__':a = ['hello', True, 2, True]print(a.index('hello')) print(a.index(True)) print(a.index(True)) print(a.index('hello', 0, 3)) print(a.index(1, 0, 3)) print(a[3]) print(a[-1]) print(a[-4]) a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]print(a[0: 2: 1])print(a[0: 2]) print(a[0: 2:]) print(a[ : 6: 2]) print(a[0: : 2]) print(a[ : : -1]) print(a[9: : -1]) print(a[6: 0: -2])
列表元素的判断与遍历
if __name__ = '__main__':lst = [10, 20, 'python', 'hello']print(10 in lst)print(100 in lst)print(10 not in lst)print(100, not in lst)for item in lst:print(item)
添加列表元素
if __name__ == '__main__':lst = [10, 20, 30]lst.append(100) print(lst) lst2 = ['hello', 'world']lst.append(lst2) print(lst) lst.extend(lst2) print(lst) lst.insert(1, '我在这') print(lst) lst[1: : ] = ['a', 'b', 'c'] print(lst)
删除列表元素
if __name__ == '__main__':lst = [1, 2, 3, 4, 5, 6, 7, 8, 9]lst.remove(4) print(lst) lst.pop(1) print(lst) lst.pop() print(lst) lst1 = lst[1: 3] print(lst1) print(lst) lst[1: 3] = [] print(lst) lst.clear() print(lst) lst.extend(['这', '是', '添', '加', '的', '内', '容'])print(lst) del lst
修改列表元素
if __name__ == "__main__":lst = [1, 2, 3, 4, 5, 6]lst[2] = 30 print(lst) lst[1: 3] = [300, 400, 500, 600]print(lst)
排序列表元素
if __name__ == '__main__':lst = [20, 40, 10, 98, 54]print('原列表:', lst)lst.sort() print('升序后:',lst) lst.sort(reverse=True)print('降序后:', lst) lst1 = sorted(lst) print(lst1) lst1 = sorted(lst, reverse=True) print(lst1)
列表生成式(生成列表的公式)
if __name__ == '__main__':lst = [i*i for i in range(1, 10)] print(lst)




 京公网安备 11010802041100号
京公网安备 11010802041100号