起因:
公司有一个小项目,大概逻辑如下:
服务器A会不断向队列中push消息,消息主要内容是视频的地址,服务器B则需要不断从队列中pop消息,然后将该视频进行剪辑最终将剪辑后的视频保存到云服务器。个人主要实现B服务器逻辑。
实现思路:
1 线程池+多进程
要求点一:主进程要以daemon的方式运行。
要求点二:利用线程池,设置最大同时运行的worker,每一个线程通过调用subprocess中的Popen来运行wget ffprobe ffmpeg等命令处理视频。
2 消息队列采用redis的list实现
3 主线程从队列中获取到消息后,从线程池中获取空闲从线程(在这里,非主线程统称为从线程,下同),从线程对该消息做一些逻辑上的处理后,然后生成进程对视频进行剪辑,最后上传视频。
要求点三:为了让daemon能在收到signint信号时,处理完当前正在进行的worker后关闭,且不能浪费队列中的数据,需要让主进程在有空闲worker时才从队列中获取数据。
大概就是这样:
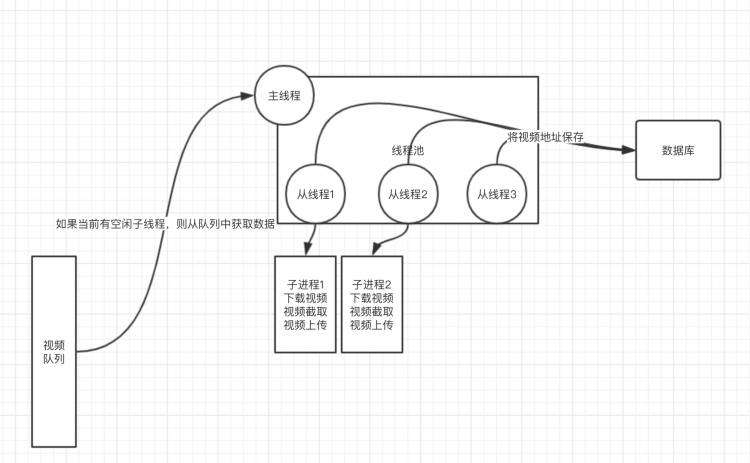
基本上主要资源耗费在视频下载以及视频处理上,且同时运行的worker(从线程)不会太多(一般cpu有几个就设置几个worker)。
上面一共有三个要求点,其中要求点二并不费事。所以忽略。
实现
要求点一实现:


# -*- coding: utf8 -*-
import os
import sys
import time
import signal
import traceback# from shadowsocks
def write_pid_file(pid_file, pid):import fcntlimport stattry:fd = os.open(pid_file, os.O_RDWR | os.O_CREAT,stat.S_IRUSR | stat.S_IWUSR)except OSError:traceback.print_exc()return -1flags = fcntl.fcntl(fd, fcntl.F_GETFD)assert flags != -1flags |= fcntl.FD_CLOEXECr = fcntl.fcntl(fd, fcntl.F_SETFD, flags)assert r != -1# There is no platform independent way to implement fcntl(fd, F_SETLK, &fl)# via fcntl.fcntl. So use lockf insteadtry:fcntl.lockf(fd, fcntl.LOCK_EX | fcntl.LOCK_NB, 0, 0, os.SEEK_SET)except IOError:r = os.read(fd, 32)if r:print('already started at pid %s' % (r))else:print('already started')os.close(fd)return -1os.ftruncate(fd, 0)os.write(fd, (str(pid)))return 0def freopen(f, mode, stream):oldf = open(f, mode)oldfd = oldf.fileno()newfd = stream.fileno()os.close(newfd)os.dup2(oldfd, newfd)def daemon_start(settings, main_process_handler):def handle_exit(signum, _):if signum == signal.SIGTERM:sys.exit(0)sys.exit(1)signal.signal(signal.SIGINT, handle_exit)signal.signal(signal.SIGTERM, handle_exit)pid = os.fork()assert pid != -1# Parentif pid:time.sleep(3)sys.exit(0)print("child has forked")# child signals its parent to exitppid = os.getppid()pid = os.getpid()if write_pid_file(settings.PID_FILE, pid) != 0:os.kill(ppid, signal.SIGINT)sys.exit(1)# set self to process-group-leader
os.setsid()signal.signal(signal.SIGHUP, signal.SIG_IGN)print('started')os.kill(ppid, signal.SIGTERM)# octal 022os.umask(18)sys.stdin.close()try:freopen(settings.DEBUG_LOG_PATH, 'a', sys.stdout)freopen(settings.DEBUG_LOG_PATH, 'a', sys.stderr)except IOError:print(traceback.print_exc())sys.exit(1)main_process_handler()def daemon_stop(pid_file):import errnotry:with open(pid_file) as f:pid = buf = f.read()if not buf:print('not running')except IOError as e:print(traceback.print_exc())if e.errno == errno.ENOENT:print("not running")# always exit 0 if we are sure daemon is not runningreturnsys.exit(1)pid = int(pid)if pid > 0:try:os.kill(pid, signal.SIGTERM)except OSError as e:if e.errno == errno.ESRCH:print('not running')# always exit 0 if we are sure daemon is not runningreturnprint(traceback.print_exc())sys.exit(1)else:print('pid is not positive: %d', pid)# sleep for maximum 300sfor i in range(0, 100):try:# query for the pid
os.kill(pid, 0)except OSError as e:# not found the processif e.errno == errno.ESRCH:breaktime.sleep(3)print("waiting for all threads finished....")else:print('timed out when stopping pid %d', pid)sys.exit(1)print('stopped')os.unlink(pid_file)def main():args = sys.argv[1:]assert len(args) == 2if args[0] not in ["stop", "start"]:print("only supported: [stop | start]")returnif args[1] not in ["dev", "local", "prod"]:print("only supported: [dev | local | prod]")from globals import set_settings, initialize_redisset_settings(args[1])initialize_redis()from globals import settingsimport entryif args[0] == "stop":print("stopping...")daemon_stop(settings.PID_FILE)elif args[0] == "start":print("starting...")daemon_start(settings, entry.run)main()
要求点三实现:
线程池,采用python的futures模块。该模块提供了线程池的机制。稍微说一下他的线程池实现原理吧,ThreadPoolExecutor该类实现了线程池:
1 每个实例本身有个_work_queue属性,这是一个Queue对象,里面存储了任务。
2 每当我们调用该对象的submit方法时,都会向其_work_queue中放入一个任务,同时生成从线程,直到从线程数达到max_worker所设定的值。
3 该线程池实例中所有的从线程会不断的从_work_queue中获取任务,并执行。同时从线程的daemon属性被设置为True
# -*- coding: utf8 -*-
import json
import traceback
import signal
import sys
import time
from threading import Lock
from concurrent.futures import ThreadPoolExecutor
from .globals import settings, video_info_queuedef handler(data):# 业务逻辑
running_futures_count &#61; 0def run():global running_futures_countcount_lock &#61; Lock()pool &#61; ThreadPoolExecutor(max_workers&#61;settings.MAX_WORKER)try:def reduce_count(_):global running_futures_countwith count_lock:running_futures_count -&#61; 1def handle_exit(_, __):print("get SIGINT signal")pool.shutdown(False)while True:if running_futures_count &#61;&#61; 0:sys.exit(0)time.sleep(1)print("now running futures count is %s, please wait" % running_futures_count)def handle_data(data):global running_futures_countwith count_lock:running_futures_count &#43;&#61; 1future &#61; pool.submit(handler, data)future.add_done_callback(reduce_count)signal.signal(signal.SIGINT, handle_exit)signal.signal(signal.SIGTERM, handle_exit)while not pool._shutdown:print(len(pool._work_queue.queue), pool._shutdown)while not pool._shutdown and (len(pool._work_queue.queue) < pool._max_workers):data &#61; video_info_queue.bpop(20)if data:handle_data(data)else:data &#61; abnormal_video_info_queue.bpop(1)print("video_info_queue is empty, get data: %s from abnormal_video_info_queue" % data)if data:print("abnormal_video_info_queue")handle_data(data)time.sleep(5)print("now all the workers is busy, so wait and do not submit")finally:pool.shutdown(False)
重点就是那嵌套的while循环。
踩坑&收获&#xff1a;
1 python中只有主线程才能处理信号&#xff0c;如果使用线程中的join方法阻塞主线程&#xff0c;如果从线程运行时间过长可能会导致信号长时间无法处理。所以尽量设置从线程的daemon为True。
2 Queue的底层是deque&#xff0c;而deque的底层是一个双端链表&#xff0c;为什么用双端链表而不用list&#xff1f;答案请在参考中找。
3 学会了进程以daemon方式运行的实现方式&#xff1a;
1 pid文件的来源
2 进程以及进程组的概念
3 信号的捕捉
4 dup2函数以及fcntl函数
4 进程使用Popen()创建时&#xff0c;如果用PIPE作为子进程(stdin stdout stderr)与父进程进行交互时&#xff0c;然后调用wait时&#xff0c;如果子进程的stdin stdout stderr中某个数据过多可能会导致主进程卡死。原因也在参考中找。
5 sudo执行脚本时环境变量去哪了&#xff1f;答案请在参考中找
6 python中的weakref模块很有用啊
参考&#xff1a;
1 http://blog.sina.com.cn/s/blog_4da051a60102uyvg.html
2 https://toutiao.io/posts/zr31ak/preview
3 https://www.cnblogs.com/chybot/p/5176118.html
4 https://stackoverflow.com/questions/5045771/python-how-to-prevent-subprocesses-from-receiving-ctrl-c-control-c-sigint
5 http://siwind.iteye.com/blog/1753517
6 https://www.jianshu.com/p/646d1d09fc53
7 https://stackoverflow.com/questions/46598710/how-to-use-pipes-and-redirects-using-os-execv-if-possible
8 http://xiaorui.cc/2017/02/22/%E4%B8%8D%E8%A6%81%E7%B2%97%E6%9A%B4%E7%9A%84%E9%94%80%E6%AF%81python%E7%BA%BF%E7%A8%8B/
9 shadowsocks源码







 京公网安备 11010802041100号
京公网安备 11010802041100号