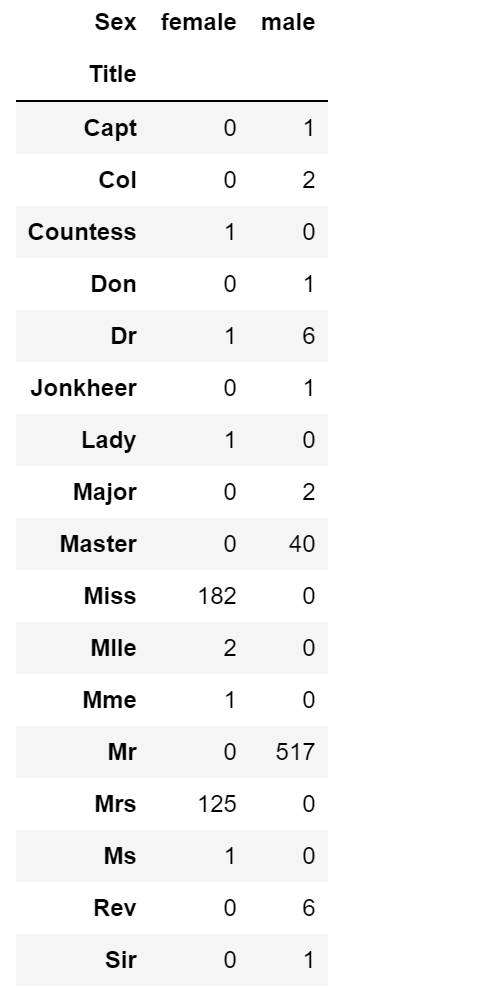
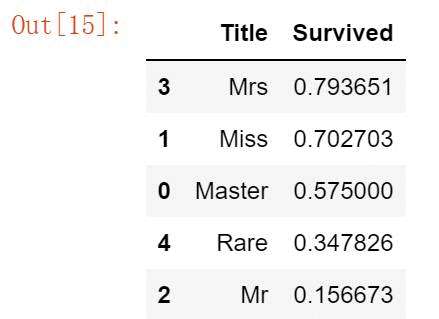
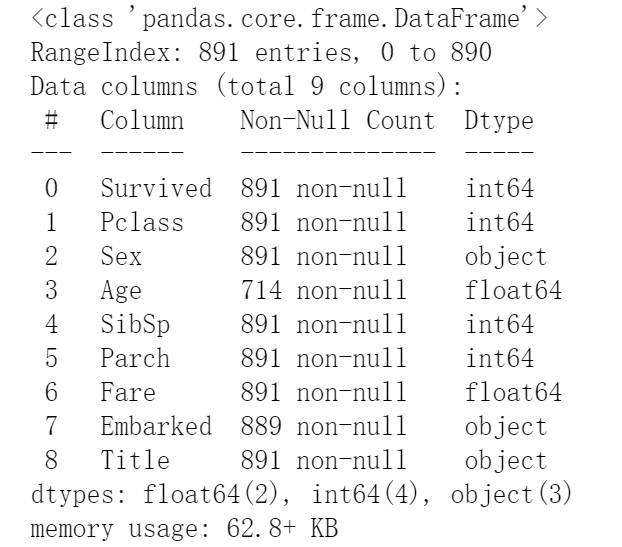
#分类title 归为几个大类 for database in combine:database['Title']=database['Title'].replace(['Lady','Countess','Capt','Col','Don','Dr','Major','Rev','Sir','Jonkheer','Dona'],'Rare')#将出现次数少的归类为Rare一类database['Title']=database['Title'].replace('Mlle','Miss')#将表达为同一意思的称呼归为一类database['Title']=database['Title'].replace('Ms','Miss')database['Title']=database['Title'].replace('Mme','Mrs') #replace函数 两个参数(被替换内容,替换后内容) train_df[['Title','Survived']].groupby(['Title'],as_index=False).mean().sort_values(by='Survived',ascending=False)
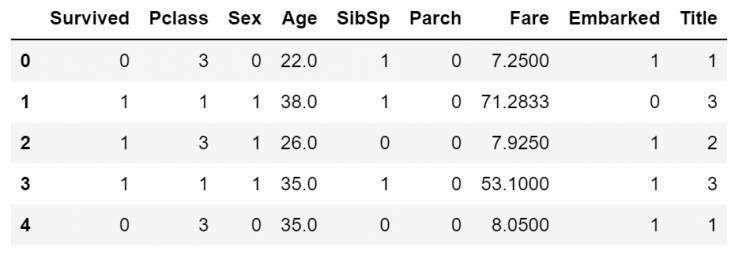
#处理sex 将数据转化为1和0 for database in combine:database['Sex']= database['Sex'].map({'female':1,'male':0}).astype(int)
#处理Title title_mapping ={'Mr':1,'Miss':2,'Mrs':3,'Master':4,'Rare':5} for database in combine:database['Title']= database['Title'].map(title_mapping).astype(int)
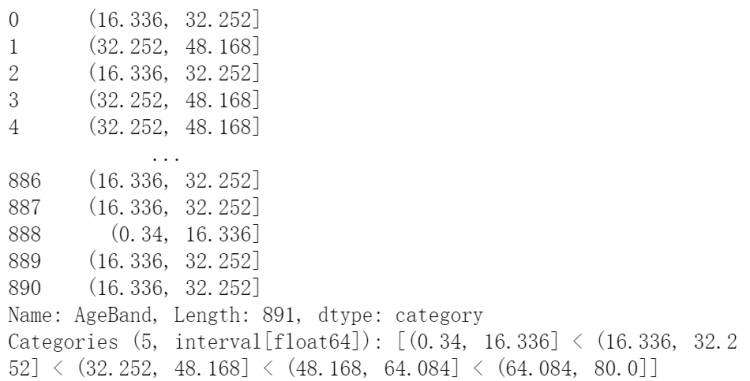
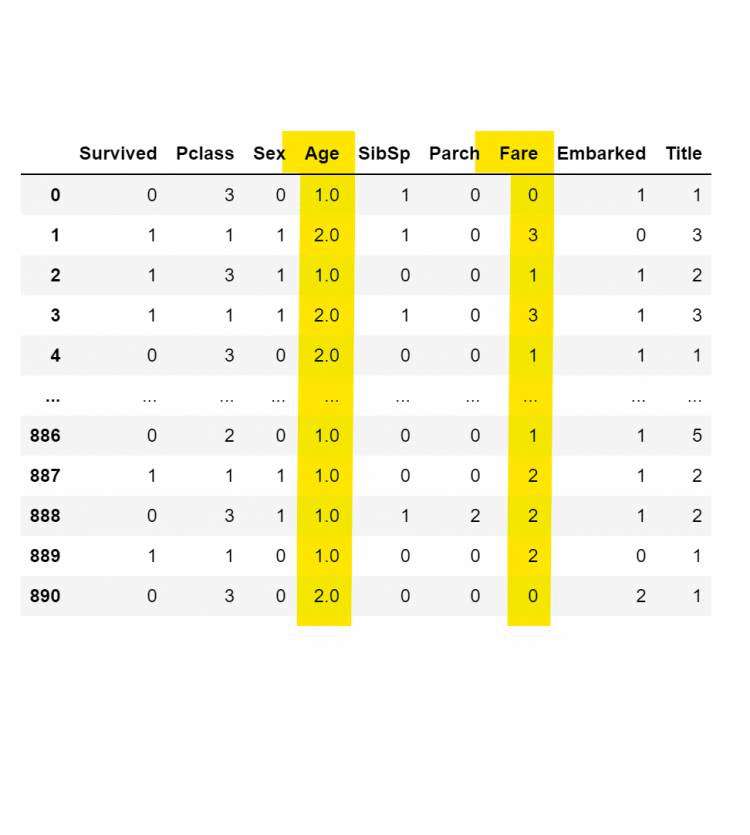
for database in combine:database.loc[ database[&#39;Age&#39;]<16,&#39;Age&#39;]&#61;0database.loc[(database[&#39;Age&#39;]>&#61;16)&(database[&#39;Age&#39;]<32),&#39;Age&#39;]&#61;1database.loc[(database[&#39;Age&#39;]>&#61;32)&(database[&#39;Age&#39;]<48),&#39;Age&#39;]&#61;2database.loc[(database[&#39;Age&#39;]>&#61;48)&(database[&#39;Age&#39;]<64),&#39;Age&#39;]&#61;3database.loc[ database[&#39;Age&#39;]>&#61;64,&#39;Age&#39;]&#61;4train_df.drop([&#39;AgeBand&#39;],axis&#61;1,inplace&#61;True) combine&#61;[train_df,test_df] train_df
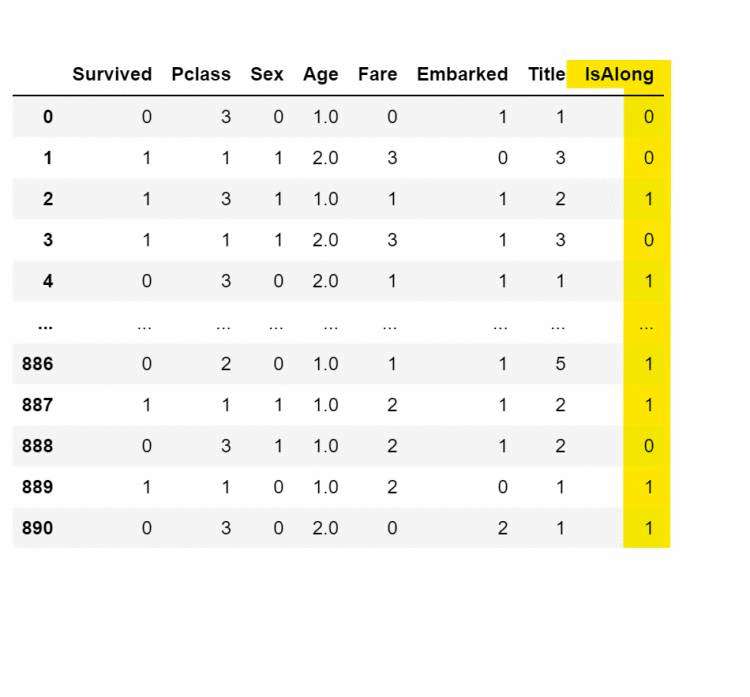
for database in combine:database[&#39;Family&#39;]&#61;database[&#39;SibSp&#39;]&#43; database[&#39;Parch&#39;]&#43;1# train_df.head()for database in combine:database[&#39;IsAlong&#39;]&#61;1database.loc[database[&#39;Family&#39;]>1,&#39;IsAlong&#39;]&#61;0train_df.drop([&#39;SibSp&#39;,&#39;Parch&#39;,&#39;Family&#39;],inplace&#61;True,axis&#61;1) test_df.drop([&#39;SibSp&#39;,&#39;Parch&#39;,&#39;Family&#39;],inplace&#61;True,axis&#61;1)train_df









 京公网安备 11010802041100号
京公网安备 11010802041100号