前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 刘亦菲的老公
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
数据获取
爬取了携程网上关于全国大概16000条景点数据和美团网上五个城市的大概5000条酒店数据,然后导出为.csv表格形式方便用
pandas.read_csv()
来读取其中的数据。
数据预处理和清洗
景点数据
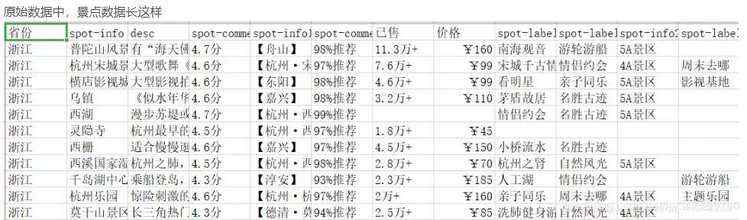
原始数据中,景点数据长这样
由于数据按省份分为三十多个.csv文件,并且其中还有不需要的列,用以下代码来读取(其他省份同样,只列出上海的)
import pandas as pd上海 = pd.read_csv('上海.csv', engine='python', usecols=['省份', 'spot-info', 'spot-info1', 'spot-info2', '价格', '已售', 'desc', 'spot-comment', 'spot-label1'])
再将全部数据组合在一起
China_scenic = pd.concat([上海, 云南, 内蒙古, 北京, 台湾, 吉林, 四川, 天津, 宁夏, 安徽, 山东, 山西, 广东, 广西, 新疆, 江苏, 河北, 河南, 浙江, 海南, 湖北, 湖南, 澳门, 甘肃, 福建, 西藏, 贵州, 辽宁, 重庆, 陕西, 青海, 香港, 黑龙江], sort=True, ignore_index=True).reset_index().drop(columns='index')
接下来删除那些重复和没有评分的地点。
# 删除重复地点China_scenic = China_scenic.drop_duplicates(subset='spot-info')# 删除没有评分的地点China_scenic = China_scenic[China_scenic['spot-comment'].notnull()]
再将评分转换为好评率,将没有景区等级的景点标为无等级
def grade_change(i): i = i.replace('分', '') return float(i) / 5# 将评分转换为好评率China_scenic['spot-comment'] = China_scenic['spot-comment'].apply(grade_change)# 将没有景区等级的景区标为无等级China_scenic['spot-info2'] = China_scenic['spot-info2'].fillna('无等级')
由于有许多景点是不需要购票进入的,这里再将所有景点分成两部分以便之后的操作
# 选取免费景点China_scenic_free = China_scenic[China_scenic['价格'].isna()].reset_index().drop(columns='index')# 选取收费景点China_scenic_charge = China_scenic[China_scenic['价格'].notnull()].reset_index().drop(columns='index')
接下来把消费景点的销售量转换为具体数值,把免费景点的销售量和价格这两列删除
def sold_change(i): if '万+' in i: i = i.replace('.', '') i = i.replace('万+', '000') return int(i) else: return int(i)# 将已售数据转换为整形China_scenic_charge['已售'] = China_scenic_charge['已售'].apply(sold_change)# 删除两列China_scenic_free = China_scenic_free.drop(columns='已售').drop(columns='价格')
酒店数据
酒店数据,这里仅仅爬取了我选取的五个城市的酒店数据(为了机器学习的例子仅选了五个城市)
接下来读取数据,并且把价格转换为具体数值,把销量转换为具体数值(对每个城市的操作都相同,只展示一个城市的操作)
def price_change(i): i = i.replace('起', '') return int(i)def sold_change(i): if '+消费' in i: i = i.replace('+消费', '') return int(i) else: i = i.replace('消费', '') return int(i)Zhangjiajie_Hotel = pd.read_csv('张家界酒店.csv', engine='python', usecols=['标题', 'poi-address', 'poi-type', 'poi-price', 'poi-buy-num', 'service-icons1','service-icons3', 'service-icons5']).dropna()Zhangjiajie_Hotel['地址'] = '张家界'Zhangjiajie_Hotel['poi-price'] = Changsha_Hotel['poi-price'].apply(price_change)Zhangjiajie_Hotel['poi-buy-num'] = Changsha_Hotel['poi-buy-num'].apply(sold_change)
数据分析
景点数据
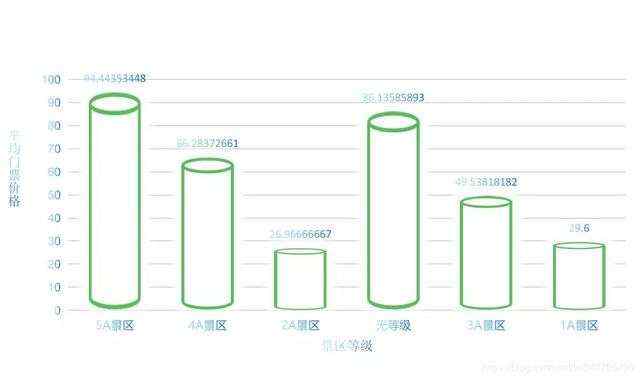
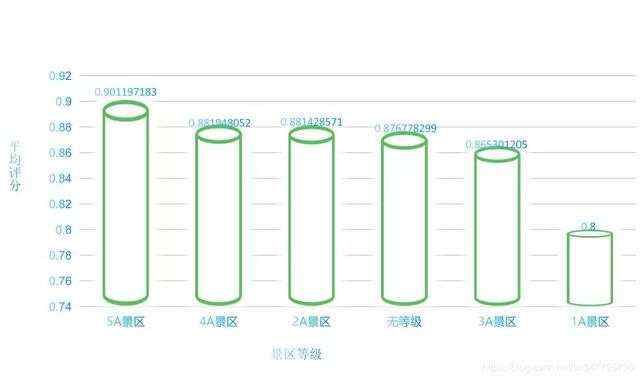
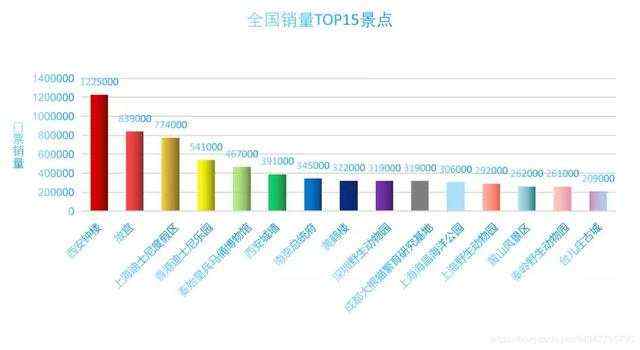
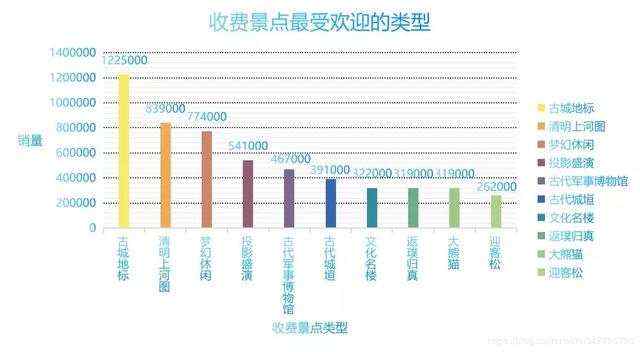
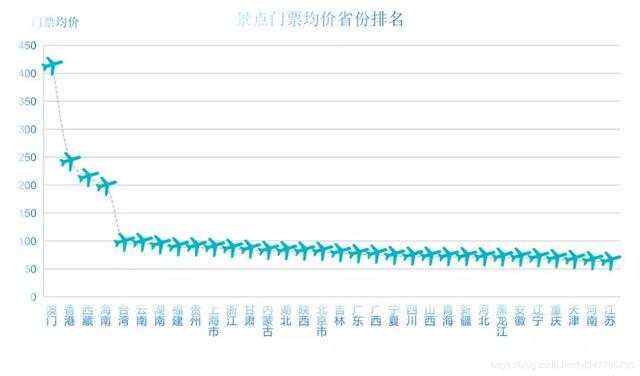
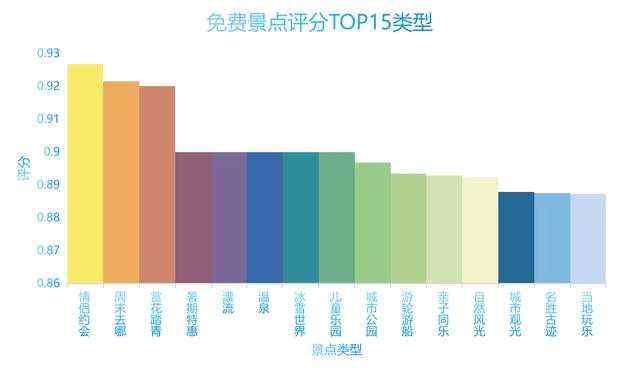
# 景区等级评价scenic_level_comment = China_scenic.groupby('spot-info2').mean().sort_values('spot-comment', ascending=False)# # 收费景点# 销量前五十的景点China_scenic_50 = China_scenic_charge.sort_values('已售', ascending=False).head(50).reset_index().drop(columns='index')# 平均门票最贵的省份China_scenic_exp = China_scenic_charge.groupby('省份').mean().sort_values('价格', ascending=False)['价格']# 最受欢迎的省份Hot_province = China_scenic_charge.groupby('省份').sum().sort_values('已售', ascending=False)['已售']# 最受欢迎的付费景点类型Hot_kind_charge = China_scenic_charge.groupby('spot-label1').mean().sort_values('已售', ascending=False).head(10)['已售']# # 免费景点China_scenic_free = China_scenic_free.drop(columns='已售').drop(columns='价格')# 评分最高的五十个免费景点free_scenic_50 = China_scenic_free.sort_values('spot-comment', ascending=False).head(50)# 评分最高的的免费景点类型Hot_kind_free = China_scenic_free.groupby(['spot-label1']).mean().sort_values('spot-comment', ascending=False).head(15)
再将这些分析出的数据用.to_csv()导出,用PPT画图(自己的数据可视化做得很丑。。。。) 。。。)
酒店数据
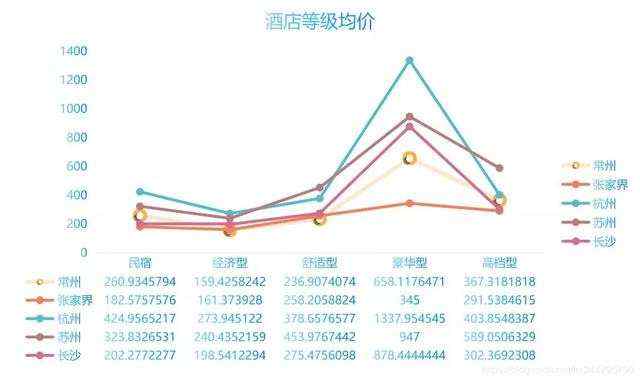
将五个城市酒店数据组合,再进行分析如下
All_Hotel = pd.concat([Changsha_Hotel, Zhangjiajie_Hotel, Hangzhou_Hotel, Suzhou_Hotel, Changzhou_Hotel], axis=0, sort=False).dropna().reset_index().drop(columns='index')kind_price = All_Hotel.groupby(['地址', 'poi-type']).mean()['poi-price']
把‘kind_price’导出画图
机器学习
假设去某个景点旅游,需要考虑出行方式、酒店住宿、门票价格等因素,由此可以大概计算出一个数值来表示该趟旅游“值不值 ”(爬取到的数据中,关于免费景点只有评分一条可以评定其价值,不太具有真实意义,所以不取免费景点)
从景点数据随机选取一个,酒店数据随机选取一个,出行方式随机选取一种。(由此来组合成一行,模拟成一个人选择某种方式去了某地游玩了某个景点又选择了某个酒店)
由于数据的不完整,所以这里主要从“钱花得最少,去的景点评分最高”这样的角度来判断“值不值”。
“值不值”的恒定标准为:
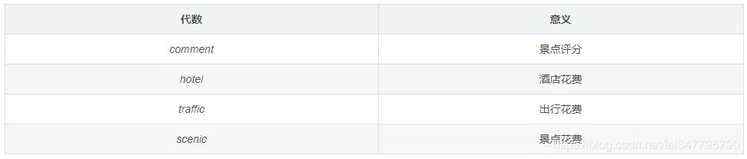
代数 意义
PS:这里本应该每个值附上自己的权重,由于时间关系,我仅将他们(0,1)规格化了,这样就是1:1:1:1的关系,以后有时间在调整其权重问题。
再由Score值来分类:
代码实现
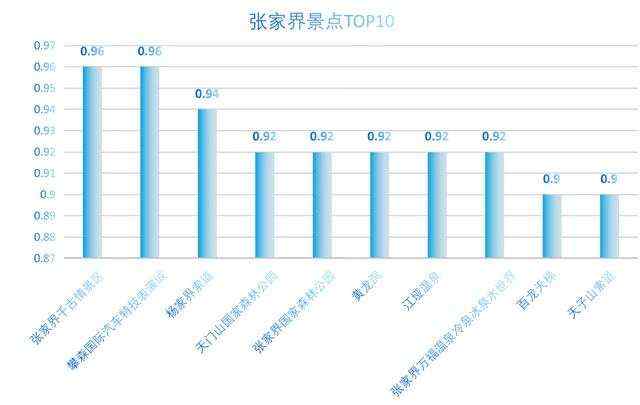
先从全国景点数据中,找到五个例子城市的景点数据。 (方法五个都一样,这里只展示以张家界为例)
def find_zhangjiajie(i): if '张家界' in i: return True else: return Falsezhangjiajie_scenic = China_scenic_charge[China_scenic_charge['spot-info1'].apply(find_zhangjiajie)].reset_index().drop(columns='index')
导出后画图如下
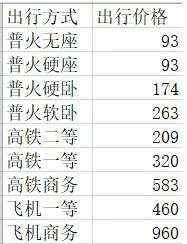
接下来是获取出行数据,由于机票价格波动太大,并且某些城市还没有普火,这里主要是取平均值,zhangjiajie_traffic数据大概这个样子
现在,对于张家界的景点、出行、酒店数据已经准备完毕 左右拼接在一起,创建随机数据集 zhangjiajie_travel:
def price_02(i): i = (i - zhangjiajie_travel['价格'].min()) / (zhangjiajie_travel['价格'].max() - zhangjiajie_travel['价格'].min()) return idef comment_02(i): i = (i - zhangjiajie_travel['spot-comment'].min()) / ( zhangjiajie_travel['spot-comment'].max() - zhangjiajie_travel['spot-comment'].min()) return idef hotel_02(i): i = (i - zhangjiajie_travel['poi-price'].min()) / ( zhangjiajie_travel['poi-price'].max() - zhangjiajie_travel['poi-price'].min()) return idef traffic_02(i): i = (i - zhangjiajie_travel['出行价格'].min()) / (zhangjiajie_travel['出行价格'].max() - zhangjiajie_travel['出行价格'].min()) return i# 每个表随机采样一万行zhangjiajie_scenic_test = zhangjiajie_scenic.sample(n=10000, axis=0, random_state=1, replace=True).reset_index().drop( columns='index')zhangjiajie_hotel_test = zhangjiajie_hotel.sample(n=10000, axis=0, random_state=1, replace=True).reset_index().drop( columns='index')zhangjiajie_traffic_test = zhangjiajie_traffic.sample(n=10000, axis=0, random_state=1, replace=True).reset_index().drop( columns='index')# 合在一起成为张家界的“假旅游数据集”zhangjiajie_travel = pd.concat([zhangjiajie_scenic_test, zhangjiajie_hotel_test, zhangjiajie_traffic_test], sort=False, axis=1).drop(columns='Unnamed: 0')
重点:把五个城市的测试数据集建立完毕后,上下拼接在一起成为总的数据集(五万条),再将Score值算出,并对其打上标签
import pandas as pdimport numpy as npdef Score_change(i): if i <&#61; np.percentile(lfw_Happy_travel[&#39;Score&#39;], (25)): return 0 elif i >&#61; np.percentile(lfw_Happy_travel[&#39;Score&#39;], (25)) and i <&#61; np.percentile(lfw_Happy_travel[&#39;Score&#39;], (50)): return 1 elif i >&#61; np.percentile(lfw_Happy_travel[&#39;Score&#39;], (50)) and i <&#61; np.percentile(lfw_Happy_travel[&#39;Score&#39;], (75)): return 2 elif i >&#61; np.percentile(lfw_Happy_travel[&#39;Score&#39;], (75)): return 3lfw_Happy_travel &#61; pd.concat([changsha_travel, zhangjiajie_travel, suzhou_travel, hangzhou_travel, changzhou_travel], axis&#61;0, sort&#61;False).dropna()lfw_Happy_travel[&#39;Score&#39;] &#61; lfw_Happy_travel[&#39;spot-comment&#39;] / (lfw_Happy_travel[&#39;价格&#39;] * lfw_Happy_travel[&#39;poi-price&#39;] * lfw_Happy_travel[&#39;出行价格&#39;])lfw_Happy_travel[&#39;Score&#39;] &#61; lfw_Happy_travel[&#39;Score&#39;].apply(Score_change)
最后&#xff0c;利用SVM支持向量机来对整个数据集进行评分&#xff0c;以总花费和景点评分作为属性&#xff0c;Score值作为标签
from sklearn import model_selectionfrom sklearn import svmlfw_Happy_travel_num &#61; pd.DataFrame( {&#39;景点评分&#39;: lfw_Happy_travel[&#39;spot-comment&#39;], &#39;花费&#39;: lfw_Happy_travel[&#39;cost&#39;], &#39;Score&#39;: lfw_Happy_travel[&#39;Score&#39;] })x &#61; lfw_Happy_travel_num.iloc[:, 0:2].values.tolist()y &#61; lfw_Happy_travel_num.iloc[:, -1].tolist()x_train, x_test, y_train, y_test &#61; model_selection.train_test_split(x, y, random_state&#61;1, test_size&#61;0.3)clf &#61; svm.SVC(C&#61;0.1, kernel&#61;&#39;linear&#39;, decision_function_shape&#61;&#39;ovr&#39;)# clf &#61; svm.SVC(kernel&#61;&#39;rbf&#39;, gamma&#61;0.1, decision_function_shape&#61;&#39;ovo&#39;, C&#61;0.8)clf.fit(x_train, y_train)print("SVM-输出训练集的准确率为&#xff1a;



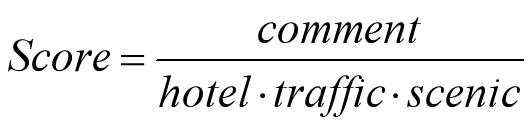









 京公网安备 11010802041100号
京公网安备 11010802041100号