使用Excel自建了一个数据集,作为演示数据,如下:
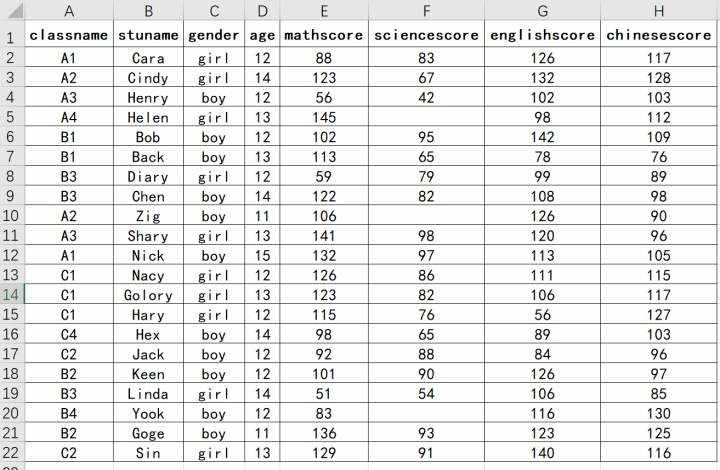
可见,数据中存在部分缺失值。
第一步:读入excel文件。
这里需要使用pandas库中的read_excel()函数。初次使用这个函数,可以看一看帮助文档~
一个很小的技巧,使用help()查看帮助文档时,第一,一定要明确函数所在的库名。第二,函数后面不能加(),否则会报错。错误原因是函数没有参数。因为,当函数本身是要输入参数的,一旦我们添加了括号,就必须输入参数。

正确的查看read_excel()函数的帮助文档方法如下:
import pandas as pd
help(pd.read_excel)
...
Help on function read_excel in module pandas.io.excel._base:
read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, mangle_dupe_cols=True, **kwds)Read an Excel file into a pandas DataFrame.Supports `xls`, `xlsx`, `xlsm`, `xlsb`, and `odf` file extensionsread from a local filesystem or URL. Supports an option to reada single sheet or a list of sheets.Parameters----------io : str, bytes, ExcelFile, xlrd.Book, path object, or file-like objectAny valid string path is acceptable. The string could be a URL. ValidURL schemes include http, ftp, s3, and file. For file URLs, a host isexpected. A local file could be: ``file://localhost/path/to/table.xlsx``.If you want to pass in a path object, pandas accepts any ``os.PathLike``.By file-like object, we refer to objects with a ``read()`` method,such as a file handler (e.g. via builtin ``open`` function)or ``StringIO``.sheet_name : str, int, list, or None, default 0Strings are used for sheet names. Integers are used in zero-indexedsheet positions. Lists of strings/integers are used to requestmultiple sheets. Specify None to get all sheets.Available cases:* Defaults to ``0``: 1st sheet as a `DataFrame`* ``1``: 2nd sheet as a `DataFrame`* ``"Sheet1"``: Load sheet with name "Sheet1"* ``[0, 1, "Sheet5"]``: Load first, second and sheet named "Sheet5"as a dict of `DataFrame`* None: All sheets.header : int, list of int, default 0Row (0-indexed) to use for the column labels of the parsedDataFrame. If a list of integers is passed those row positions willbe combined into a ``MultiIndex``. Use None if there is no header.names : array-like, default NoneList of column names to use. If file contains no header row,then you should explicitly pass header=None.index_col : int, list of int, default NoneColumn (0-indexed) to use as the row labels of the DataFrame.Pass None if there is no such column. If a list is passed,those columns will be combined into a ``MultiIndex``. If asubset of data is selected with ``usecols``, index_colis based on the subset.usecols : int, str, list-like, or callable default None* If None, then parse all columns.* If str, then indicates comma separated list of Excel column lettersand column ranges (e.g. "A:E" or "A,C,E:F"). Ranges are inclusive ofboth sides.* If list of int, then indicates list of column numbers to be parsed.* If list of string, then indicates list of column names to be parsed... versionadded:: 0.24.0* If callable, then evaluate each column name against it and parse thecolumn if the callable returns ``True``.Returns a subset of the columns according to behavior above... versionadded:: 0.24.0squeeze : bool, default FalseIf the parsed data only contains one column then return a Series.dtype : Type name or dict of column -> type, default NoneData type for data or columns. E.g. {'a': np.float64, 'b': np.int32}Use `object` to preserve data as stored in Excel and not interpret dtype.If converters are specified, they will be applied INSTEADof dtype conversion.engine : str, default NoneIf io is not a buffer or path, this must be set to identify io.Acceptable values are None, "xlrd", "openpyxl" or "odf".converters : dict, default NoneDict of functions for converting values in certain columns. Keys caneither be integers or column labels, values are functions that take oneinput argument, the Excel cell content, and return the transformedcontent.true_values : list, default NoneValues to consider as True.false_values : list, default NoneValues to consider as False.skiprows : list-likeRows to skip at the beginning (0-indexed).nrows : int, default NoneNumber of rows to parse... versionadded:: 0.23.0na_values : scalar, str, list-like, or dict, default NoneAdditional strings to recognize as NA/NaN. If dict passed, specificper-column NA values. By default the following values are interpretedas NaN: '', '#N/A', '#N/A N/A', '#NA', '-1.#IND', '-1.#QNAN', '-NaN', '-nan','1.#IND', '1.#QNAN', '
Returns-------DataFrame or dict of DataFramesDataFrame from the passed in Excel file. See notes in sheet_nameargument for more information on when a dict of DataFrames is returned.See Also--------to_excel : Write DataFrame to an Excel file.to_csv : Write DataFrame to a comma-separated values (csv) file.read_csv : Read a comma-separated values (csv) file into DataFrame.read_fwf : Read a table of fixed-width formatted lines into DataFrame.Examples--------The file can be read using the file name as string or an open file object:>>> pd.read_excel('tmp.xlsx', index_col=0) # doctest: +SKIPName Value0 string1 11 string2 22 #Comment 3>>> pd.read_excel(open('tmp.xlsx', 'rb'),... sheet_name='Sheet3') # doctest: +SKIPUnnamed: 0 Name Value0 0 string1 11 1 string2 22 2 #Comment 3Index and header can be specified via the `index_col` and `header` arguments>>> pd.read_excel('tmp.xlsx', index_col=None, header=None) # doctest: +SKIP0 1 20 NaN Name Value1 0.0 string1 12 1.0 string2 23 2.0 #Comment 3Column types are inferred but can be explicitly specified>>> pd.read_excel('tmp.xlsx', index_col=0,... dtype={'Name': str, 'Value': float}) # doctest: +SKIPName Value0 string1 1.01 string2 2.02 #Comment 3.0True, False, and NA values, and thousands separators have defaults,but can be explicitly specified, too. Supply the values you would likeas strings or lists of strings!>>> pd.read_excel('tmp.xlsx', index_col=0,... na_values=['string1', 'string2']) # doctest: +SKIPName Value0 NaN 11 NaN 22 #Comment 3Comment lines in the excel input file can be skipped using the `comment` kwarg>>> pd.read_excel('tmp.xlsx', index_col=0, comment='#') # doctest: +SKIPName Value0 string1 1.01 string2 2.02 None NaN
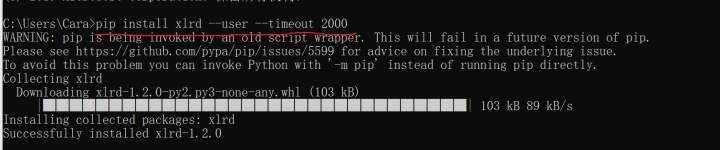
第一次尝试导入文件报错,说是缺少需要的包,叫'xlrd',可以使用pip安装。
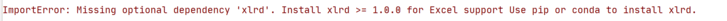
安包命令:
再次尝试导入文件:
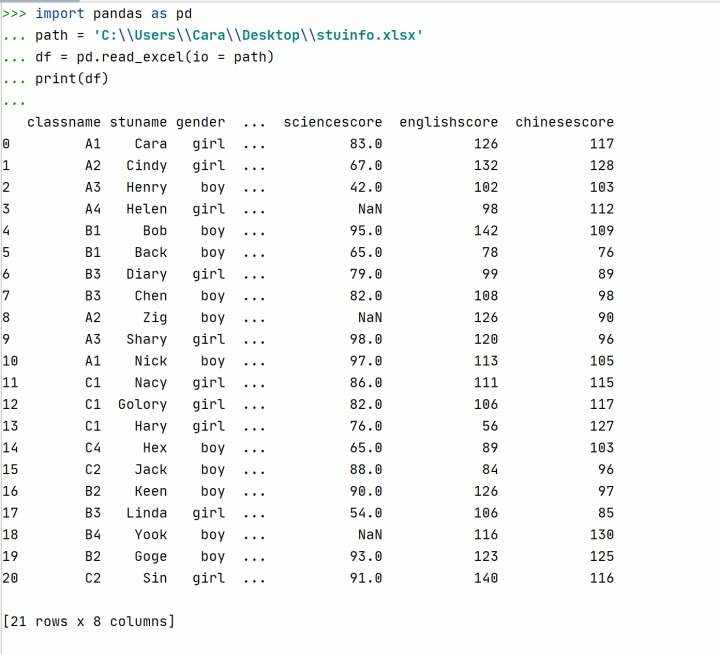
可见,缺失值部分对应内容为NaN,表示Not a Number。
缺失值处理方法一:删除缺失值所在行
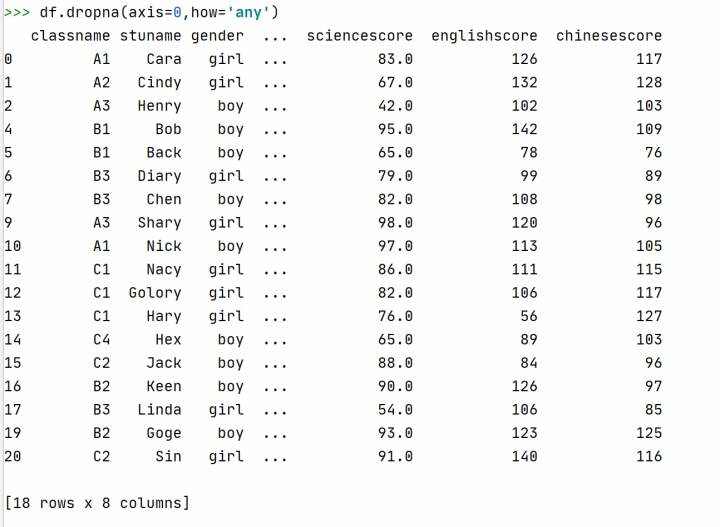
注释:①dataframe数据格式有dropna()这个方法,可以直接修改并覆盖原始数据框。
②dropna()中参数都有默认值,如axis = 0,表示按行进行处理,how = 'any'表示,只要一行中有一个缺失值,就删除整行。how = 'all'表示,必须整行都确实,才删除该行。
缺失值处理方法二:填充
填充的方法有很多,常见的有:均值填充、最值填充、取前一个记录对应值进行填充、取后一个记录对应值填充、拉格朗日填充法等等。
演示一,使用均值填充:
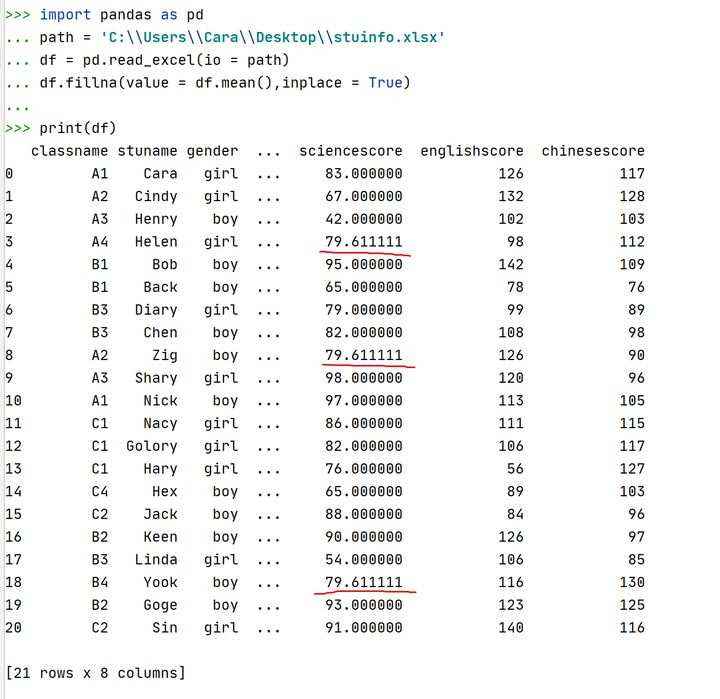
注释:①这里的均值是指缺失值所在列的均值。
②fillna()函数中inplace = True表示使用新的值覆盖原来的值。默认是False。
演示二,使用下一条记录的对应值填充本行的缺失值。
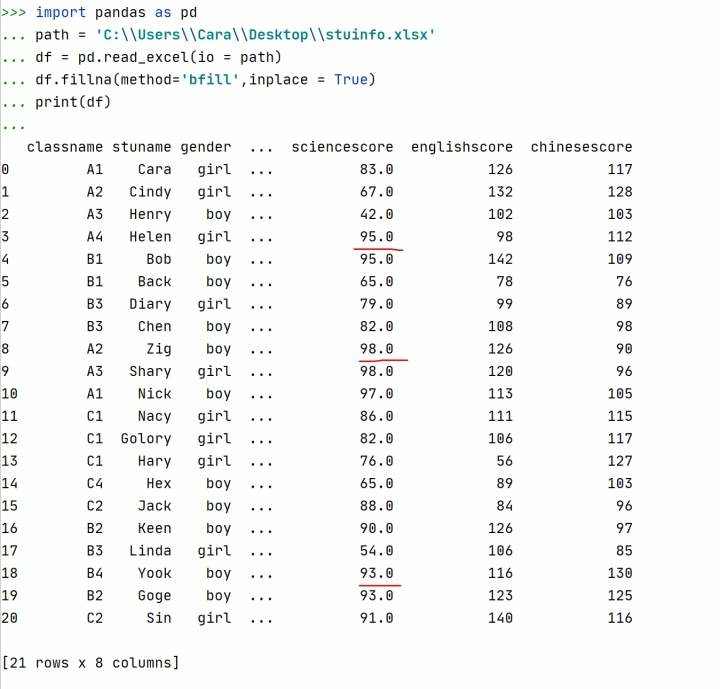
注释:method = 'bfill'表示使用下一行的对应值填充本行的缺失值。b表示below。使用该方法填充时,有一种特殊情况需要注意,就是缺失值出现在最后一行,则无法使用下一行对应值进行填充。
同理,method = 'ffill',表示使用前一行的对应值填充本行的缺失值。f表示foreword。要特别注意缺失值出现在第一行的情况,该方法会失效。
其他关于fillna()方法的信息,查看帮助文档:
注意:查看某个类对象的方法,要先将类实例化,比如这里的数据框实例化为df。
import pandas as pd
... path = 'C:UsersCaraDesktopstuinfo.xlsx'
... df = pd.read_excel(io = path)
... help(df.fillna)
...
Help on method fillna in module pandas.core.frame:
fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None) -> Union[ForwardRef('DataFrame'), NoneType] method of pandas.core.frame.DataFrame instanceFill NA/NaN values using the specified method.Parameters----------value : scalar, dict, Series, or DataFrameValue to use to fill holes (e.g. 0), alternately adict/Series/DataFrame of values specifying which value to use foreach index (for a Series) or column (for a DataFrame). Values notin the dict/Series/DataFrame will not be filled. This value cannotbe a list.method : {'backfill', 'bfill', 'pad', 'ffill', None}, default NoneMethod to use for filling holes in reindexed Seriespad / ffill: propagate last valid observation forward to next validbackfill / bfill: use next valid observation to fill gap.axis : {0 or 'index', 1 or 'columns'}Axis along which to fill missing values.inplace : bool, default FalseIf True, fill in-place. Note: this will modify anyother views on this object (e.g., a no-copy slice for a column in aDataFrame).limit : int, default NoneIf method is specified, this is the maximum number of consecutiveNaN values to forward/backward fill. In other words, if there isa gap with more than this number of consecutive NaNs, it will onlybe partially filled. If method is not specified, this is themaximum number of entries along the entire axis where NaNs will befilled. Must be greater than 0 if not None.downcast : dict, default is NoneA dict of item->dtype of what to downcast if possible,or the string 'infer' which will try to downcast to an appropriateequal type (e.g. float64 to int64 if possible).Returns-------DataFrame or NoneObject with missing values filled or None if ``inplace=True``.See Also--------interpolate : Fill NaN values using interpolation.reindex : Conform object to new index.asfreq : Convert TimeSeries to specified frequency.Examples-------->>> df = pd.DataFrame([[np.nan, 2, np.nan, 0],... [3, 4, np.nan, 1],... [np.nan, np.nan, np.nan, 5],... [np.nan, 3, np.nan, 4]],... columns=list('ABCD'))>>> dfA B C D0 NaN 2.0 NaN 01 3.0 4.0 NaN 12 NaN NaN NaN 53 NaN 3.0 NaN 4Replace all NaN elements with 0s.>>> df.fillna(0)A B C D0 0.0 2.0 0.0 01 3.0 4.0 0.0 12 0.0 0.0 0.0 53 0.0 3.0 0.0 4We can also propagate non-null values forward or backward.>>> df.fillna(method='ffill')A B C D0 NaN 2.0 NaN 01 3.0 4.0 NaN 12 3.0 4.0 NaN 53 3.0 3.0 NaN 4Replace all NaN elements in column 'A', 'B', 'C', and 'D', with 0, 1,2, and 3 respectively.>>> values = {'A': 0, 'B': 1, 'C': 2, 'D': 3}>>> df.fillna(value=values)A B C D0 0.0 2.0 2.0 01 3.0 4.0 2.0 12 0.0 1.0 2.0 53 0.0 3.0 2.0 4Only replace the first NaN element.>>> df.fillna(value=values, limit=1)A B C D0 0.0 2.0 2.0 01 3.0 4.0 NaN 12 NaN 1.0 NaN 53 NaN 3.0 NaN 4
参考资料:
用Python玩转数据_中国大学MOOC(慕课)www.icourse163.org







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有