pytorch是非常好用和容易上手的深度学习框架,因为它所构建的是动态图,极大地方便了编写代码和排查错误。本文将模仿Pytorch自动求解梯度的原理,手动实现一个基于Matrix的自动求梯度框架,我们称它为MatrixFlow。本文从原理和代码实现两方面讲解,与pytorch不同的是本文实现的框架底层是matrix而非tensor。在本文中并不考虑并行及GPU加速等复杂的内容,而只考虑如何自动求梯度。原理方面参考网上的优秀文章非原创,MatrixFlow框架代码实现是原创的。最后,在自动求解梯度框架的基础上封装一个前馈神经网络和一个循环神经网络。
知乎这个博主讲解矩阵求导非常好,本文矩阵微分讲解部分参考了他的。博客地址:
长躯鬼侠:矩阵求导术(上)zhuanlan.zhihu.com
矩阵微分是多变量函数微分的推广。矩阵微分(包括矩阵偏导和梯度)是矩阵的重要运算工具之一,在统计学、流行计算、微分几何、计量经济、机器学习等方面有着广泛的应用。在许多工程应用中,参数往往都表示成向量或者据很的形式,对矩阵或者向量求导则变得尤其重要。
首先对变元和函数做统一的定义:
向量函数和矩阵函数在此不介绍,有兴趣的可以参考《矩阵分析与应用》 张贤达著。

上式(1)是Jacobian 矩阵,(2)式是梯度矩阵,两者都是求解微分后的运算结果,它们相差一个转置。在流行计算、几何物理中Jacobian表示方式较多,而在优化领域、机器学习方面梯度矩阵用到的比较多。本节及后面所有小节均采用梯度矩阵方式。
可以看到,标量对矩阵的导数实际上就是标量函数 f 对 矩阵 X 逐元素求导,然后将逐元素求导结果按照X的尺寸排列起来。但是这样做并不好,因为逐元素求导破坏了函数变元的整体性。所以需要寻求一个类似于单变量求导一样不破坏变元完整性的求导方法。
在一元微积分中的导数与微分的关系有
上式可以看成逐元素求导的变元与微分矩阵在同位置相乘的形式,那么可以得到矩阵函数微分:
其中tr代表迹(trace)是方阵对角线元素之和,满足性质:对尺寸相同的矩阵
我们试图利用矩阵导数与微分的联系:
在求出微分
观察一下可以断言,若标量函数f是矩阵X经加减乘法、逆、行列式、逐元素函数等运算构成,则使用相应的运算法则对f求微分,再使用迹技巧给df套上迹并将其它项交换至dX左侧,对照导数与微分的联系
特别地,若矩阵退化为向量,对照导数与微分的联系
在建立法则的最后,来谈一谈复合:假设已求得
解:先使用矩阵乘法、逐元素函数法则求微分:
再套上迹并做交换:
对照导数与微分的联系,
限于我的知识水平有限,而恰巧网上的一篇博客讲解的非常好,所以这里我放上大佬的博客链接,并且就简单介绍下计算图的一些概念。
Lyon:【深度学习理论】一文搞透pytorch中的tensor、autograd、反向传播和计算图zhuanlan.zhihu.com
前向传播就是构建一组运算顺序,在神经网络中就是从输入层 -> 隐藏层 -> 输出层 -> loss 的一组计算过程。因为表达式的计算过程是单向的并且不可颠倒的,所以这一组计算过程是单向的,所以我们称数据流向的方向是前向,这样的传播过程是前向传播。
反向传播是从数据的顶层依次对用到的变量进行求解梯度的过程,根据链式法则,最先参与计算的操作数最后被求解梯度,因为这是一个嵌套多元函数,最外层函数的梯度最先被计算出来。
根据前向传播的过程,可以生成一个计算图,图的结点代表一次运算,图的遍表示数据的流入方向。前向传播的过程是单向的,所以这个计算图是一个有向无环图。
举个例子,对于如下计算:
x = 1
y = 2
z = ( y + x ) * x
可生成如下的计算图:
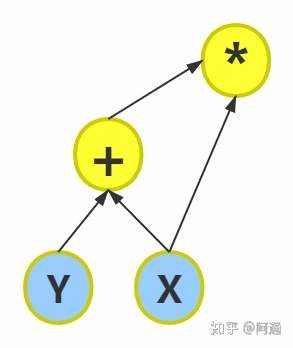
再举一个复杂的例子: 一个神经网络中有5个神经元a,b,c,d,L;其中w1~w4为权重矩阵,L为输出。满足以下计算关系:
b = w1 ∗ a
c = w2 ∗ a
d = w3 ∗ b + w4 ∗ c
L = 10 − d
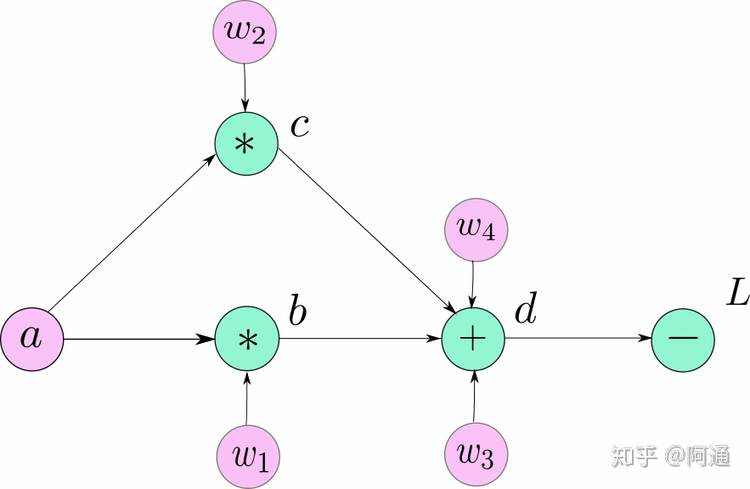
求L对w1的偏导:
求L对a的偏导:
实际上,pytorch计算
但是该文章实现的是MatrixFlow,底层的基本数据是矩阵而不是标量,链式法则并不适用(见1.4小节),所以这里需要进行修改,使用第1节的矩阵微分和迹技巧。
我们欲求
根据前面的讨论,本节我们自己手动完成一个矩阵自动求导的框架,并取名为MatrixFlow。这个矩阵求导框架底层数据是矩阵,并且对于任意一个标量需要表示成[[a]]这种形式。为了验证MatrixFlow的正确性,我们将会对比Pytorch的梯度结果和MatrixFlow的求导结果。最后,在我们的求导框架之上封装一个DNN和一个RNN,并进行简单的深度学习训练。
源代码地址:
https://github.com/tonggege001/MatrixFlowgithub.comMatrixFlow的基本元素是矩阵,那么首先需要定义矩阵在底层的表示方式,它被称作为Node,相当于计算图中的一个结点。根据第2节的讨论,Node的数据类型被定义如下:
def __init__(self, tensor, requires_grad=False):self.tensor = np.array(tensor)self.requires_grad = requires_gradself.grad = 0.0self.grad_fn = Noneself.is_leaf = Trueself.father = Noneself.lchild = Noneself.rchild = Noneself.param = ""
每一个Node结点被表示为左操作数、右操作数、值、操作符类型。tensor是Node结点表达式的值,requires_grad表示为是该表达式是否需要求解梯度,grad表示为该结点的梯度,grad_fn表示为求解梯度时的函数,它的输入是计算图前驱结点的梯度、左操作数、右操作数,输出是左操作数的梯度,右操作数的梯度。is_leaf判断结点是否是叶子结点,在求解梯度时,当遇到叶子结点则不继续往下求导,因为叶子结点的左右孩子是None。father是该计算图的前驱结点,该信息用于调试而不用于正式的计算,一般情况下loss函数前驱前驱结点是None。lchild是左操作数结点,rchild是右操作数结点,param用于调试信息,正式计算时用不到。
紧接着需要定义Node的操作符,这里MatrixFlow的基本操作有加法、减法、乘法、负号、relu、转置、连接操作。
为了方便叙述,这里只给出Node的加法、relu、连接三个操作,其余的操作可以参见源代码。加法操作如下:
# 左侧调用的adddef __add__(self, value):if isinstance(value, (list, np.ndarray)):value = Node(value) # requires_grad=Falsen_tensor = self.tensor + value.tensorn_node = Node(n_tensor)n_node.requires_grad = self.requires_grad or value.requires_gradn_node.grad_fn = grad_addn_node.is_leaf = Falsen_node.lchild = selfn_node.lchild.father = n_noden_node.rchild = valuen_node.rchild.father = n_noden_node.param = "add"return n_node
前三行用来类型转换,Node可以与List、np.ndarray相互转换和计算。第五行用来计算该表达式的值,第六行生成一个Node结点,后面的属性修改依据则是按照第2节的讨论进行。requrires_grad取决于孩子结点的属性,grad_fn是用来求导的函数。
relu操作如下:
def relu(self):n_tensor = np.where(self.tensor > 0, self.tensor, 0)n_node = Node(n_tensor)n_node.requires_grad = self.requires_gradn_node.grad_fn = grad_relun_node.is_leaf = Falsen_node.lchild = selfn_node.lchild.father = n_noden_node.rchild = Nonen_node.param = "relu"return n_node
relu是一个单操作数的运算&#xff0c;其左孩子是原矩阵&#xff0c;右孩子是None&#xff0c;其运算过程是将元素<0的值等于0&#xff0c;其导数定义为grad_relu。
连接操作&#xff1a;
连接操作并不是矩阵的基本操作&#xff0c;因此它没有被定义到Node中&#xff0c;但是我们可以根据基本操作合成一个连接操作。举个例子&#xff0c;输入A, B&#xff0c;求解[A, B]可以表示成Y &#61; A * [I|0] &#43; B * [0|I] &#xff0c;也就是说让矩阵A乘以一个常数矩阵&#xff0c;矩阵B乘以一个常数矩阵&#xff0c;然后相加即可得到。所以连接操作定义如下&#xff1a;
def concat(A: Node, B: Node, axis&#61;1): # 这里先做1维的concat,有空再扩展&#39;&#39;&#39;:param A: A矩阵:param B: B矩阵:return: 拼接后的[A,B]矩阵&#xff0c;因为底层是矩阵&#xff0c;那么拼接函数可以这样实现&#xff1a;Y &#61; A * [I|0] &#43; B * [0|I]&#39;&#39;&#39;if B is None: # 默认return Aif A is None:return Bmask1 &#61; np.zeros((A.tensor.shape[-1], A.tensor[-1]&#43;B.tensor.shape[-1]))mask2 &#61; np.zeros((B.tensor.shape[-1], B.tensor.shape[-1]&#43;A.tensor.shape[-1]))for i in range(A.tensor.shape[-1]):mask1[i][i] &#61; 1for j in range(B.tensor.shape[-1]):mask2[j&#43;A.tensor.shape[-1]][j] &#61; 1mask1 &#61; Node(mask1)mask2 &#61; Node(mask2)Y &#61; A * mask1 &#43; B * mask2return Y
代码中mask1和mask2就是两个常数矩阵&#xff0c;Y则是拼接后的矩阵。
根据第2节的矩阵求导方法&#xff0c;利用微分的链式法则&#xff08;而不是导数的链式法则&#xff09;&#xff0c;结合矩阵微分法则和迹技巧可以求解出导数。考虑如下函数&#xff1a;
其中y和l是标量&#xff0c;f是标量函数&#xff0c;A、B是矩阵&#xff0c;那么求解
对照导数与微分的关系&#xff0c;可以计算出&#xff1a;
那么矩阵乘法的梯度函数可以得到如下&#xff1a;
def grad_mul(gradient, lchild, rchild):return np.matmul(gradient, rchild.tensor.T), np.matmul(lchild.tensor.T, gradient)
其中gradient代表上面的
接下来是最重要的一个函数&#xff0c;backward()函数。backward()函数是一个递归函数&#xff0c;用来计算每一个结点的左右操作数的导数。该函数传入的参数是上式中类似于
在backward函数内&#xff0c;首先积累从上一步计算出来的梯度&#xff0c;然后如果是叶子结点&#xff0c;那么继续反向过程已到底&#xff0c;可以直接退出。如果不是叶子结点&#xff0c;则先分别计算左右两个操作数的导数&#xff0c;如果孩子结点不为空那么递归地反向传播孩子结点。
代码如下&#xff1a;
def backward(self, gradient&#61;np.ones((1, 1), dtype&#61;np.float)):if not self.requires_grad:returnself.grad &#43;&#61; gradientif not self.is_leaf:left_grad, right_grad &#61; self.grad_fn(gradient, self.lchild, self.rchild)if self.lchild is not None:if self.lchild.requires_grad:self.lchild.backward(gradient&#61;left_grad)if self.rchild is not None:if self.rchild.requires_grad:self.rchild.backward(gradient&#61;right_grad)
最后&#xff0c;还需要清空梯度的函数&#xff0c;该函数也是递归的&#xff1a;
def zeros_grad(self):self.grad &#61; 0if self.lchild is not None:self.lchild.zeros_grad()if self.rchild is not None:self.rchild.zeros_grad()return
至此我们的MatrixFlow自动求导框架已经搭建完毕&#xff0c;接下来和pytorch对比求导结果&#xff0c;看看是否正确。
我们创建一个前馈神经网络&#xff0c;然后对比各个参数的梯度&#xff0c;测试代码如下&#xff1a;
if __name__ &#61;&#61; "__main__":# 简单测试与pytorch对比w1 &#61; np.random.uniform(-1, 1, (2, 5))w2 &#61; np.random.uniform(-1, 1, (5, 1))b1 &#61; np.random.uniform(-1, 1, (1, 5))b2 &#61; np.random.uniform(-1, 1, (1, 1))x &#61; np.random.uniform(-3.14, 3.14, (100, 2))y &#61; np.sin(x[:, 0]) &#43; np.cos(x[:, 1])y &#61; y.reshape((y.shape[0], 1))# node 过程W1 &#61; Node(w1, requires_grad&#61;True)W2 &#61; Node(w2, requires_grad&#61;True)B1 &#61; Node(b1, requires_grad&#61;True)B2 &#61; Node(b2, requires_grad&#61;True)hid &#61; Node(x) * W1 &#43; Node(np.ones((x.shape[0], 1))) * B1hid &#61; hid.relu()out &#61; hid * W2 &#43; Node(np.ones((hid.tensor.shape[0], 1))) * B2loss &#61; (Node(y) - out).T() * (Node(y) - out)loss.backward()# tensor 过程WW1 &#61; torch.tensor(w1, requires_grad&#61;True)WW2 &#61; torch.tensor(w2, requires_grad&#61;True)BB1 &#61; torch.tensor(b1, requires_grad&#61;True)BB2 &#61; torch.tensor(b2, requires_grad&#61;True)hhid &#61; torch.mm(torch.tensor(x), WW1) &#43; torch.mm(torch.tensor(np.ones((x.shape[0], 1))), BB1)hhid &#61; hhid.relu()oout &#61; torch.mm(hhid, WW2) &#43; torch.mm(torch.tensor(np.ones((hhid.shape[0], 1))), BB2)lloss &#61; torch.mm((torch.tensor(y) - oout).T , (torch.tensor(y) - oout))lloss.backward()print("Pytorch W1: ")print("{}".format(" ".join(str(e.data.float())for e in WW1[0])))print("{}".format(" ".join(str(e.data.float()) for e in WW1[1])))print("Node W1: ")print("{}".format(" ".join(str(e) for e in W1.tensor[0])))print("{}".format(" ".join(str(e) for e in W1.tensor[1])))print("Pytorch W2: ")print("{}".format(" ".join(str(e) for e in WW2)))print("Node W2: ")print("{}".format(" ".join(str(e) for e in W2.tensor)))print("Pytorch B1: ")print("{}".format(" ".join(str(e) for e in BB1)))print("Node B1: ")print("{}".format(" ".join(str(e) for e in B1.tensor)))print("Pytorch B2: ")print("{}".format(" ".join(str(e) for e in BB2)))print("Node B2: ")print("{}".format(" ".join(str(e) for e in B2.tensor)))
测试结果如下&#xff1a;
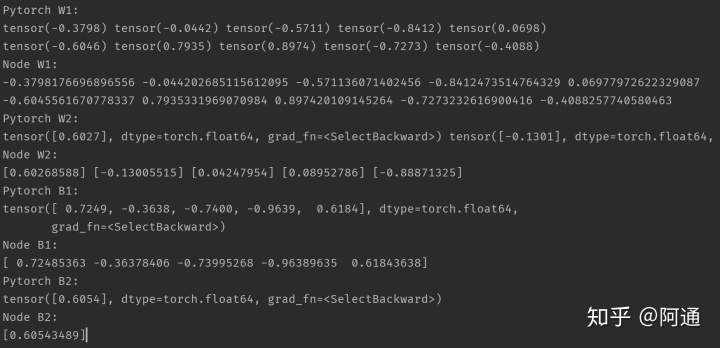
可以看到&#xff0c;MatrixFlow与Pytorch得到的梯度是一样的。
class MLPRegressor:def __init__(self, hidden_size:list, activate&#61;"relu"):self.hidden_size &#61; hidden_sizeself.activate &#61; activateself.weight &#61; []self.bias &#61; []def fit(self, x:np.ndarray, y:np.ndarray):x &#61; Node(x)y &#61; Node(y)self.hidden_size.insert(0, x.tensor.shape[-1])for i in range(len(self.hidden_size)):if i &#61;&#61; len(self.hidden_size)-1:w &#61; np.random.uniform(-1, 1, (self.hidden_size[i], 1))self.weight.append(Node(w, requires_grad&#61;True))b &#61; np.random.uniform(-1, 1, (1,1))self.bias.append(Node(b, requires_grad&#61;True))else:w &#61; np.random.uniform(-1, 1, (self.hidden_size[i], self.hidden_size[i&#43;1]))self.weight.append(Node(w, requires_grad&#61;True))b &#61; np.random.uniform(-1, 1, (1, self.hidden_size[i&#43;1]))self.bias.append(Node(b, requires_grad&#61;True))for epoch in range(1000):for i in range(len(self.hidden_size)):if i &#61;&#61; 0:hid &#61; x * self.weight[i] &#43; Node(np.ones((x.tensor.shape[0], 1))) * self.bias[i]hid &#61; hid.relu()elif i &#61;&#61; len(self.hidden_size) - 1:out &#61; hid * self.weight[i] &#43; Node(np.ones((hid.tensor.shape[0], 1))) * self.bias[i]else:hid &#61; hid * self.weight[i] &#43; Node(np.ones((hid.tensor.shape[0], 1))) * self.bias[i]hid &#61; hid.relu()loss &#61; (y - out).T() * (y - out)loss.backward()for w in self.weight:w.tensor &#61; w.tensor - 0.001 * w.gradw.zeros_grad()for b in self.bias:b.tensor &#61; b.tensor - 0.001 * b.gradb.zeros_grad()returndef predict(self, x:np.ndarray):x &#61; Node(x)for i in range(len(self.hidden_size)):if i &#61;&#61; 0:hid &#61; x * self.weight[i] &#43; Node(np.ones((x.tensor.shape[0], 1))) * self.bias[i]hid &#61; hid.relu()elif i &#61;&#61; len(self.hidden_size) - 1:out &#61; hid * self.weight[i] &#43; Node(np.ones((hid.tensor.shape[0], 1))) * self.bias[i]else:hid &#61; hid * self.weight[i] &#43; Node(np.ones((hid.tensor.shape[0], 1))) * self.bias[i]hid &#61; hid.relu()return out
程序运行结果&#xff1a;
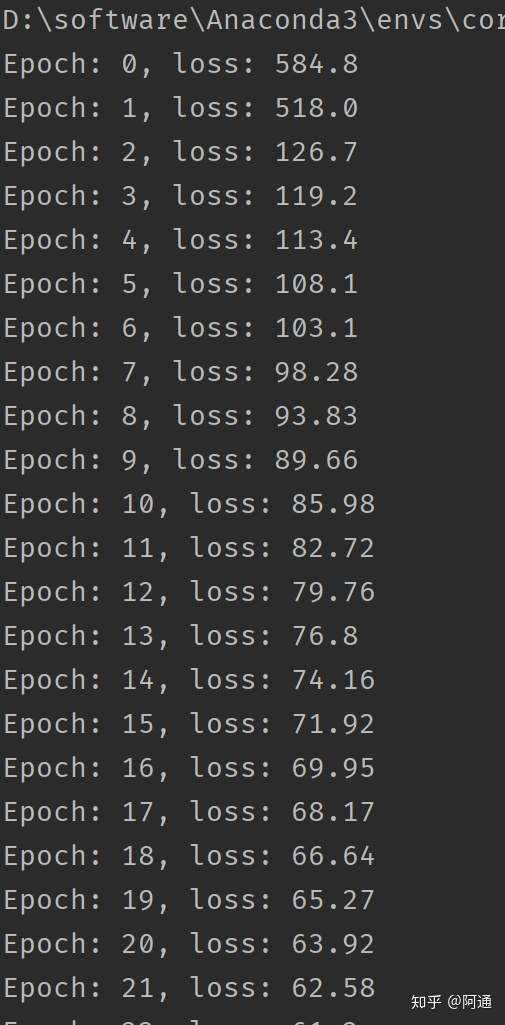
从上图中的损失函数一直递减直到最后收敛可以知道&#xff0c;我们计算的自动求梯度框架MatirxFlow正确地计算出了梯度。
class RNNRegressor:def __init__(self, emb_len, seq_len, out_len):self.seq_len &#61; seq_lenself.emb_len &#61; emb_lenself.out_len &#61; out_lenself.U &#61; Node(np.random.uniform(-1, 1, (emb_len, emb_len)), requires_grad&#61;True)self.W &#61; Node(np.random.uniform(-1, 1, (emb_len, emb_len)), requires_grad&#61;True)self.V &#61; Node(np.random.uniform(-1, 1, (emb_len, out_len)), requires_grad&#61;True)def fit(self, x:np.ndarray, y:np.ndarray, init_hidden:np.ndarray):# x的输入&#xff1a;(样本数, 序列长度, 嵌入维度)&#xff0c;, y(样本数, 输出维度)for epoch in range(100):total_loss &#61; 0for i in range(x.shape[0]):hidden &#61; Node(init_hidden)trg &#61; Node(y[i])loss &#61; Node([[0]])for j in range(x.shape[1]):inp &#61; Node([x[i][j]])hidden &#61; (inp * self.U &#43; hidden * self.W).relu()out &#61; hidden * self.Vloss &#61; loss &#43; (trg - out).T() * (trg - out)loss.backward()total_loss &#43;&#61; loss.tensor[0][0]self.U.tensor &#61; self.U.tensor - 0.001 * self.U.gradself.W.tensor &#61; self.W.tensor - 0.001 * self.W.gradself.V.tensor &#61; self.V.tensor - 0.001 * self.V.gradself.U.zeros_grad()self.W.zeros_grad()self.V.zeros_grad()print("Epoch: {}, Loss: {:.4}".format(epoch, total_loss))def predict(self, x:np.ndarray, init_hidden:np.ndarray):res_list &#61; []for i in range(x.shape[0]):init_hidden &#61; Node(init_hidden)res &#61; Nonefor j in range(x.shape[1]):inp &#61; Node(x[j])init_hidden &#61; (inp * self.U &#43; init_hidden * self.W).relu()out &#61; init_hidden * self.Vres &#61; operators.concat(res, out)self.U.zeros_grad()self.V.zeros_grad()self.W.zeros_grad()res_list.append(res.tensor)return res_list
对RNN进行训练并查看损失函数的变化&#xff1a;
if __name__ &#61;&#61; "__main__":# 测试RNNrnn &#61; RNNRegressor(emb_len&#61;3, seq_len&#61;4, out_len&#61;1)x &#61; np.random.uniform(-1, 1, (20, 6, 3))# y &#61; (np.dot(x[:,0], x[:, 1]) &#43; np.dot(x[:,2], x[:,3])) / 2y &#61; []for i in range(x.shape[0]):res &#61; np.dot(x[i][0], x[i][1]) &#43; np.dot(x[i][2], x[i][3])res &#61; res / 2y.append([[res]])rnn.fit(x, y, np.random.uniform(-1, 1, (1, 3)))
程序运行结果&#xff1a;
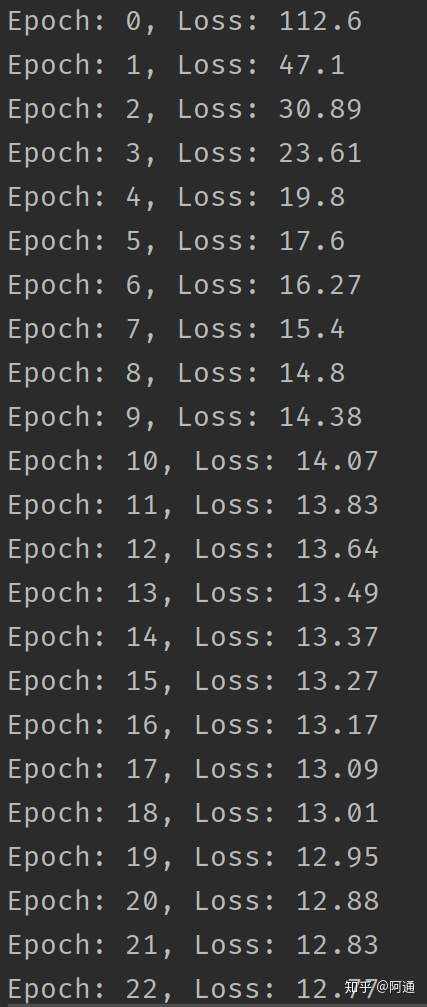
可以看到RNN的损失正在下降。
文章写得匆忙&#xff0c;可能会有错误&#xff1b;代码写得匆忙&#xff0c;可能会有bug&#xff0c;望见谅。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
