Introducation
本文修正了关于前段时间对于requests自动保存COOKIEs和header的使用错误。
requests
python有个库是requests,比更底层的urllib等更加方便简易。而且自带管理COOKIE,headers等功能。
在python爬虫学习(四)获取COOKIE中,简单介绍了获取COOKIE的方法,而实际上,requests会自动管理COOKIEs。
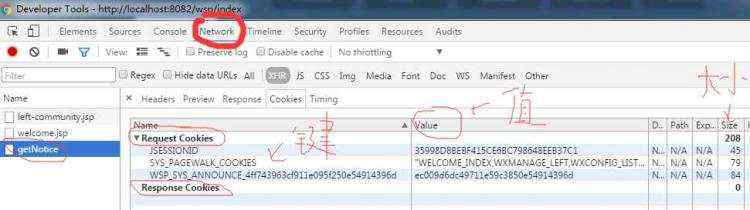
在通过requests get或者post网页之后,如果是第一次访问某些页面,在网页的response headers里会有set-COOKIEs的字段,而requests会识别这些字段,同时在接下来的get\post行为中,自动添加这些COOKIEs。
检验
以访问百度为例:
import requests
conn = requests.session()
resp = conn.get('https://www.baidu.com/s?wd=findspace')
# 打印请求的头
print(resp.request.headers)
# 打印结果如下,requests已经自动填充了部分数据
{'Connection': 'keep-alive', 'User-Agent': 'python-requests/2.4.3 CPython/3.4.2 Linux/3.16.0-4-amd64', 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate'}
# 再访问一次:
resp = conn.get('https://www.baidu.com/s?wd=findspace')
print(resp.request.headers)
{'Connection': 'keep-alive', 'User-Agent': 'python-requests/2.4.3 CPython/3.4.2 Linux/3.16.0-4-amd64', 'Accept': '*/*', 'COOKIE': 'BD_NOT_HTTPS=1; BDSVRTM=3; PSTM=1458389621; BIDUPSID=9CB03BE7D7F436EC2EE23C6E6EBE8EBD', 'Accept-Encoding': 'gzip, deflate'}
可以看到请求中已经自动加上了COOKIE,但是也可以看到,user-agent是'python-requests/2.4.3 CPython/3.4.2 Linux/3.16.0-4-amd64',可以通过前几篇中说的设置headers的方法来设置
headers = {
"method": "POST",
"scheme": "https",
"version": "HTTP/1.1",
"accept": "*/*",
"accept-encoding": "gzip, deflate",
"accept-language": "en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4",
"content-type": "application/x-www-form-urlencoded;charset=UTF-8",
"dnt": "1",
"faces-request": "partial/ajax",
"origin": "https://www.baidu.com",
"referer": "https://www.baidu.com",
}
resp = conn.get(url, headers=headersm timeout=60)
注意此时的头会和requests填充的头相互补充,但是用户自定义的头具有高优先级。比如,你在headers里填充COOKIEs为自己的数据,则在本次请求中会覆盖requests之前给你保存的COOKIEs。
也就不用像前文一样去手动保存COOKIE了。







 京公网安备 11010802041100号
京公网安备 11010802041100号