元素,这个元素里含有书籍信息。for data in datas:#遍历data。item = DoubanItem()#实例化DoubanItem这个类。item['title'] = data.find_all('a')[1]['title']#提取出书名,并把这个数据放回DoubanItem类的title属性里。item['publish'] = data.find('p',class_='pl').text#提取出出版信息,并把这个数据放回DoubanItem类的publish里。item['score'] = data.find('span',class_='rating_nums').text#提取出评分,并把这个数据放回DoubanItem类的score属性里。print(item['title'])#打印书名。yield item#yield item是把获得的item传递给引擎。 在3行,我们需要引用DoubanItem,它在items里面。因为是items在top250.py的上一级目录,所以要用..items,这是一个固定用法。
当我们每一次,要记录数据的时候,比如前面在每一个最小循环里,都要记录“书名”,“出版信息”,“评分”。我们会实例化一个item对象,利用这个对象来记录数据。
每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。这里,要用到yield语句。
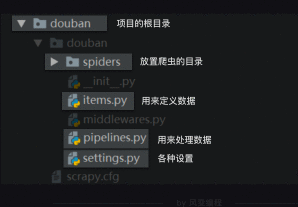
定义数据的过程在item.py完成,相当于数据管道上完成。
-----定义数据-----
item.py
import scrapy
#导入scrapy
class DoubanItem(scrapy.Item):
#定义一个类DoubanItem,它继承自scrapy.Itemtitle = scrapy.Field()#定义书名的数据属性publish = scrapy.Field()#定义出版信息的数据属性score = scrapy.Field()#定义评分的数据属性

如果用可视化的方式来呈现程序运行的过程,就如同上图所示:爬虫(Spiders)会把豆瓣的10个网址封装成requests对象,引擎会从爬虫(Spiders)里提取出requests对象,再交给调度器(Scheduler),让调度器把这些requests对象排序处理。
然后引擎再把经过调度器处理的requests对象发给下载器(Downloader),下载器会立马按照引擎的命令爬取,并把response返回给引擎。
紧接着引擎就会把response发回给爬虫(Spiders),这时爬虫会启动默认的处理response的parse方法,解析和提取出书籍信息的数据,使用item做记录,返回给引擎。引擎将它送入Item Pipeline(数据管道)处理。
-----设置-----
点击settings.py文件,你能在里面找到如下的默认设置代码,不然会出现一些报错信息:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'douban (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = True
1.删除USER _AGENT的注释,并到网页上右击,network找到USER_AGENT的值,并赋值上去
2.ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False,就是把遵守robots协议换成无需遵从robots协议,这样Scrapy就能不受限制地运行。
修改后如下:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'# Obey robots.txt rules
ROBOTSTXT_OBEY = False
-----运行-----
cmd --切记在douban目录下,运行命令scrapy crawl douban,不然会报错
总结用法

存储数据
csv存储
在setting.py里面,添加下面代码,即可!
FEED_URI='./storage/data/%(name)s.csv'
FEED_FORMAT='CSV'
FEED_EXPORT_ENCODING='ansi'
解读:
FEED_URI是导出文件的路径。'./storage/data/%(name)s.csv',就是把存储的文件放到与settings.py文件同级的storage文件夹的data子文件夹里。
FEED_FORMAT 是导出数据格式,写CSV就能得到CSV格式。
FEED_EXPORT_ENCODING 是导出文件编码,ansi是一种在windows上的编码格式,你也可以把它变成utf-8用在mac电脑上。-------------------------------------------------------------------------------------
Excel存储
1.取消ITEM_PIPELINES的注释(删掉#)即可
#取消`ITEM_PIPELINES`的注释后:# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'jobuitest.pipelines.JobuitestPipeline': 300,
}
2.修改pipelines.py代码
pipelines.py
下面是本人其他的一个案例的一个存储,作为参考即可!
import openpyxlclass JobuiPipeline(object):
#定义一个JobuiPipeline类,负责处理itemdef __init__(self):#初始化函数 当类实例化时这个方法会自启动self.wb =openpyxl.Workbook()#创建工作薄self.ws = self.wb.active#定位活动表self.ws.append(['公司', '职位', '地址', '招聘信息'])#用append函数往表格添加表头def process_item(self, item, spider):#process_item是默认的处理item的方法,就像parse是默认处理response的方法line = [item['company'], item['position'], item['address'], item['detail']]#把公司名称、职位名称、工作地点和招聘要求都写成列表的形式,赋值给lineself.ws.append(line)#用append函数把公司名称、职位名称、工作地点和招聘要求的数据都添加进表格return item#将item丢回给引擎,如果后面还有这个item需要经过的itempipeline,引擎会自己调度def close_spider(self, spider):#close_spider是当爬虫结束运行时,这个方法就会执行self.wb.save('./jobui.xlsx')#保存文件self.wb.close()#关闭文件
3.在最后,我们还要再修改Scrapy中settings.py文件里的默认设置:添加请求头,以及把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False。
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.5
4.还有DOWNLOAD_DELAY = 0这行的注释(删掉#)。DOWNLOAD_DELAY翻译成中文是下载延迟的意思,这行代码可以控制爬虫的速度。因为这个项目的爬取速度不宜过快,我们要把下载延迟的时间改成0.5秒。
最后运行scrapy crawl+项目名称
保存的文件是在根目录下
推荐阅读
-
本文介绍了使用正则表达式来爬取36Kr网站首页所有新闻的操作步骤和代码示例。通过访问网站、查找关键词、编写代码等步骤,可以获取到网站首页的新闻数据。代码示例使用Python编写,并使用正则表达式来提取所需的数据。详细的操作步骤和代码示例可以参考本文内容。 ...
[详细]
蜡笔小新 2023-12-12 19:16:21
-
这是原文链接:sendingformdata许多情况下,我们使用表单发送数据到服务器。服务器处理数据并返回响应给用户。这看起来很简单,但是 ...
[详细]
蜡笔小新 2023-12-14 16:19:10
-
-
原文地址:https:www.cnblogs.combaoyipSpringBoot_YML.html1.在springboot中,有两种配置文件,一种 ...
[详细]
蜡笔小新 2023-12-14 12:39:13
-
本文介绍了在Windows系统下配置PHP5.6的步骤及注意事项,包括下载PHP5.6、解压并配置IIS、添加模块映射、测试等。同时提供了一些常见问题的解决方法,如下载缺失的msvcr110.dll文件等。通过本文的指导,读者可以轻松地在Windows系统下配置PHP5.6,并解决一些常见的配置问题。 ...
[详细]
蜡笔小新 2023-12-14 12:37:25
-
本文讨论了一个关于cuowu类的问题,作者在使用cuowu类时遇到了错误提示和使用AdjustmentListener的问题。文章提供了16个解决方案,并给出了两个可能导致错误的原因。 ...
[详细]
蜡笔小新 2023-12-13 22:09:56
-
本文介绍了PhysioNet网站提供的生理信号处理工具箱WFDB Toolbox for Matlab的安装和使用方法。通过下载并添加到Matlab路径中或直接在Matlab中输入相关内容,即可完成安装。该工具箱提供了一系列函数,可以方便地处理生理信号数据。详细的安装和使用方法可以参考本文内容。 ...
[详细]
蜡笔小新 2023-12-13 20:46:48
-
怀疑是每次都在新建文件,具体代码如下 ...
[详细]
蜡笔小新 2023-12-13 17:53:49
-
项目重构的Git地址:https:github.comrazerdpFriendCircletreemain-dev项目同步更新的文集:http:www.jianshu.comno ...
[详细]
蜡笔小新 2023-12-11 19:09:56
-
本文介绍了响应式页面的概念和实现方式,包括针对不同终端制作特定页面和制作一个页面适应不同终端的显示。分析了两种实现方式的优缺点,提出了选择方案的建议。同时,对于响应式页面的需求和背景进行了讨论,解释了为什么需要响应式页面。 ...
[详细]
蜡笔小新 2023-12-11 12:37:10
-
本文介绍了一个超级简单的加解密工具的方案和功能。该工具可以读取文件头,并根据特定长度进行加密,加密后将加密部分写入源文件。同时,该工具也支持解密操作。加密和解密过程是可逆的。本文还提到了一些相关的功能和使用方法,并给出了Python代码示例。 ...
[详细]
蜡笔小新 2023-12-10 16:38:34
-
本文介绍了解决IDEA窗口文件上面的类导航栏不见的问题的方法,通过在File-Settings-Editor-General-Editor Tabs-Tab placement中选择top即可解决该问题。 ...
[详细]
蜡笔小新 2023-12-10 14:21:43
-
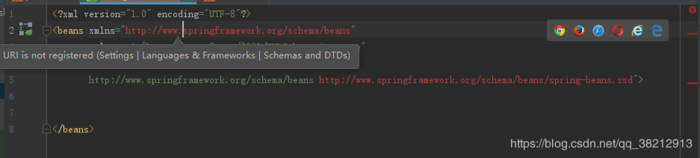
本文介绍了解决IDEA配置xml文件头报错的方法,包括了具体的解决方案和步骤。通过本文的指导,读者可以轻松解决这个问题并正常使用IDEA进行开发工作。 ...
[详细]
蜡笔小新 2023-12-10 13:53:24
-
在生产环境中,只打印error级别的错误,在测试环境中,可以调成debugapplication.properties文件##默认使用logbacklogging.level.r ...
[详细]
蜡笔小新 2023-12-09 19:56:03
-
本文介绍了使用.NetCoreWebApi生成Swagger接口文档的方法,并详细说明了Swagger的定义和功能。通过使用Swagger,可以实现接口和服务的可视化,方便测试人员进行接口测试。同时,还提供了Github链接和具体的步骤,包括创建WebApi工程、引入swagger的包、配置XML文档文件和跨域处理。通过本文,读者可以了解到如何使用Swagger生成接口文档,并加深对Swagger的理解。 ...
[详细]
蜡笔小新 2023-12-09 19:33:41
-
本文讨论了将HashRouter改为Router后,页面全部变为空白页且没有报错的问题。作者提到了在实际部署中需要在服务端进行配置以避免刷新404的问题,并分享了route/index.js中hash模式的配置。文章还提到了在vueJs项目中遇到过类似的问题。 ...
[详细]
蜡笔小新 2023-12-09 10:26:51
-
刘刚michaelup_340
这个家伙很懒,什么也没留下!









 京公网安备 11010802041100号
京公网安备 11010802041100号