re模块
可以读懂你写的正则表达式
根据你写的表达式去执行任务
用re去操作正则
正则表达式
使用一些规则来检测一些字符串是否符合个人要求,从一段字符串中找到符合要求的内容。在线测试网站: http://tool.chinaz.com/regex/
元字符:用来表示范围
| 元字符 | 匹配内容 |
| . | 匹配除换行符\n以外的任意字符 |
| ^ | 只匹配字符串的开始 |
| $ | 只匹配字符串的结束 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \W | 匹配非字母数字和下划线 |
| \S | 匹配非空白符 |
| \D | 匹配非数字 |
| a|b | 匹配字符a或b |
| () | 匹配括号内的表达式,也表示一个组 |
| [ ] | 匹配字符组的字符 |
| [^ ] | 匹配除了字符组中字符的所有字符 |
# 在字符组[ ]中,-表示范围,一般是根据字符对应的码值(字符在对应编码表中的编码的数值)来确定的,码值小的在前,码值大的在后。
# 在ascll编码表中, 0-9对应码值是48-57,a-z的码值是97-122,A-Z对应码值65-90
量词:
| 量词 | 用法说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次,可匹配也可不匹配 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
.*?的用法说明:
. 任意字符
* 取0至无限长度
? 非贪婪模式
.*?x 合在一起表示取尽量少的任意字符,知道一个x出现
其他使用说明:
* + ? { }:

注: *,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
字符集[][^]:
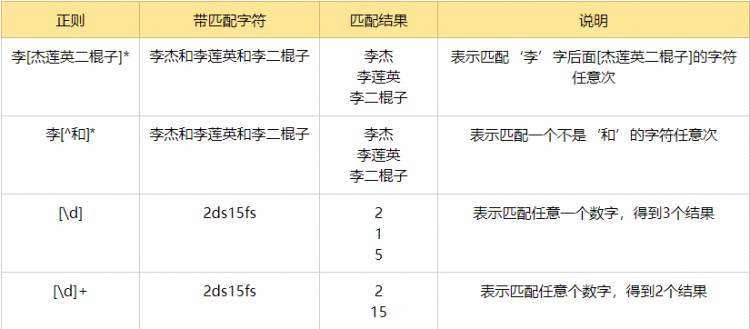
分组 ()与 或 |[^]:
身份证号是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能是0
如果是18位,则前17位全部是数字,末尾可能是x
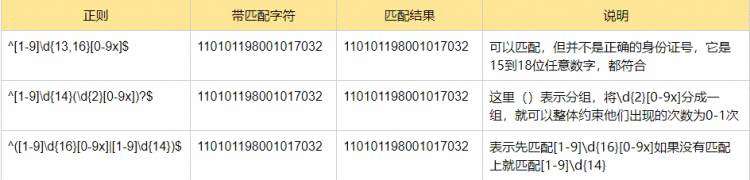
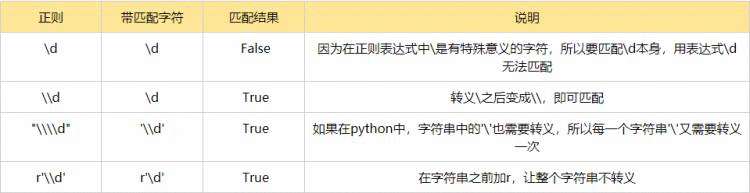
转义符 \:
在正则中,存在很多特殊意义的元字符,如\d,\s等,如果要在正则中匹配正常的‘\d’而不是‘数字’就需要对‘\d’进行转义,变成‘\\’
在py中,无论是正则表达式还是待匹配内容都是以字符串形式出现的,字符串中\也有特殊含义,本身也需要转义,这时候就要用到r‘\d’转换
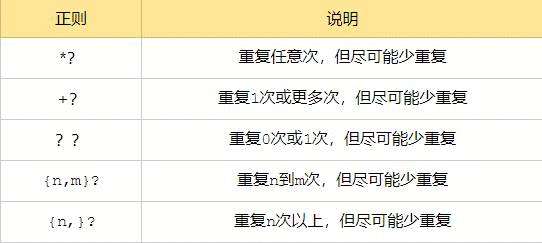
贪婪匹配:
满足匹配时,匹配尽可能长的字符串

几个常用非贪婪匹配格式
re模块下的常用方法
import re
ret = re.findall('a', 'eva egon yuan')
print(ret) # ['a', 'a']ret = re.findall('\d+', 'dsaglhlkdfh1892494kashdgkjh127839')
print(ret) # ['1892494', '127839']# findall接收两个参数 : 正则表达式 要匹配的字符串
# 一个列表数据类型的返回值:所有和这条正则匹配的结果ret = re.search('a', 'eavegonyaun').group()
print(ret) # a# 函数会在字符串内查找模式匹配,直到找到第一个匹配然后返回一个包含匹配信息的对象,该
# 对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,未调用group时
# 则返回None。# search和findall的区别:
# 1.search找到一个就返回,findall是找所有
# 2.findall是直接返回一个结果的列表,search返回一个对象ret = re.match('foo', 'fooid')
if ret:print(ret.group())
'foo'
# 意味着在正则表达式中添加了一个^
# 同search,不过只从字符串的开始部分对模式进行匹配,ret = re.sub('\d', 'H', 'eva3egon4yuan4', 2)
print(ret) # evaHegonHyuan4
# 将前两个数字换成Hret = re.subn('\d', 'H', 'eva3egon4yuan4')
print(ret) # ('evaHegonHyuanH', 3)
# #将数字替换成'H',返回元组(替换的结果,替换了多少次)ret = re.split("\d+", "eva3egon4yuan")
print(ret) # ['eva', 'egon', 'yuan']
ret = re.split("(\d+)", "eva162784673egon44yuan")
print(ret) # ['eva', '162784673', 'egon', '44', 'yuan']
# split分割一个字符串,默认被匹配到的分隔符不会出现在结果列表中,
# 如果将匹配的正则放到组内,就会将分隔符放到结果列表里# 在多次执行同一条正则规则的时:
obj = re.compile('\d{3}')
ret1 = obj.search('abc123eeee')
ret2 = obj.findall('abc123eeee')
print(ret1.group()) # 123
print(ret2) # ['123']
# 如果匹配文件中的手机号,可以进行这样的一次编译,节省时间# finditer适用于结果比较多的情况下,能够有效的节省内存
ret = re.finditer('\d', 'ds3sy4784a')
print(ret) #
print(next(ret).group()) # 查看第一个结果
print(next(ret).group()) # 查看第二个结果
print([i.group() for i in ret]) # 查看剩余的左右结果
compile格式:
re.compile(pattern,flags=0)
pattern: 编译时用的表达式字符串。
flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的flags有:
| 标志 | 含义 |
| re.S(DOTALL) | 使.匹配包括换行在内的所有字符 |
| re.I(IGNORECASE) | 使匹配对大小写不敏感 |
| re.L(LOCALE) | 做本地化识别(locale-aware)匹配,法语等 |
| re.M(MULTILINE) | 多行匹配,影响^和$ |
| re.X(VERBOSE) | 该标志通过给予更灵活的格式以便将正则表达式写得更易于理解 |
| re.U | 根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B |
分组:
如果对一组正则表达式整体有一个量词约束,就将这一组表达是分成一个组
要想取消分组优先效果,在组内开始的时候加上?: 这个很关键的
# 当分组遇到re模块
import re
ret1 = re.findall('www.(baidu|oldboy).com', 'www.baidu.com')
ret2 = re.findall('www.(?:baidu|oldboy).com', 'www.baidu.com')
print(ret1)
print(ret2)
# findall会优先显示组内匹配到的内容返回
# 如果想取消分组优先效果,在组内开始的时候加上?:# 分组的意义
# 1.对一组正则规则进行量词约束
# 2.从一整条正则规则匹配的结果中优先显示组内的内容
# "hello
"
ret &#61; re.findall(&#39;<\w&#43;>(\w&#43;)&#39;, "hello
")
print(ret) # [&#39;hello&#39;]# 分组命名 ?p固定语法&#xff0c;p大写
ret &#61; re.search("<(?Phello
")
print(ret.group()) # hello
&#xff0c;search中没有分组优先的概念
print(ret.group(&#39;tag&#39;)) # h1
print(ret.group(&#39;content&#39;)) # hello# 如果不给组起名字&#xff0c;也可以用\序号来找到对应的组&#xff0c;表示要找的内容和前面的组内容一致
# 获取的匹配结果可以直接用group(序号)拿到对应的值
ret &#61; re.search(r"<(\w&#43;)>(\w&#43;)", "hello
")
print(ret.group()) # hello
print(ret.group(0)) # hello
print(ret.group(1)) # h1
print(ret.group(2)) # hello
分组进阶&#xff1a;
s &#61; &#39;2017-07-10 20:00&#39;
p &#61; re.compile(r&#39;(((\d{4})-\d{2})-\d{2}) (\d{2}):(\d{2})&#39;)
re.findall(p,s)
# 输出&#xff1a;
# [(&#39;2017-07-10&#39;,&#39;2017-07&#39;,&#39;2017&#39;,&#39;20&#39;,&#39;00&#39;)]
se &#61; re.search(p,s)
print se.group()
print se.group(0)
print se.group(1)
print se.group(2)
print se.group(3)
print se.group(4)
print se.group(5)# 输出&#xff1a;
&#39;&#39;&#39;
&#39;2017-07-10 20:00&#39;
&#39;2017-07-10 20:00&#39;
&#39;2017-07-10&#39;
&#39;2017-07&#39;
&#39;2017&#39;
&#39;20&#39;
&#39;00&#39;
&#39;&#39;&#39;
关于split的优先级查询问题&#xff1a;
在匹配部分加上&#xff08;&#xff09;之后所切出的结果是不同的&#xff0c;没有&#xff08;&#xff09;的没有保留所匹配的项&#xff0c;但是有&#xff08;&#xff09;的却能够保留了匹配的项
import re
ret &#61; re.split(&#39;\d&#43;&#39;,&#39;ds22glhfh124dgkjh1&#39;)
print(ret) # [&#39;ds&#39;, &#39;glhfh&#39;, &#39;dgkjh&#39;, &#39;&#39;]
# 这里最后一位有空格是由于它左边有东西而右边没有了&#xff0c;所以用空格替代了
ret &#61; re.split(&#39;(\d&#43;)&#39;,&#39;ds22glhfh124dgkjh1&#39;)
print(ret) # [&#39;ds&#39;, &#39;22&#39;, &#39;glhfh&#39;, &#39;124&#39;, &#39;dgkjh&#39;, &#39;1&#39;, &#39;&#39;]
ret &#61; re.split(&#39;(?:\d&#43;)&#39;,&#39;ds22glhfh124dgkjh1&#39;)
print(ret) # [&#39;ds&#39;, &#39;glhfh&#39;, &#39;dgkjh&#39;, &#39;&#39;]
应用&#xff1a;
# 获取当中的字母
s &#61;&#39;abc &#64; 124&#xff0c;efg opAs4&#39;
import re
a &#61; &#39;&#39;.join(re.findall(&#39;[a-zA-Z]&#39;,s))
print(a)
b &#61; re.sub(&#39;[^a-zA-Z]&#39;,&#39;&#39;, s)
print(b)
c &#61; &#39;&#39;.join(re.split(&#39;[^a-zA-Z]&#39;,s))
print(c)
关于整数匹配问题&#xff0c;如匹配1-2*(60&#43;(-40.35/5)-(-4*3))中的整数
import re
ret &#61; re.findall(r&#39;-?\d&#43;\.\d*|(-?\d&#43;)&#39;,a)
ret.remove(&#39;&#39;)
print(ret)
利用正则制作计算器&#xff1a;点击这里>>
利用正则爬去豆瓣网页
#!/usr/bin/env python # -*- coding:utf-8 -*- 相关问题&#xff1a; 1.re的match和search区别&#xff1f; 转:https://www.cnblogs.com/LearningOnline/p/8967704.html
# author: Learning time:2018/9/28import time
import re
from urllib.request import urlopendef getPage(url):response &#61; urlopen(url) # 通过response&#61;requests.get(url)获取也OKreturn response.read().decode(&#39;utf-8&#39;) # 直接返回response.textdef parsePage(s):com &#61; re.compile(&#39;
re.match() 从第一个字符开始找, 如果第一个字符就不匹配就返回None, 不继续匹配. 用于判断字符串开头或整个字符串是否匹配,速度快.
re.search() 会整个字符串查找,直到找到一个匹配。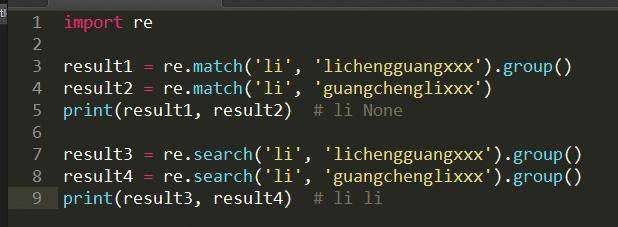





![BUUCTF [ZJCTF 2019] NiZhuanSiWei 解题报告](https://img6.php1.cn/3cdc5/c45f/1c8/3b2568bcc38297e4.jpeg)

 京公网安备 11010802041100号
京公网安备 11010802041100号