

大家好,基于Python的数据科学实践课程又到来了,大家尽情学习吧。本期内容主要由程茜与政委联合推出。
在实际数据科学项目中,继数据清洗与整理、描述分析之后,要进行深入的分析,建模是必不可少的非常重要的环节。Python 中统计建模分析的核心模块是Statsmodels。其官方文档中也用了一段话来描述这个模块:statsmodels is a Python module that provides classes and functions for the estimation of many different statistical models, as well as for conducting statistical tests, and statistical data exploration。也就是说这个模块中包含了几乎所有常见的回归模型、非参数模型和时间序列分析模型等统计建模方法。本章试图通过以火锅团购数据为基础就常用的模型来为大家开启statsmodels学习之路。
 5.1 Statsmodel简介
5.1 Statsmodel简介
获取或安装Statsmodels的最简单方法是通过Anaconda安装,然后载入Statsmodels模块。
import statsmodels.api as sm
statsmodels模块的主要功能既然是统计建模,自然是围绕统计建模的功能展开的。具体而言为:

参数估计:包含例如线性、非线性回归以及时间序列分析等模型的参数估计。
假设检验:包含例如方差分析、线性与非线性回归,以及时间序列分析等模型的估计参数的假设检验。
探索分析:包含列联表、链式方程多重插补等探索性数据分析方法以及与统计模型结果的可视化图表,例如拟合图、箱线图、相关图、函数图、回归图、时间序列图等。
除了这些具体功能外,statsmodels还为Python的学习者贴心地提供了用于进行编程实操训练的数据集。
在接下来的内容里,我们会结合火锅团购数据以及statsmodels自带的数据集,从statsmodels的三大主要功能给大家简要介绍statsmodels的使用。
使用statsmodels时必须接入数据,而这里数据又分为内部数据与外部数据。所谓内部数据就是statsmodels模块自带的数据集,可供学习时调用。而外部数据的接入,可以理解为用某些函数导入特定的存储格式的外部数据,例如第三章讲解的Pandas与第九章会讲解的数据库中的函数。所以这里对于外部数据的导入,大家可以参考这两部分。下面我们查看一下statsmodels里面有哪些自带数据集,并学习如何导入内部数据。
在学习各种数据分析的软件时,相信很多同学都会有这么一种感受,数据?数据?从哪里找数据啊!宝宝心里苦啊!爬虫怎么样?不会啊!从统计局网站上下数据,用户体验也不好,想好好学数据分析,没想到先被数据给卡住了。其实python还是很贴心的,statsmodels 库中不仅包含了统计模型,还包含了统计数据。这个库里的数据可以拿来操练。
首先,列出这个模块中包含的数据。
例1 获取自带数据集
import statsmodels.api as sm
from pandas import DataFrame
dataDict = {'name':[], 'describe_short':[]}
for modstr in dir(sm.datasets):
try:
mod = eval('sm.datasets.%s' % modstr)
dataDict['describe_short'].append(mod.DESCRSHORT)
dataDict['name'].append(modstr)
except Exception as e:
print("该模块无 DESCRSHORT 属性:\n", e)
continue
dataDf = DataFrame({'describe_short':dataDict['describe_short']}, index=dataDict['name'])
print(dataDf)
从例1的结果可以看到这个库中还是有不少数据可以用来练手的,比如:cancer、fair、strikes等数据集。

图1 模块自带数据集
数据有了,如何导入一个数据集练手呢?以cancer数据集为例,可以通过以下方法进行调用。
例2 导入cancer数据集
import statsmodels.api as sm
from pandas import DataFrame
cancer_data = sm.datasets.scotland.load_pandas()
print(type(cancer_data)) # DataFrame 类型的数据
df=cancer_data.data
df.head()
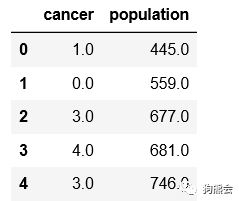
由此,我们可以查看这个数据集的具体内容。具体见表1。
表1 cancer数据集
如果想进一步知道cancer数据集的具体是内容,可以直接打印它的属性。
例3 cancer数据集属性
cancer_mod = sm.datasets.cancer
print (cancer_mod.DESCRLONG)
这个数据集的属性很简单,记录了各县市乳腺癌发病次数。
5.3统计模型参数估计1、用Patsy描述统计模型前面一节里已经阐述satasmodels模块中统计模型众多,本部分希望通过简单的线性回归的讲解带领大家入门。其他类型的模型的调用与线性回归的方法类似。大家可后续扩展学习。具体地,我们会结合Python的另一个库Patsy,针对火锅数据建立简单的回归模型并进行描述。
Patsy是一个用于描述统计模型和构建设计矩阵(可以理解样本矩阵X)的库,针对线性模型或具有线性组件的模型应用尤其广泛。它使用简短的字符串“公式语法”来描述统计模型,熟悉R和S编程语言的小伙伴们应该会认为它非常亲切。
所谓“公式语法”,则是指其特殊格式的字符串:
y ~ x0 + x1
这里x0+x1并不是将x0和x1相加的意思,而是代表为模型创建的设计矩阵的术语。即表示y要对x0与x1变量进行线性回归。patsy.dmatrices函数可以接收一个公式字符串和一个数据集(可以是DataFrame或dict),然后为线性模型产生设计矩阵。
例4 用patsy.dmatrices函数为模型产生设计矩阵
import patsy #导入patsy库
y, X = patsy.dmatrices('购买人数 ~ 评分 + 评价数', model_data) #为模型产生设计矩阵
y
X

图2a Patsy DesignMatrix实例(y)

图2b Patsy DesignMatrix实例(X)
这些Patsy DesignMatrix实例是Numpy的ndarrays,附有额外的元数据(metadata)。
例5 查看所有元数据
np.asarray(X) #查看所有元数据
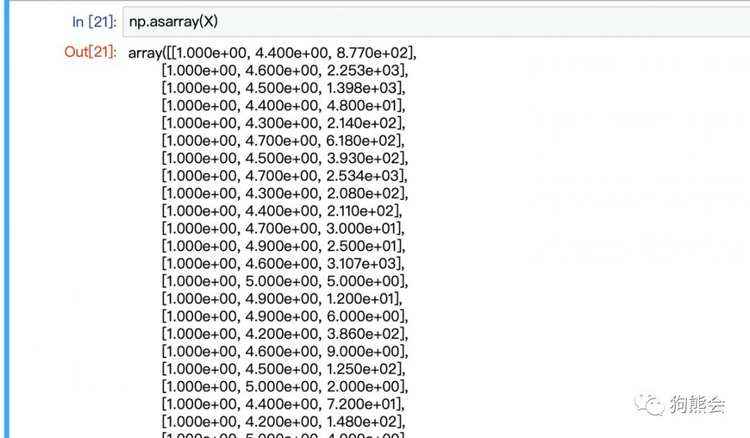
图3 查看所有元数据
我们会注意到,在patsy.dmatrices函数生成的设计矩阵里有一个Intercept,这是线性模型(例如最小二乘回归模型)的使用惯例。如果想要去掉这个截距,可以选择在公式语法中添加“+0”术语。
例6 去掉线性模型中的截距
patsy.dmatrices('购买人数 ~ 评分 + 评价数 + 0', model_data)[1]

图4 去掉截距后的设计矩阵
这种Patsy对象可以直接传入一个算法,比如numpy.linalg.lstsq,来进行普通最小二乘回归的计算。
例7 计算最小二乘回归拟合系数
coef, resid, _, _ = np.linalg.lstsq(X, y, rcond = -1) #将patsy对象传递给最小二乘回归算法
coef #输出拟合系数
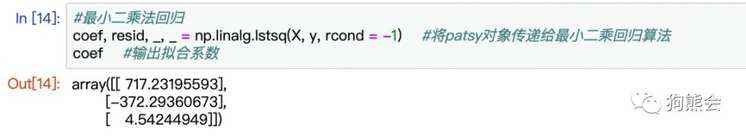
图5 最小二乘回归拟合系数运算结果
模型的元数据保留在design_info属性中,因此可以将拟合系数转化为series,并为其添加列名。
例8 将拟合系数转化为series
coef = pd.Series(coef.squeeze(), index = X.design_info.column_names) #将拟合系数转化为series
coef #输出拟合系数

图6 将拟合系数转化为series运算结果
除此之外,我们还可以将Python代码和Patsy公式混合起来使用,让Patsy帮我们进行一些基础的数据转化。例如针对我们的火锅数据,认为购买人数的分布非常不均匀,因此将其对数化之后再进行最小二乘回归,此时就可以使用Python代码和Patsy公式的结合。
例9 用Patsy公式进行数据转化
y, X = patsy.dmatrices('np.log(购买人数 + 1) ~ 评分 + 评价数 + 1', model_data) #用pasty公式进行数据转化
y #输出y

图7 用Patsy公式进行数据转化运行结果
除了对数变换之外,Patsy还有其他内置的函数来进行常见的变量转换,包括标准化(平均值为0,方差为1)和中心化(减去平均值)。更多关于变量转化的详细信息可参考Patsy的官方文档。
好了,今天就讲到这里。
▼往期精彩回顾▼初步搭建数据科学工作环境
Conda的使用
Spyder入门
Jupyter入门
Markdown
简单读写数据
数据类型
数据结构
控制流
函数与模块
Numpy
pandas1
pandas2
pandas3
pandas4
绘图模块1
绘图模块2
绘图模块3
绘图模块4













 京公网安备 11010802041100号
京公网安备 11010802041100号