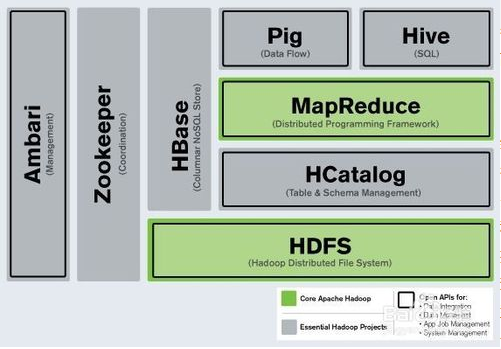
1. HDFS(分布式文件系统):
它与现存的文件系统不同的特性有很多,比如高度容错(即使中途出错,也能继续运行),支持多媒体数据和流媒体数据访问,高效率访问大型数据集合,数据保持严谨一致,部署成本降低,部署效率提交等。
2. MapReduce(并行计算架构):
它可以将计算任务拆分成大量可以独立运行的子任务,接着并行运算,另外会有一个系统调度的架构负责收集和汇总每个子任务的分析结果。其中 包含映射算法与规约算法。
3. Pig/Hive(Hadoop编程):
Pig是一种高级编程语言,在处理半结构化数据上拥有非常高的性能,可以帮助我们缩短开发周期。
Hive是数据分析查询工具,尤其在使用类SQL查询分析时显示是极高的性能。可以在分分钟完成ETL要一晚上才能完成的事情,这就是优势,占了先机!
4. HBase/Sqoop/Flume(数据导入与导出):
HBase是运行在HDFS架构上的列存储数据库,并且已经与Pig/Hive很好地集成。通过Java API可以近无缝地使用HBase。
Sqoop设计的目的是方便从传统数据库导入数据到Hadoop数据集合(HDFS/Hive)。
Flume设计的目的是便捷地从日志文件系统直接把数据导到Hadoop数据集合(HDFS)中。
以上这些数据转移工具都极大的方便了使用的人,提高了工作效率,把经历专注在业务分析上!
5. ZooKeeper/Oozie(系统管理架构):
ZooKeeper是一个系统管理协调架构,用于管理分布式架构的基本配置。它提供了很多接口,使得配置管理任务简单化!
Oozie服务是用于管理工作流。用于调度不同工作流,使得每个工作都有始有终。
这些架构帮助我们轻量化地管理大数据分布式计算架构。
6. Ambari/Whirr(系统部署管理):
Ambari帮助相关人员快捷地部署搭建整个大数据分析架构,并且实时监控系统的运行状况。
Whirr的主要作用是帮助快速的进行云计算开发。
7. Mahout(机器学习):
Mahout旨在帮助我们快速地完成高智商的系统。其中已经实现了部分机器学习的逻辑。这个架构可以让我们快速地集成更多机器学习的智能!!
Hadoop推荐书籍
1. 两本最重要的书籍(这两本基本已经可以满足大部分你对Hadoop的需要):
Hadoop权威指南/Hadoop最佳实践
2. 补充书籍资料:
Hadoop Operations/Professional Hadoop Solutions/Programing Pig/Programing Hive/Data Science for Business
3. 专业论文:
谷歌关于大数据基础的一些重要论文(GFS / MapReduce)
4. 补充Apache网站资料:
hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
pig.apache.org/
spark.apache.org
aws.amazon.com/dynamodb
mahout.apache.org







 京公网安备 11010802041100号
京公网安备 11010802041100号