作者:赵小锅2502889451 | 来源:互联网 | 2023-07-07 13:53
GIL全局解释器锁
‘‘‘
python解释器:
- Cpython C语言
- Jpython java
...
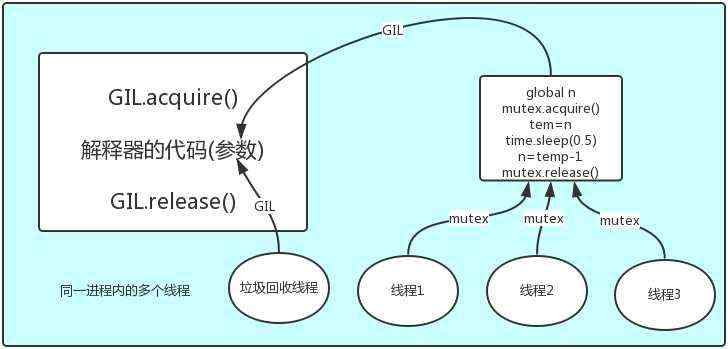
1、GIL: 全局解释器锁
- 翻译: 在同一个进程下开启的多线程,同一时刻只能有一个线程执行,因为Cpython的内存管理不是线程安全。
- GIL全局解释器锁,本质上就是一把互斥锁,保证数据安全。
定义:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
结论:在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。
# 为什么要有全局解释器锁:
- 没有锁:
2、GIL全局解释器锁的优缺点:
1.优点:
保证数据的安全
2.缺点:
单个进程下,开启多个线程,牺牲执行效率,无法实现并行,只能实现并发。
- IO密集型, 多线程
- 计算密集型,多进程
‘‘‘
import time
from threading import Thread
n = 100
def task():
global n
m = n
time.sleep(3) #遇到IO,保存状态+切换,其他线程继续争抢GIL
n = m-1
if __name__ == ‘__main__‘:
list1 = []
for line in range(10):
t = Thread(target=task)
t.start()
list1.append(t)
for t in list1:
t.join()
print(n) # 99
多线程多进程效率比较
单核情况下都用多线程效率高
‘‘‘
IO密集型下使用多线程.
计算密集型下使用多进程.
IO密集型任务,每个任务4s
- 单核:
- 开启线程比进程节省资源。
- 多核:
- 多线程:
- 开启4个子线程: 16s
- 多进程:
- 开启4个进程: 16s + 申请开启资源消耗的时间
计算密集型任务,每个任务4s
- 单核:
- 开启线程比进程节省资源。
- 多核:
- 多线程:
- 开启4个子线程: 16s
- 多进程:
- 开启多个进程: 4s
计算密集型: 多进程
假设100份原材料同时到达工厂,聘请100个人同时制造,效率最高
IO密集型: 多线程
假设100份原材料,只有40份了,其他还在路上,聘请40个人同时制造。
‘‘‘
from threading import Thread
from multiprocessing import Process
import time
# 计算密集型任务
def task1():
# 计算1000000次 += 1
i = 10
for line in range(10000000):
i += 1
# IO密集型任务
def task2():
time.sleep(3)
if __name__ == ‘__main__‘:
# 1、测试多进程:
# 测试计算密集型
# start_time = time.time()
# list1 = []
# for line in range(6):
# p = Process(target=task1)
# p.start()
# list1.append(p)
#
# for p in list1:
# p.join()
# end_time = time.time()
# # 消耗时间: 4.204240560531616
# print(f‘计算密集型消耗时间: {end_time - start_time}‘)
#
# # 测试IO密集型
# start_time = time.time()
# list1 = []
# for line in range(6):
# p = Process(target=task2)
# p.start()
# list1.append(p)
#
# for p in list1:
# p.join()
# end_time = time.time()
# # 消耗时间: 4.382250785827637
# print(f‘IO密集型消耗时间: {end_time - start_time}‘)
# 2、测试多线程:
# 测试计算密集型
start_time = time.time()
list1 = []
for line in range(6):
p = Thread(target=task1)
p.start()
list1.append(p)
for p in list1:
p.join()
end_time = time.time()
# 消耗时间: 5.737328052520752
print(f‘计算密集型消耗时间: {end_time - start_time}‘)
# 测试IO密集型
start_time = time.time()
list1 = []
for line in range(6):
p = Thread(target=task2)
p.start()
list1.append(p)
for p in list1:
p.join()
end_time = time.time()
# 消耗时间: 3.004171848297119
print(f‘IO密集型消耗时间: {end_time - start_time}‘)
协程(理论 + 代码)
1.什么是协程?
- 进程: 资源单位
- 线程: 执行单位
- 协程: 单线程下实现并发
- 在IO密集型的情况下,使用协程能提高最高效率。
注意: 协程不是任何单位,只是一个程序员YY出来的东西。
Nignx
500 ----> 500 ---> 250000 ---> 250000 ----> 10 ----> 2500000
总结: 多进程 ---》 多线程 ---》 让每一个线程都实现协程.(单线程下实现并发)
- 协程的目的:
- 手动实现 "遇到IO切换 + 保存状态" 去欺骗操作系统,让操作系统误以为没有IO操作,将CPU的执行权限给你。
from gevent import monkey # 猴子补丁
monkey.patch_all() # 监听所有的任务是否有IO操作
from gevent import spawn # spawn(任务)
from gevent import joinall
import time
def task1():
print(‘start from task1...‘)
time.sleep(1)
print(‘end from task1...‘)
def task2():
print(‘start from task2...‘)
time.sleep(3)
print(‘end from task2...‘)
def task3():
print(‘start from task3...‘)
time.sleep(5)
print(‘end from task3...‘)
if __name__ == ‘__main__‘:
start_time = time.time()
sp1 = spawn(task1)
sp2 = spawn(task2)
sp3 = spawn(task3)
# sp1.start()
# sp2.start()
# sp3.start()
# sp1.join()
# sp2.join()
# sp3.join()
joinall([sp1, sp2, sp3])
end_time = time.time()
print(f‘消耗时间: {end_time - start_time}‘)









 京公网安备 11010802041100号
京公网安备 11010802041100号