2019独角兽企业重金招聘Python工程师标准>>> 
在这个项目中,我们需要获取的是网页中的图片,所以下一步我们需要从下载好的网页源码中使用正则表达式获取我们需要的图片的网址
照例先贴上一部分网页源码
......
......
......
......
......
......
那么怎么在源码中找到图片所在的位置呢?
1. html 源码中图片的标签是 包裹的代码块
2. 一般网页源码中带下划线的句子是一些网页的链接,而图片是以网页的形式存储的,所以把这些链接点开来试试看
3. 图片有很多格式,比如JPG,JEPG,PNG等,这是图片文件的后缀名,可以用这些关键字搜索
所以,源码中的图片就是的代码块里面的内容,知道这些RE就很好写了
这是我写的RE,可以有很多种写法。加入RE后的源码是这样的 我们开看看输出的结果是什么#!/uer/bin/env python
# -*- coding: UTF-8 -*-
__author__ = '217小月月坑'
'''
加入RE获取网页中的图片的网址
'''import urllib2
import reurl = 'http://product.yesky.com/more/506001_31372_photograph_1.shtml'
user_agent = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:40.0) Gecko/20100101 Firefox/40.0'
headers = {'User-Agent':user_agent}try:request = urllib2.Request(url,headers=headers)response = urllib2.urlopen(request)conents = response.read().decode("gbk")pattern = re.compile(r'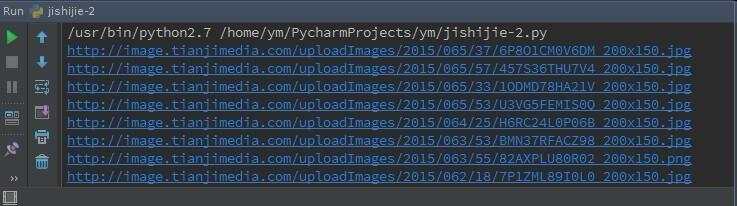
貌似这就是图片的网址了,为了保险起见,我们还是要将网址复制到浏览器看看能不能打开











 京公网安备 11010802041100号
京公网安备 11010802041100号