Python基础学习03
数据类型
数据运算
一、数据类型
1、数字
int(整型):在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1;64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1。
long(长整型):Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
float(浮点型):浮点数用来处理实数,即带有小数的数字。
complex(复数):复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
2、字符串
字符串(str)功能较多。字符串主要特性是:不能修改


1 s="my name is zlz"
2 s1="mY naMe is zlZ"
3 print(s[0:4]) #切片,[0:4]代表将字符串s的前面4位取出来,这里输出 my n
4 print(len(s) ) #获取字符串长度,输出 14w
5 print(s.capitalize()) #将字符串首字母大写,输出 My name is zlz
6 print(s.title()) #将字符串转换成标题,输出 My Name Is Zlz
7 print(s.istitle()) #判断字符串是否为标题,输出 False
8 print(s1.casefold() ) #大写全部变小写,输出 my name is zlz
9 print(s1.lower()) #大写全部变小写,输出 my name is zlz
10 print(s.upper()) #将字符串转换成大写,这里输出MY NAME IS ZLZ
11 print(s.isupper()) #判断字符串是否全部大写,输出 False
12 print(s1.swapcase()) #大写变小写,小写变大写, 输出 My NAmE IS ZLz
13 print(s.center(20,"-") ) #如果输出不足20个字符,用 - 在字符串两侧填充,输出 ---my name is zlz---
14 print(s.ljust(20,"-")) #如果输出不足20个字符,用 - 在字符串右侧填充,输出 my name is zlz------
15 print(s.rjust(20,"-")) #如果输出不足20个字符,用 - 在字符串右侧填充,输出------my name is zlz
16 print(s.count("m") ) #统计 m出现次数,输出 2
17 print(s.startswith("m")) #判断字符串是否以m开头,输出True
18 print(s.endswith("lz") ) #判断字符串是否以 lz结尾,输出True
19 print(s.find("z")) #查找子串第一次在母串中出现的位置,这里输出11,同样可以自己指定位置范围来搜查
20 print(s.rfind("z")) #查找最右侧子串在母串中的位置,这里输出13
21 print(s.index("a")) #返回a所在字符串的索引, 输出 4
22 print(s.isalnum()) #判断字符串是否为数字和字母的组合(纯数字和纯字母都可以,但是不能包含特殊字符), 输出 False
23 print(s.isalpha()) #判断字符串是否为纯字母的组合(可以包含大小写),输出 False
24 print(s.isdecimal()) #判断字符串是否为十进制数字,输出 False
25 print(s.isdigit()) #判断字符串是否为一个整数,输出 False(比较常用)
26 print(s.isidentifier()) #判断字符串是否为一个合法的标识符(变量名),输出 False
27 print(s.islower()) #判断字符串是否为小写,输出 True
28 print(s.isnumeric()) #判断字符串是否为纯数字(类似isdigit),输出 False
29 print(s.isspace()) #判断字符串是否为空格,输出 False
30 print("|".join(['a','b','c'])) #用字符串来连接列表['a','b','c'] 输出 a|b|c(列表转字符串,比较常用)
31 print(s.split()) #分割字符串,返回一个列表 这里输出['my', 'name', 'is', 'zlz'](字符串转列表,比较常用)
32 print(s.strip()) #移除两侧空格换行
33 print(s.lstrip()) #移除左侧空格换行
34 print(s.rstrip()) #移除右侧空格换行
35 print(s.replace('z','Z',1)) #替换,默认全部替换,可以设置为1,只替换一次,这里只替换一次,输出my name is Zlz
36
37 s2 = "my name is {name} , age is {age}"
38 print(s2.format(name = "zlz", age = 22)) #字符串格式化输出,祥见02, 输出 my name is zlz , age is 22
39 #format_map 与format功能相同,只不过传的值为字典,不常用
40
41 #maketrans
42 intab = "aeiou" #原始实际字符.
43 outtab = "12345" #具有对应映射字符的字符串
44 p = s.maketrans(intab, outtab)
45 print(s.translate(p)) #用映射字符替换原有字符,输出 my n1m2 3s zlz
3、列表
列表(list)是常用的数据类型之一,是一种有序的集合,可以随时添加和删除其中的元素。
切片:
1 names = ['Zhangsan',"Lisi",'Wangwu','Zhaoliu','Sunqi'] #定义列表
2
3 #切片:取数据
4
5 print(names[1:3]) #取下标1至下标3之间的数字,包括1,不包括3 输出:['Lisi', 'Wangwu']
6 print(names[1:-1]) #取下标1至-1的值,不包括-1 输出:['Lisi', 'Wangwu', 'Zhaoliu']
7 print(names[0:3]) #取下标0至3的值,不包括3 输出:['Zhangsan', 'Lisi', 'Wangwu']
8 print(names[:3]) #如果是从头开始取,0可以忽略,跟上句效果一样
9 print(names[3:]) #如果想取最后一个,必须不能写-1,只能这么写 输出:['Zhaoliu', 'Sunqi']
10 print(names[3:-1]) #这样-1就不会被包含了 输出:['Zhaoliu']
11 print(names[0::2] ) #后面的2是代表步长,每隔一个元素,就取一个 输出:['Zhangsan', 'Wangwu', 'Sunqi']
12 print(names[::2]) #和上句效果一样
追加:
1 names = ['Zhangsan',"Lisi",'Wangwu','Zhaoliu','Sunqi'] #定义列表
2
3
4 #追加
5
6 names.append("new") #在列表的末尾追加新成员
7 print(names) #输出:['Zhangsan', 'Lisi', 'Wangwu', 'Zhaoliu', 'Sunqi', 'new']
插入:
1 names = ['Zhangsan',"Lisi",'Wangwu','Zhaoliu','Sunqi'] #定义列表
2
3 #插入(每次只能插入一个成员,不能批量)
4
5 names.insert(2,"new") #在指定下标位置前面插入新成员
6 print(names) #输出:['Zhangsan', 'Lisi', 'new', 'Wangwu', 'Zhaoliu', 'Sunqi']
修改:
1 names = ['Zhangsan',"Lisi",'Wangwu','Zhaoliu','Sunqi'] #定义列表
2
3 #修改
4
5 names[2] = "xiugai" #给指定位置成员赋新的值
6 print(names) #输出:['Zhangsan', 'Lisi', 'xiugai', 'Zhaoliu', 'Sunqi']
删除:
1 names = ['Zhangsan',"Lisi",'Wangwu','Zhaoliu','Sunqi'] #定义列表
2
3 #删除
4
5 names.remove("Lisi") #删除指定元素
6 print(names) #输出:['Zhangsan', 'Wangwu', 'Zhaoliu', 'Sunqi']
7 del names[1] #删除指定位置元素
8 print(names) #输出:['Zhangsan', 'Zhaoliu', 'Sunqi']
9 names.pop() #不输入下标的情况下,默认删除列表最后一个值
10 print(names) #输出:['Zhangsan', 'Zhaoliu']
11 names.pop(0) #与del names[0] 作用相同
12 print(names) #输出:['Zhaoliu']
复制:
1 names = ['Zhangsan','Lisi',['A','B'],'Wangwu','Zhaoliu','Sunqi'] #定义列表
2 names2 = names.copy() #复制names
3 print(names2) #输出:['Zhangsan', 'Lisi', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
4 names[1] = "李四" #把names中的Lisi改为:李四
5 print(names) #输出:['Zhangsan', '李四', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
6 print(names2) #输出:['Zhangsan', 'Lisi', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
7 names[2][1] = 'C'
8 print(names) #输出:['Zhangsan', '李四', ['A', 'C'], 'Wangwu', 'Zhaoliu', 'Sunqi']
9 print(names2) #输出:['Zhangsan', 'Lisi', ['A', 'C'], 'Wangwu', 'Zhaoliu', 'Sunqi']
10 #copy为浅copy,只完全copy第一层
11 # names2 = names 则一层也不会copy两者完全一样(与字符串和数字不同)
12
13
14 import copy
15 names = ['Zhangsan','Lisi',['A','B'],'Wangwu','Zhaoliu','Sunqi'] #定义列表
16 names2 = copy.copy(names) #浅copy:names
17 print(names2) #输出:['Zhangsan', 'Lisi', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
18 names[1] = "李四" #把names中的Lisi改为:李四
19 print(names) #输出:['Zhangsan', '李四', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
20 print(names2) #输出:['Zhangsan', 'Lisi', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
21 names[2][1] = 'C'
22 print(names) #输出:['Zhangsan', '李四', ['A', 'C'], 'Wangwu', 'Zhaoliu', 'Sunqi']
23 print(names2) #输出:['Zhangsan', 'Lisi', ['A', 'C'], 'Wangwu', 'Zhaoliu', 'Sunqi']
24 #与上面程序功能相同为浅copy
25
26 names = ['Zhangsan','Lisi',['A','B'],'Wangwu','Zhaoliu','Sunqi'] #定义列表
27 import copy
28 names2 = copy.deepcopy(names) #深copy:names
29 print(names2) #输出:['Zhangsan', 'Lisi', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
30 names[1] = "李四" #把names中的Lisi改为:李四
31 print(names) #输出:['Zhangsan', '李四', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
32 print(names2) #输出:['Zhangsan', 'Lisi', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
33 names[2][1] = 'C'
34 print(names) #输出:['Zhangsan', '李四', ['A', 'C'], 'Wangwu', 'Zhaoliu', 'Sunqi']
35 print(names2) #输出:['Zhangsan', 'Lisi', ['A', 'B'], 'Wangwu', 'Zhaoliu', 'Sunqi']
36 #此为深copy,功能类似于字符串和数字(a = b)
其他操作:
1 names = ['Zhangsan',"Lisi",'Wangwu','Zhaoliu','Sunqi'] #定义列表
2 #获取下标
3 print(names) #输出:['Zhangsan', 'Lisi', 'Wangwu', 'Zhaoliu', 'Sunqi']
4 print(names.index("Lisi")) #获取下标 输出:1
5 #统计重复数量
6 names1 = ['Zhangsan','Lisi','Wangwu','Zhaoliu','Sunqi','Lisi']
7 print(names1.count("Lisi")) #输出:2
8 #反转
9 print(names) #输出:['Zhangsan', 'Lisi', 'Wangwu', 'Zhaoliu', 'Sunqi']
10 names.reverse() #反转
11 print(names) #输出:['Sunqi', 'Zhaoliu', 'Wangwu', 'Lisi', 'Zhangsan']
12 #排序
13 names.sort() #只能排序同一种数据类型,不能多种数据类型同时排
14 print(names) #输出:['Lisi', 'Sunqi', 'Wangwu', 'Zhangsan', 'Zhaoliu']
15 #扩展
16 b = [1,2,3] #定义一个新列表
17 names.extend(b) #把列表b扩展到列表names中
18 print(names) #输出:['Sunqi', 'Zhaoliu', 'Wangwu', 'Lisi', 'Zhangsan', 1, 2, 3]
循环:
1 names = ['Zhangsan','Lisi','Wangwu','Zhaoliu','Sunqi'] #定义列表
2 #循环
3 for i in names:
4 print(i)
5
6 输出:
7 Zhangsan
8 Lisi
9 Wangwu
10 Zhaoliu
11 Sunqi
4、元组
元组(tuple)与列表非常类似,可以理解为只读列表,也是用来存一组数据,元组一旦创建就无法修改
1 names = ('Zhangsan','Lisi','Wangwu','Zhaoliu','Sunqi','Lisi') #定义元组
2
3 print(names.count("Lisi")) #输出:2
4 print(names.index("Zhaoliu")) #输出:3
5
6 #元组不能修改,只有两个方法:count、index
5、字典
字典(dict)是键-值(key-value)数据类型,通过key查找value的值,所以字典的key是唯一的,字典天生去重,并且字典是无序的
增删改查
1 info = {"stu01":"Zhangsan","stu02":"Lisi","stu03":"Wangwu"} #定义字典
2 print(info) #输出:{'stu02': 'Lisi', 'stu03': 'Wangwu', 'stu01': 'Zhangsan'}(字典是无序的)
3 #查找
4 print(info["stu01"]) #查找key对应的值,如果key不存在则会报错 输出:Zhangsan
5 print(info.get("stu01") ) #另一种查找用法
6 print(info.get("stu04")) #输出:None (get的优点在于如果key不存在不会报错,会输出None)
7 print("stu01" in info ) #标准查找:判断key是否存在 输出:True
8 #增加
9 info["stu04"] = "Zhaoliu" #给字典增加元素
10 print(info) #输出:{'stu01': 'Zhangsan', 'stu03': 'Wangwu', 'stu04': 'Zhaoliu', 'stu02': 'Lisi'}
11 #修改
12 info["stu01"] = "张三" #修改字典中key对应元素
13 print(info) #输出:{'stu02': 'Lisi', 'stu01': '张三', 'stu04': 'Zhaoliu', 'stu03': 'Wangwu'}
14 #删除
15 del info["stu01"] #python内置的删除方法
16 print(info) #输出:{'stu02': 'Lisi', 'stu03': 'Wangwu', 'stu04': 'Zhaoliu'}
17 info.pop("stu02") #字典标准删除方法
18 print(info) #输出:{'stu03': 'Wangwu', 'stu04': 'Zhaoliu'}
19 #info.popitem():随机删除,没什么用
字典嵌套
1 #字典嵌套
2 data = {
3 '山东':{
4 '青岛' :['四方','黄岛','崂山','李沧','城阳'],
5 '济南' : ['历城','槐荫','高新','长青','章丘'],
6 '烟台' : ['龙口','莱山','牟平','蓬莱','招远']
7 },
8 '江苏':{
9 '苏州' : ['沧浪','相城','平江','吴中','昆山'],
10 '南京' : ['白下','秦淮','浦口','栖霞','江宁'],
11 '无锡' : ['崇安','南长','北塘','锡山','江阴']
12 },
13 '浙江' : {
14 '杭州' : ['西湖','江干','下城','上城','滨江'],
15 '宁波' : ['海曙','江东','江北','镇海','余姚'],
16 '温州' : ['鹿城','龙湾','乐清','瑞安','永嘉']
17 },
18 }
19 print(data["山东"]["青岛"]) #输出:['四方', '黄岛', '崂山', '李沧', '城阳']
20 data["山东"]["青岛"][0] = "修改值" #修改指定元素
21 print(data["山东"]["青岛"]) #输出:['修改值', '黄岛', '崂山', '李沧', '城阳']
其他方法
1 info = {"stu01":"Zhangsan","stu02":"Lisi","stu03":"Wangwu"} #定义字典
2 print(info.values()) #输出:dict_values(['Zhangsan', 'Wangwu', 'Lisi'])
3 #打印字典中的所有值:不包含key
4 print(info.keys()) #输出:dict_keys(['stu01', 'stu02', 'stu03'])
5 #打印字典中的所有的key
6 info.setdefault("stu04","Zhaoliu") #给字典增加一个元素
7 print(info)
8 #这个添加元素与info["stu04"] = "Zhaoliu" 不同。如果存在stu04这个key,setdefault方法不会覆盖原值,而info["stu04"]则会覆盖原来的值
9
10 z = {"stu01":"张三","aa":"bb","cc":"dd"}
11 info.update(z) #合并两个字典,并update原有字典数据,
12 print(info) #输出:{'stu02': 'Lisi', 'stu04': 'Zhaoliu', 'cc': 'dd', 'stu03': 'Wangwu', 'stu01': '张三', 'aa': 'bb'}
13
14 print(info.items()) #字典转列表
15 #输出:dict_items([('stu04', 'Zhaoliu'), ('stu01', '张三'), ('stu03', 'Wangwu'), ('stu02', 'Lisi'), ('aa', 'bb'), ('cc', 'dd')])
16
17 info = {"stu01":"Zhangsan","stu02":"Lisi","stu03":"Wangwu"}
18 #循环
19 for i in info:
20 print(i) #打印字典的key, 输出:stu01、stu03、stu02
21 for i in info:
22 print(i,info[i])
23 #输出:
24 '''
25 stu01 Zhangsan
26 stu03 Wangwu
27 stu02 Lisi
28 '''
29 for k,v in info.items(): #会先把dict转成list,数据里大时莫用
30 print(k,v) #输出与上面相同
6、集合
集合是无序的不重复的数据组合,主要作用:去重、关系测试
1 list = [1,1,2,2,3,4,5,6,6] #定义一个有重复数据的列表
2 list_1 = set(list) #将列表转换成集合(集合自动去重)
3 print(list_1,type(list_1)) #输出:{1, 2, 3, 4, 5, 6}
4
5 list_2 = set([3,4,5,6,7,8,9]) #定义一个集合
6
7 #交集:返回一个新的 set 包含list_1与list_2中的公共元素
8 a = list_1.intersection(list_2) #取list_1与list_2的交集
9 print(a,type(a)) #输出:{3, 4, 5, 6}
10 b = list_1 & list_2 #取交集简写
11 print(b) #输出:{3, 4, 5, 6}
12 #并集:返回一个新的 set 包含 list_1和 list_2 中的每一个元素
13 c = list_1.union(list_2) #取list_1与list_2的并集
14 print(c) #输出:{1, 2, 3, 4, 5, 6, 7, 8, 9}
15 d = list_1 | list_2 #取并集简写
16 print(d) #输出:{1, 2, 3, 4, 5, 6, 7, 8, 9}
17 #差集:返回一个新的 set 包含 list_1 中有但是 list_2 中没有的元素
18 e = list_1.difference(list_2) #取list_1相对于list_2 的差集(在1中有2中没有)
19 print(e) #输出:{1, 2}
20 f = list_2 - list_1 #取差集简写
21 print(f) #输出:{8, 9, 7}
22 #对称差集:返回一个新的 set 包含 list_1和 list_2 中不重复的元素
23 g = list_1.symmetric_difference(list_2) #取list_1与list_2的对称差集
24 print(g) #输出:{1, 2, 7, 8, 9}
25 h = list_1 ^ list_2 #对称差集简写
26 print(h) #输出:{1, 2, 7, 8, 9}
27 #子集: 判断list_1 中的每一个元素都在 list_2 中
28 i = list_1.issubset(list_2) #判断list_1是否是list_2的子集
29 print(i) #输出:False
30 j &#61; list_1 <&#61; list_2 #判断子集简写
31 print(j) #输出&#xff1a;False
32
33 #对集合的操作
34 print(list_1) #输出&#xff1a;{1, 2, 3, 4, 5, 6}
35 list_1.add(10) #为集合添加元素
36 print(list_1) #输出&#xff1a;{1, 2, 3, 4, 5, 6, 10}
37 list_1.update([20,30]) #为集合添加多个元素
38 print(list_1) #输出&#xff1a;{1, 2, 3, 4, 5, 6, 10, 20, 30}
39 list_1.remove(20) #为集合删除元素
40 print(list_1) #输出&#xff1a;{1, 2, 3, 4, 5, 6, 10, 30}
41 i &#61; 3 in list_1 #判断一个元素是否在集合中
42 print(i) #输出&#xff1a;True
43 j &#61; 3 not in list_1 #判断一个元素是否不在在集合中
44 print(j) #输出&#xff1a;False
1、算数运算
变量a &#61; 10 b &#61; 20
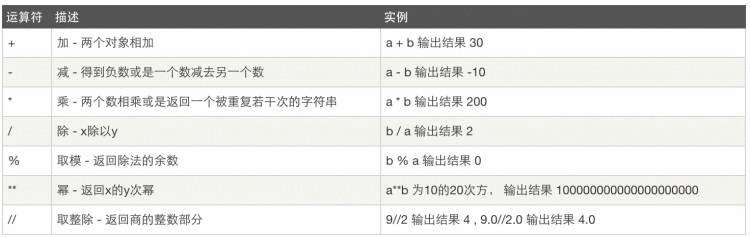
2、比较运算
变量a &#61; 10 b &#61; 20
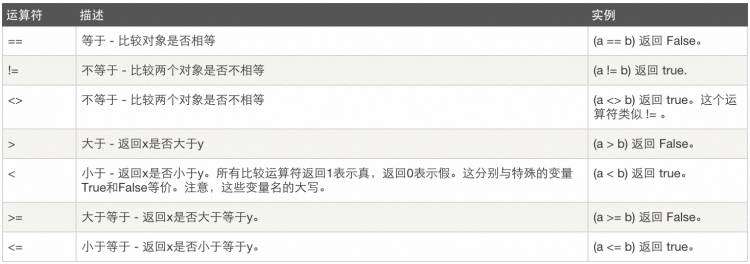
3、赋值运算
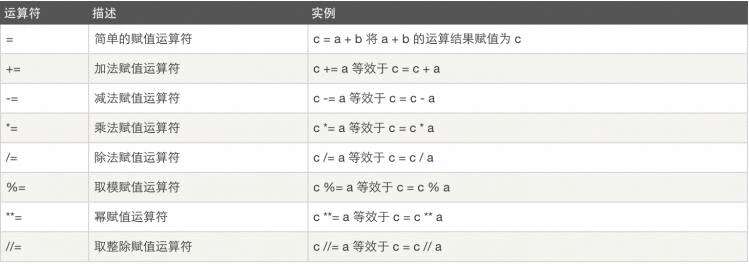
4、逻辑运算
变量a &#61; true b &#61; true

5、成员运算

6、身份运算
身份运算符用于比较两个对象的存储单元

7、位运算
按位运算符是把数字看作二进制来进行计算的
a &#61; 60 b &#61; 13
a &#61; 0011 1100
b &#61; 0000 1101
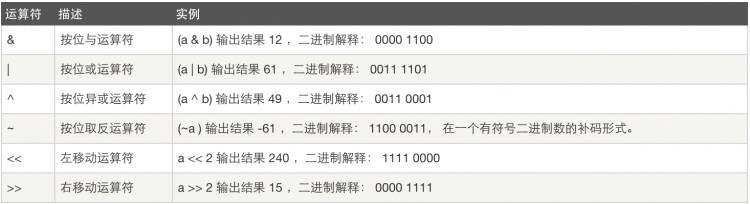
按位取反运算规则(按位取反再加1)
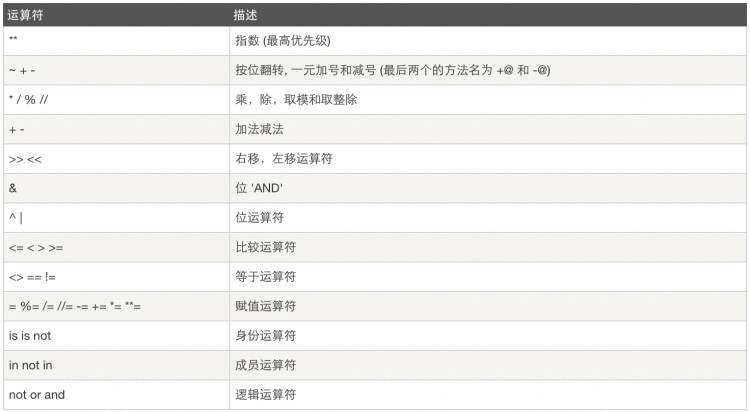
8、运算符优先级



![扫描线三巨头 hdu1928hdu 1255 hdu 1542 [POJ 1151]](https://img.php1.cn/3c972/245b5/42f/19446f78530d3747.jpeg)


 京公网安备 11010802041100号
京公网安备 11010802041100号