1 LTP 简介
LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。从应用角度来看,LTP为用户提供了下列组件:
针对单一自然语言处理任务,生成统计机器学习模型的工具
针对单一自然语言处理任务,调用模型进行分析的编程接口
使用流水线方式将各个分析工具结合起来,形成一套统一的中文自然语言处理系统
系统可调用的,用于中文语言处理的模型文件
针对单一自然语言处理任务,基于云端的编程接口
官网在这:http://ltp.ai/
2 pyltp 简介
pyltp 是 LTP 的 Python 封装,提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。
github网址:https://github.com/HIT-SCIR/pyltp
在线文档:https://pyltp.readthedocs.io/zh_CN/latest/api.html
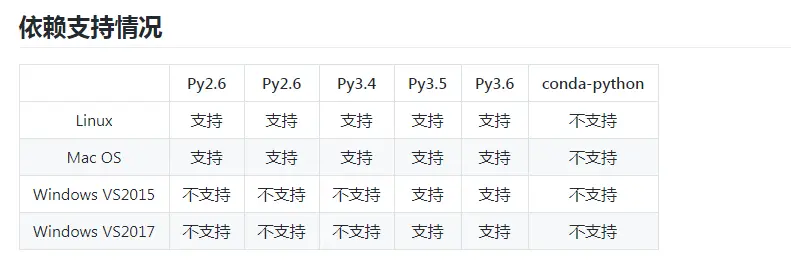
3 pyltp 安装步骤
-
第一步,安装 pyltp
使用 pip 安装
$ pip install pyltp
或从源代码安装
$ git clone https://github.com/HIT-SCIR/pyltp$ git submodule init$ git submodule update$ python setup.py install # Mac系统出现版本问题使用 MACOSX_DEPLOYMENT_TARGET=10.7 python setup.py install
-
第二步,下载模型文件
七牛云,当前模型版本 3.4.0,(下面代码里会介绍如何使用模型)
百度云,这里有各个版本的
我最开始在自己电脑(windows)上安装不上,主要有以下错误:
- vc++ 14 找不到:到这里下载 Visual C++ 2015 Build Tools 安装重启电脑即可
- 安装的过程提示 winerror32:文件找不到:
安装wheel 下面两个文件针对不同的python版本下载一个即可
pyltp-0.2.1-cp35-cp35m-win_amd64.whl
pyltp-0.2.1-cp36-cp36m-win_amd64.whl
https://download.csdn.net/download/qq_22521211/10460778 可下载
4 基本组件使用
4.1 分句
from pyltp import SentenceSplitter
sents = SentenceSplitter.split('元芳你怎么看?我就趴窗口上看呗!') # 分句
print('\n'.join(sents))
输出:
元芳你怎么看?
我就趴窗口上看呗!
4.2 分词
import os
from pyltp import Segmentor
LTP_DATA_DIR='D:\Data\ltp_data_v3.4.0'
cws_model_path=os.path.join(LTP_DATA_DIR,'cws.model')
segmentor=Segmentor()
segmentor.load(cws_model_path)
words=segmentor.segment('熊高雄你吃饭了吗')
print(type(words))
print('\t'.join(words))
segmentor.release()
输出
熊高雄 你 吃饭 了 吗
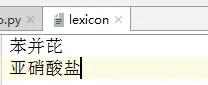
4.3 使用自定义词典
lexicon文件如下:
import os
LTP_DATA_DIR='D:\Data\ltp_data_v3.4.0' # ltp模型目录的路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径,模型名称为`cws.model`from pyltp import Segmentor
segmentor = Segmentor() # 初始化实例
segmentor.load_with_lexicon(cws_model_path, 'lexicon') # 加载模型,第二个参数是您的外部词典文件路径
words = segmentor.segment('亚硝酸盐是一种化学物质')
print('\t'.join(words))
segmentor.release()
输出
[INFO] 2018-08-16 19:18:03 loaded 2 lexicon entries
亚硝酸盐 是 一 种 化学 物质
4.4 词性标注
import os
LTP_DATA_DIR='D:\Data\ltp_data_v3.4.0'
# ltp模型目录的路径
pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model') # 词性标注模型路径,模型名称为`pos.model`from pyltp import Postagger
postagger = Postagger() # 初始化实例
postagger.load(pos_model_path) # 加载模型words = ['元芳', '你', '怎么', '看'] # 分词结果
postags = postagger.postag(words) # 词性标注print('\t'.join(postags))
postagger.release() # 释放模型
输出如下
nh r r v
4.5 命名实体识别
import os
LTP_DATA_DIR='D:\Data\ltp_data_v3.4.0' # ltp模型目录的路径
ner_model_path = os.path.join(LTP_DATA_DIR, 'ner.model') # 命名实体识别模型路径,模型名称为`pos.model`from pyltp import NamedEntityRecognizer
recognizer = NamedEntityRecognizer() # 初始化实例
recognizer.load(ner_model_path) # 加载模型words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
netags = recognizer.recognize(words, postags) # 命名实体识别print('\t'.join(netags))
recognizer.release() # 释放模型
输出
S-Nh O O O
4.6 依存句法分析
import os
LTP_DATA_DIR='D:\Data\ltp_data_v3.4.0' # ltp模型目录的路径
par_model_path = os.path.join(LTP_DATA_DIR, 'parser.model') # 依存句法分析模型路径,模型名称为`parser.model`from pyltp import Parser
parser = Parser() # 初始化实例
parser.load(par_model_path) # 加载模型words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
arcs = parser.parse(words, postags) # 句法分析print("\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs))
parser.release() # 释放模型
输出为:
4:SBV 4:SBV 4:ADV 0:HED
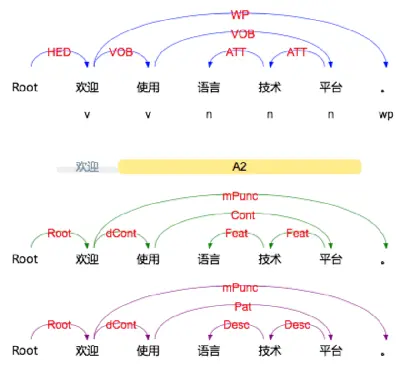
标注集请参考 依存句法关系 。
4.7 语义角色标注
import os
LTP_DATA_DIR='D:\Data\ltp_data_v3.4.0' # ltp模型目录的路径
srl_model_path = os.path.join(LTP_DATA_DIR, 'pisrl_win.model') # 语义角色标注模型目录路径,模型目录为`srl`。注意该模型路径是一个目录,而不是一个文件。from pyltp import SementicRoleLabeller
labeller = SementicRoleLabeller() # 初始化实例
labeller.load(srl_model_path) # 加载模型words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
# arcs 使用依存句法分析的结果
roles = labeller.label(words, postags, arcs) # 语义角色标注# 打印结果
for role in roles:print(role.index, "".join(["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))
labeller.release() # 释放模
输出为:
[dynet] random seed: 1676210130
[dynet] allocating memory: 2000MB
[dynet] memory allocation done.
3 A0:(1,1)ADV:(2,2)
例如上面的例子,由于结果输出一行,所以“元芳你怎么看”有一组语义角色。 其谓词索引为3,即“看”。这个谓词有三个语义角色,范围分别是(0,0)即“元芳”,(1,1)即“你”,(2,2)即“怎么”,类型分别是A0、A0、ADV。
标注集请参考 语义角色关系 。











 京公网安备 11010802041100号
京公网安备 11010802041100号