介绍公式
最起初GAN的代价函数:
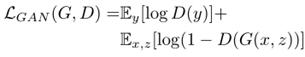
引入Conditional GAN的代价函数:
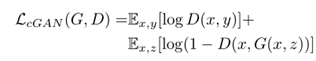
受到前人工作启发,在这基础上又加入了人L1代价函数:
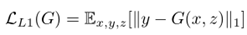
所以最终的目标函数就是:
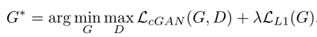
为什么是conditional gan呢:
pix2pix对传统的GAN做了个小改动,它不再输入随机噪声,而是输入用户给的图片
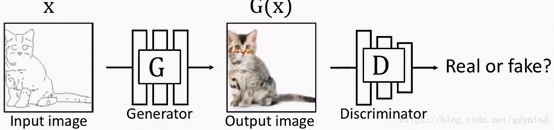
但这也就产生了新的问题:我们怎样建立输入和输出的对应关系。此时G的输出如果是下面这样,D会判断是真图:
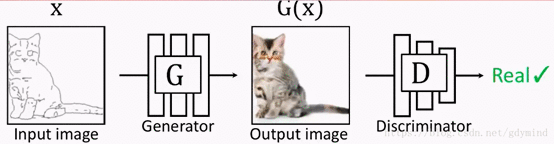
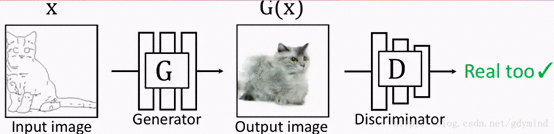
但如果G的输出是下面这样的,D拿来一看,也会认为是真的图片,也就是说,这样做并不能训练出输入和输出对应的网络G,因为是否对应根本不影响D的判断。
为了体现这种对应关系,解决方案也很简单,我们把G的输入和输出一起作为D的输入,于是现在的优化目标变成了这样:

为何使用L1范数而不是L2和L0范数:
L0范数本身是特征选择的最直接最理想的方案,其表示向量中所有非零元素的个数。正是L0范数的这个属性,使得其非常适合机器学习中稀疏编码,特征选择的应用。通过最小化L0范数,来寻找最少最优的稀疏特征项。但不幸的是,L0范数的最小化问题在实际应用中是NP难问题。因此实际应用中我们使用L1来得到L0的最优凸近似。L2相对于L1具有更为平滑的特性,在模型预测中,往往比L1具有更好的预测特性。当遇到两个对预测有帮助的特征时,L1倾向于选择一个更大的特征。而L2更倾向把两者结合起来。
稀疏编码起初是生物学家提出的,大致意思是我们看一个东西,这个画面是有上亿个像素的,但是每一副图像我们都只用很少的代价重建与存储,这就叫稀疏编码,即space coding。可以用0-1变量的思想理解,假设我们看这幅图像需要这个像素点,那这个像素的系数就为1,不需要就是0。L1和L0范数都可以实现,但是L2范数是不允许为0的,L2范数顶多说是趋于0。所以稀疏编码只有L0和L1可以。
L2范数通常是解决过拟合(overfitting,也称High variance)问题的。
文中的解释是:Using L1 distance rather than L2 as L1 encourages less blurring.
综合刚刚的介绍,我们可以知道,L2由于每一个都不会让他等于0,他把所有像素都糅合起来,而L0,L1就很干脆。
(这也是我自己的理解,如果有问题,还希望能告诉我)
Network architectures网络体系结构
1、Generator with skips
对于图像-图像问题传统生成器的网络结构Encoder-Decoder就是将输入的图像一步步下采样直到最底层(bottleneck layer)这层之后就会翻转,进行上采样,如左图左侧。但输入输出的图像有着很多的共享信息,比如说,输入一个轮廓图,输出着色图,这两张图片的轮廓就是共享的。我们应该用一个信息传输通道直接传输,而不是一层一层传输。于是就有了U-Net网络。为何这是“Generator with skips”,是因为直接跳过了底层。
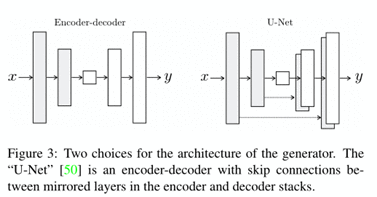
2、Markovian discriminator (PatchGAN)
对于低频,L1可以处理很好,但是高频很模糊。因为只对高频建模,所以我们只要对于局部结构就行了,所以引入了一种鉴别器结构PatchGAN, PatchGAN和普通GAN判别器是有区别的,普通的GAN判别器是将输入映射成一个实数,即输入样本为真样本的概率.PatchGAN将输入映射为NxN的patch(矩阵)X,Xij的值代表每个patch为真样本的概率,将Xij求均值,即为判别器最终输出,X其实就是卷积层输出的特征图.从这个特征图可以追溯到原始图像中的某一个位置,可以看出这个位置对最终输出结果的影响.
评价标准
传统做法
每个像素的均方差MSE
本文做法
1、Amazon Mechanical Turk(AMT)
真人测试打分
2、FCN-score
(为此,我们采用流行的FCN-8s架构进行语义分割,并在cityscapes数据集上对其进行训练。然后,我们根据这些照片合成的标签进行分类准确性评分。)
介绍FCN:像素级别的分类,解决语义分割问题,他和CNN不同,CNN处理的图片的分类,他输入的是一个固定长度的特征向量,每一个值就表示属于哪一类图片的概率。FCN是不固定长度的,他从最底层的卷积层反卷积上采样,直到最后的图像和与原图尺寸相同为止。所以每个像素都产生了预测,最后在这个特征图上进行像素分类即可。
最终程序会输出相应的像素准确度、平均准确度、mean IU(均交并比)和频率加权交并比(frequency weighted IU)四个指标
(https://blog.csdn.net/lingzhou33/article/details/87901365对这几个指标的解释)
优点
pix2pix巧妙的利用了GAN的框架来为“Image-to-Image translation”的一类问题提供了通用框架。利用U-Net提升细节,并且利用PatchGAN来处理图像的高频部分。
缺点
训练需要大量的成对图片,比如白天转黑夜,则需要大量的同一个地方的白天和黑夜的照片。
pix2pix在线demo https://affinelayer.com/pixsrv/
以上是个人浅见,如有错误,还希望大家能够指出,谢谢大家。


![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)





 京公网安备 11010802041100号
京公网安备 11010802041100号