作者:英雄泪 | 来源:互联网 | 2018-07-17 18:01
聊一聊Python与网络爬虫。
1、爬虫的定义
爬虫:自动抓取互联网数据的程序。
2、爬虫的主要框架
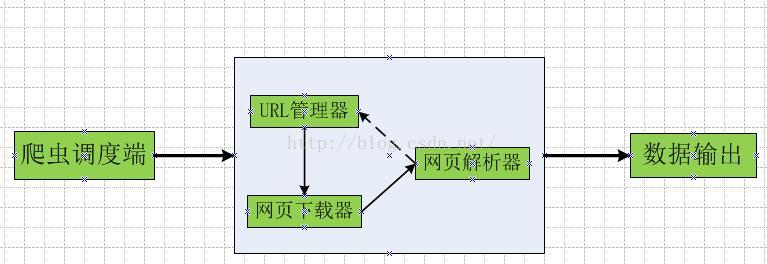
爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出。
3、爬虫的时序图
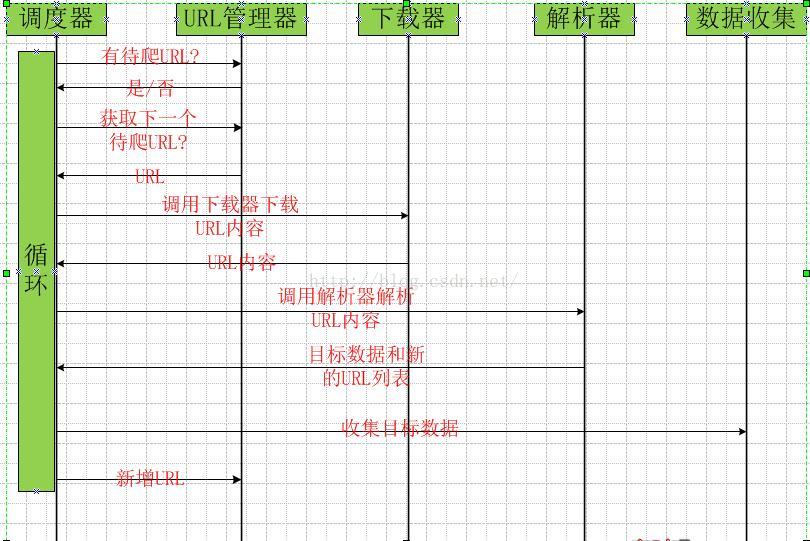
4、URL管理器
URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取。URL管理器的主要职能如下图所示:

URL管理器在实现方式上,Python中主要采用内存(set)、和关系数据库(MySQL)。对于小型程序,一般在内存中实现,Python内置的set()类型能够自动判断元素是否重复。对于大一点的程序,一般使用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用urllib库,这是python自带的模块。对于2.x版本中的urllib2库,在python3.x中集成到urllib中,在其request等子模块中。urllib中的urlopen函数用于打开url,并获取url数据。urlopen函数的参数可以是url链接,也可以使request对象,对于简单的网页,直接使用url字符串做参数就已足够,但对于复杂的网页,设有防爬虫机制的网页,再使用urlopen函数时,需要添加http header。对于带有登录机制的网页,需要设置COOKIE。
6、网页解析器
网页解析器从网页下载器下载到的url数据中提取有价值的数据和新的url。对于数据的提取,可以使用正则表达式和BeautifulSoup等方法。正则表达式使用基于字符串的模糊匹配,对于特点比较鲜明的目标数据具有较好的作用,但通用性不高。BeautifulSoup是第三方模块,用于结构化解析url内容。将下载到的网页内容解析为DOM树,下图为使用BeautifulSoup打印抓取到的百度百科中某网页的输出的一部分。

关于BeautifulSoup的具体使用,在以后的文章中再写。下面的代码使用python抓取百度百科中英雄联盟词条中的其他与英雄联盟相关的词条,并将这些词条保存在新建的excel中。上代码:
from bs4 import BeautifulSoup
import re
import xlrd
import xlwt
from urllib.request import urlopen
excelFile=xlwt.Workbook()
sheet=excelFile.add_sheet('league of legend')
## 百度百科:英雄联盟##
html=urlopen("http://baike.baidu.com/subview/3049782/11262116.htm")
bsObj=BeautifulSoup(html.read(),"html.parser")
#print(bsObj.prettify())
row=0
for node in bsObj.find("p",{"class":"main-content"}).findAll("p",{"class":"para"}):
links=node.findAll("a",href=re.compile("^(/view/)[0-9]+\.htm$"))
for link in links:
if 'href' in link.attrs:
print(link.attrs['href'],link.get_text())
sheet.write(row,0,link.attrs['href'])
sheet.write(row,1,link.get_text())
row=row+1
excelFile.save('E:\Project\Python\lol.xls')
输出的部分截图如下:

excel部分的截图如下:

以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。








 京公网安备 11010802041100号
京公网安备 11010802041100号