前几天有学员问了个问题,如图所示,求合格率,要求是表格不能有任何的改动,只能用公式实现。
我的第一反应是:这个表中的文本幸好是非常有规律和规范的,用函数就可以轻松实现。当然,如果学员再学点VB的知识,那这个就非常容易实现了。
作为基础课程,我们还是再熟悉一下函数,看看我们通过公式如何来解决这种有规律的文本问题。
分析很明显,计算合格率,我们必须将数字从文本中提取出来,我们可以看到出现的第一个数字是在“查”字之后,第一个“处”字之前,所以这第一组数据的提取可以这样做:
第一:数字是从第3位开始的,我们提取的时候从第3位进行提取;
第二:“处”之前就是数字的最后一位了,所以我们只需要去掉处所在的位置,那么留下的就是整个要提取的数字部分了;
第一组数据提取通过上面的分析,我们提取的话,肯定会用到MID这个函数,也就是从什么地方开始,到什么地方结束,提取中间的内容。
我们来把公式拆解进行理解:
=MID(文本内容,开始位置,留下几个文本)
文本内容:抽查500处,合格114处
开始位置:3
留下文本数量:3
很显然,难点是这个留下的文本数量,因为是500的时候,你要留下3个文本,那一位数或两位数的时候,你需要留下的就是一个或两个文本了,这个数量就是变化的,所以我们要以不变应万变。我们这里只能通过“处”的位置来确定。
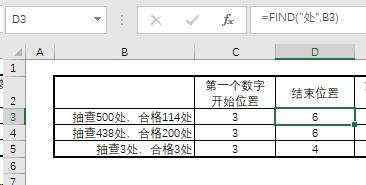
还记得上一节给大家讲过的Find函数吧。我们通过Find函数看看“处”字在什么位置就好了。所以公式是:
=Find(“处”,文本内容所在单元格),即如下图所示:
把这结束位置减去这个起始位置,得到的不就是中间文本的长度么?而且开始位置固定就是从3开始。所以公式的整合就是:
将公式套入进去应该是:
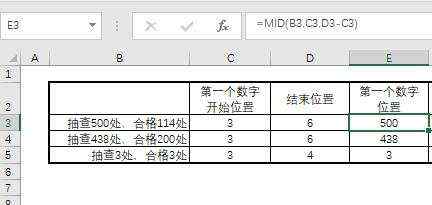
=MID(B3,3,FIND(“处”,B3)-3)
是不是非常容易就得出了我们要求合格率的分母。
第二组数据的提取按照上面的逻辑,我们的开始位置可以是从“格”字开始,留取直到倒数第二位的文本长度就可以了。
所以根据上述的分析,我们找第二组数据的开始位置。
找到“格”字之后再往后增加一位就是了,所以公式是:
=FIND(“格”,B3)+1
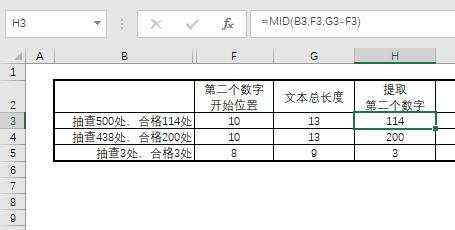
结果是10,同样根据前面的逻辑,我们看到最后的一个“处”字只占据一个字符,那么我们可以根据文本的总长度来进行计算。这里LEN函数就是计算文本总长度的。
即:=LEN(B3)
文本总长度是:13
我们最终要留下的长度是3位,所以直接是13-10就可以了。如图所示:
所以把所有的公式套入其中,就应该是:
=MID(B3,(FIND("格",B3)+1),LEN(B3)-(FIND("格",B3)+1)
这样也就轻松了获取了我们要的分子。
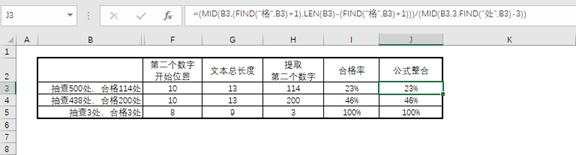
最终结果上述提取了这两组数据,计算合格率就非常简单了。直接套入就好了:
=(MID(B3,(FIND("格",B3)+1),LEN(B3)-(FIND("格",B3)+1)))/(MID(B3,3,FIND("处",B3)-3))
如图:
大功告成!
=========================
所以当你遇到一个问题需要解决的时候,尤其是需要公式进行套用或嵌套的时候,没必要一把到位,先分解后再合并也是写正确公式的一种做法,而且自己还能从中找到分析解决问题的方法。
如果你有其他更多的方法,欢迎留言一起交流学习。






 京公网安备 11010802041100号
京公网安备 11010802041100号