如何处理时间序列数据?
import pandas as pd
import matplotlib.pyplot as plt
air_quality = pd.read_csv("data/air_quality_no2_long.csv")
air_quality = air_quality.rename(columns={"date.utc": "datetime"})
air_quality.head()
| city | country | datetime | location | parameter | value | unit |
|---|
| 0 | Paris | FR | 2019-06-21 00:00:00+00:00 | FR04014 | no2 | 20.0 | µg/m³ |
|---|
| 1 | Paris | FR | 2019-06-20 23:00:00+00:00 | FR04014 | no2 | 21.8 | µg/m³ |
|---|
| 2 | Paris | FR | 2019-06-20 22:00:00+00:00 | FR04014 | no2 | 26.5 | µg/m³ |
|---|
| 3 | Paris | FR | 2019-06-20 21:00:00+00:00 | FR04014 | no2 | 24.9 | µg/m³ |
|---|
| 4 | Paris | FR | 2019-06-20 20:00:00+00:00 | FR04014 | no2 | 21.4 | µg/m³ |
|---|
air_quality.city.unique()
array(['Paris', 'Antwerpen', 'London'], dtype=object)
使用pandas的datetime类型
1、我想把datetime列从文本转换成datetime类型
air_quality["datetime"] = pd.to_datetime(air_quality["datetime"])
air_quality["datetime"]
0 2019-06-21 00:00:00+00:00
1 2019-06-20 23:00:00+00:00
2 2019-06-20 22:00:00+00:00
3 2019-06-20 21:00:00+00:00
4 2019-06-20 20:00:00+00:00
...
3442 2019-04-09 06:00:00+00:00
3443 2019-04-09 05:00:00+00:00
3444 2019-04-09 04:00:00+00:00
3445 2019-04-09 03:00:00+00:00
3446 2019-04-09 02:00:00+00:00
Name: datetime, Length: 3447, dtype: datetime64[ns, UTC]
datetime列的初始值是字符串,不支持任何datetime操作(例如,提取年份、星期等等)。通过应用to_datetime函数,pandas将解析字符串并将其转换为datetime(例如datetime64[ns, UTC])对象。在pandas中,我们称其datetime类型(由panda.Timestamp对象定义),它类似于python标准库中的datetime.datetime对象。
由于很多数据集将日期时间信息包含在其中一列中,因此pandas输入函数,例如.read_csv()在读取数据时,可以使用parse_dates参数将列的列表作为Timestamp对象读取到日期列。Timestamp对象非常有用,它有很多有用的特性。
1.1、时间序列数据中的起始和终止日期
air_quality["datetime"].min(), air_quality["datetime"].max()
(Timestamp('2019-04-09 01:00:00+0000', tz='UTC'),
Timestamp('2019-06-21 00:00:00+0000', tz='UTC'))
1.2、时间序列的时间长度是多少
air_quality["datetime"].max() - air_quality["datetime"].min()
Timedelta('72 days 23:00:00')
由Timestamp定义的时间可以轻地计算时间信息,如上面得到了两个时间点的时间间隔,这是个Timedelta对象,类型于Python标准库中的datetime.timedelta。
2、我想在原数据中添加一列,让它包含观测值的月份
air_quality["month"] = air_quality["datetime"].dt.month
air_quality.head()
| city | country | datetime | location | parameter | value | unit | month |
|---|
| 0 | Paris | FR | 2019-06-21 00:00:00+00:00 | FR04014 | no2 | 20.0 | µg/m³ | 6 |
|---|
| 1 | Paris | FR | 2019-06-20 23:00:00+00:00 | FR04014 | no2 | 21.8 | µg/m³ | 6 |
|---|
| 2 | Paris | FR | 2019-06-20 22:00:00+00:00 | FR04014 | no2 | 26.5 | µg/m³ | 6 |
|---|
| 3 | Paris | FR | 2019-06-20 21:00:00+00:00 | FR04014 | no2 | 24.9 | µg/m³ | 6 |
|---|
| 4 | Paris | FR | 2019-06-20 20:00:00+00:00 | FR04014 | no2 | 21.4 | µg/m³ | 6 |
|---|
使用Timestamp对象,可以方便获得许多时间相关属性(年、月、季度)等信息,要访问这些属性,需要使用dt访问器。
3、每个观测站的一周内各天的平均浓度是多少?
air_quality.groupby(
[air_quality["datetime"].dt.weekday, "location"])["value"].mean()
datetime location
0 BETR801 32.489583
FR04014 29.495417
London Westminster 29.425439
1 BETR801 30.083333
FR04014 34.402381
London Westminster 35.185345
2 BETR801 21.533333
FR04014 30.130579
London Westminster 30.121212
3 BETR801 24.615385
FR04014 28.749378
London Westminster 29.378723
4 BETR801 24.541667
FR04014 32.980851
London Westminster 30.192308
5 BETR801 28.500000
FR04014 24.955752
London Westminster 26.995434
6 BETR801 20.514286
FR04014 24.467917
London Westminster 26.685590
Name: value, dtype: float64
还记得groupby中提供的分组(split)-应用(apply)-组合(combine)模式吗?这里,我们要计算一周各天和每个观测站的给定统计量(例如,平均浓度浓度)。为了对星期各天分组,我们使用pandas Timestamp的weekday属性(Monday=0和Sunday=6),使用dt访问器可以访问该属性。之后就对地点与日期进行分组,并计算各组平均值。
4、绘制所有站点一日内各时段的典型的浓度分布形式。换句话说,一天中每小时的平均值是多少?
fig, axs = plt.subplots(figsize=(12, 4))
air_quality.groupby(
air_quality["datetime"].dt.hour)["value"].mean().plot(kind='bar',
rot=0,
ax=axs)
plt.xlabel("Hour of the day")
plt.ylabel("$NO_2 (µg/m^3)$");
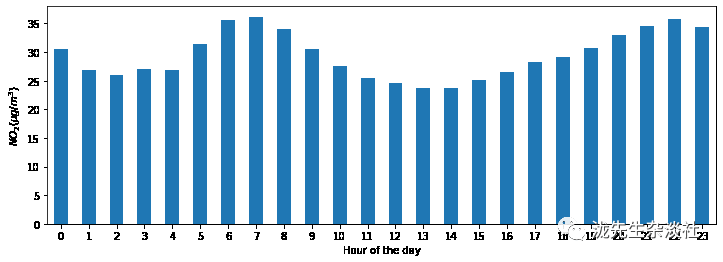
和上面的情况类似,我们希望计算一天中每小时的给定统计数据(例如平均浓度),我们可以再次使用分组(split)-应用(apply)-组合(combine)方法。对于这个例子,使用dt访问器获得hour属性。
将datetime作为index使用
使用在改变图形布局教程中介绍pivot()函数将数据变换成如下方式:
no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
no_2.head()
| location | BETR801 | FR04014 | London Westminster |
|---|
| datetime | | | |
|---|
| 2019-04-09 01:00:00+00:00 | 22.5 | 24.4 | NaN |
|---|
| 2019-04-09 02:00:00+00:00 | 53.5 | 27.4 | 67.0 |
|---|
| 2019-04-09 03:00:00+00:00 | 54.5 | 34.2 | 67.0 |
|---|
| 2019-04-09 04:00:00+00:00 | 34.5 | 48.5 | 41.0 |
|---|
| 2019-04-09 05:00:00+00:00 | 46.5 | 59.5 | 41.0 |
|---|
datetime索引(即DatetimeIndex)提供了强大的功能。例如,我们无需dt访问器,直接在索引上就可访问这些属性:
no_2.index.year, no_2.index.weekday
(Int64Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
...
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
dtype='int64', name='datetime', length=1705),
Int64Index([1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
3, 3, 3, 3, 3, 3, 3, 3, 3, 4],
dtype='int64', name='datetime', length=1705))
datetime还有其他一些优点,比如可以方便地划分时间段或调整时间尺度。
5、绘制5月20日和5月21日各站NO2浓度图
no_2["2019-05-20":"2019-05-21"].plot()
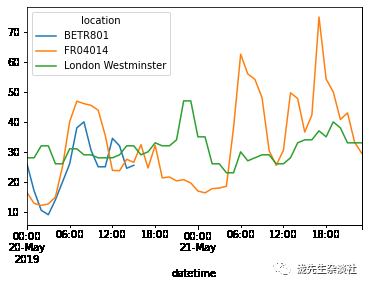
datetimeIndex可以解析字符串日期,因此能够方便的划分不同时间断的子集。
将一种时间序列重采样(resample)成另一频率的数据。
6、将当前以小时为单位的时间序列变换成以月为单位,并取其中最大值。
monthly_max = no_2.resample("M").max()
monthly_max
| location | BETR801 | FR04014 | London Westminster |
|---|
| datetime | | | |
|---|
| 2019-04-30 00:00:00+00:00 | 72.5 | 117.2 | 84.0 |
|---|
| 2019-05-31 00:00:00+00:00 | 74.5 | 97.0 | 97.0 |
|---|
| 2019-06-30 00:00:00+00:00 | 52.5 | 84.7 | 52.0 |
|---|
datetime索引的时间序列数据有一种非常强大的方法resample(),可以将时间序列重采样到另一个频率(例如,将每两天数据转换为5分钟数据)。
resample()方法和groupby操作很像:
- 它通过使用字符串(例如M,5H,…)来定义目标频率,并基于此对时间分组
- 它需要一个汇总函数,比如mean,max,...
当通过上述方法定义了时间频率后,就可以通过freq属性查看时间序列频率:
monthly_max.index.freq
7、绘制每个观测站的每日NO2浓度中值:
no_2.resample("D").mean().plot(style="-o", figsize=(10, 5));
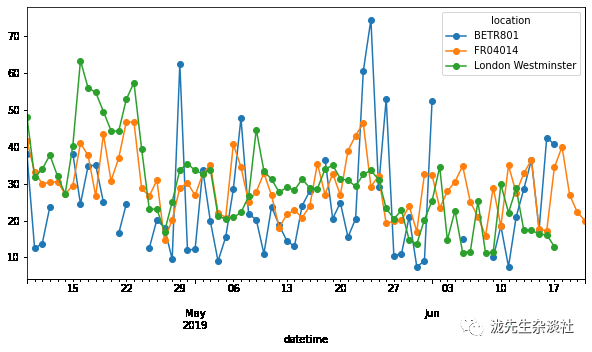
--------------分割线------------------
pandas支持4种通用的时间概念
| 概念 | 标量类型 | 数组类型 | pandas数据类型 | 基本创建方法 |
|---|
| 日期时间(Date times) | Timestamp | DatetimeIndex | datetime64[ns]或者datetime64[ns, tz] | to_datetime或者date_range |
| 时间差(Time deltas) | Timedelta | TimedeltaIndex | timedelta64[ns] | to_timedelta或者timedelta_range |
| 时间跨度(Time spans) | Period | PeriodIndex | period[freq] | Period或者period_range |
| 日期偏移量(Date offsets) | DateOffset | None | None | DateOffset |
1、日期时间(Datetime)
日期时间的标量数据类型为Timestamp也叫时间戳,它是用一个64位二进制带符号整数表达日期和时间,以便于时间计算。整数0,即时间戳的起点默认为1970-1-1 00:00:00。如果以秒为单位,那么整数值每加1,代表时间上也增加1秒。正整数代表后续时间,负整数则代表以前的时间。时间戳能表达的时间范围与单位有关,单位时间越短,能表达的时间范围也越窄,pandas默认的时间单位为纳秒,它可以表达时间范围为:
pd.to_datetime([2**63-1])
#第64位为0,代表正数,此为上限,也可用pd.Timestamp.max查看
DatetimeIndex(['2262-04-11 23:47:16.854775807'], dtype='datetime64[ns]', freq=None)
pd.to_datetime([-2**63+808])
#经测试,这个值是为下限,并未取完全部整数值,也可用pd.Timestamp.min查看
DatetimeIndex(['1677-09-21 00:12:43.145225'], dtype='datetime64[ns]', freq=None)
时间戳有若干日期时间属性,包括year、month、day、hour、minute、second、microsecond、nanosecond、date、time等等,其最突出的优点就是你可方便地使用部分属性将想要的值筛选出来。
2、时间差(Time deltas)
Time deltas表示的就是两个绝对时间点的差值,有了它你可以方便的计算时间(最大变化单位为天,最小为纳秒),而无需考虑时间变化的各种问题。
pd.to_datetime([0]) + pd.to_timedelta('1d') #增加 1 天
DatetimeIndex(['1970-01-02'], dtype='datetime64[ns]', freq=None)
pd.to_datetime([0]) + pd.to_timedelta('1m') #增加 1 分钟
DatetimeIndex(['1970-01-01 00:01:00'], dtype='datetime64[ns]', freq=None)
pd.to_datetime([0]) + pd.to_timedelta('1ns' )#增加 1 纳秒
DatetimeIndex(['1970-01-01 00:00:00.000000001'], dtype='datetime64[ns]', freq=None)
3、时间跨度(Time spans)
Time spans可以定义一种周期变量(period),通过设定变化频率可以方便控制期变化周期而无需考虑实际时间影响。
p = pd.Period('2020-1', freq='M') # 开始时间为2020年1月,以月为变化周期
p + 1
Period('2020-02', 'M')
p + 5
Period('2020-06', 'M')
4、日期偏移量(Date offsets)
Date offsets也是一种时间变化形式,它和Time deltas的区别在于,Time deltas只考虑了时间的绝对差值,而无法顾及实际日期带来的影响,如工作日需要从周五跳转到周一。使用Date offsets正是为了解决类似问题,通过调用各种日期偏移方法,可以无需考虑日期具体形式。
bd = pd.offsets.BusinessDay() # 定义一个工作日的偏移量
friday = pd.to_datetime('2020-6-19')
friday.weekday() # 0代表周一, 4代表周五
4
monday = friday + bd
monday.weekday()
0








 京公网安备 11010802041100号
京公网安备 11010802041100号