python有个很好用的数据分析库pandas,前段时间做了个数据挖掘的比赛,里面数据分析的部分,是用pandas来实现的,今天借助自己实践的经验,来总结一下pandas常用的数据分析方法。
1,创建数据表
pandas创建的数据是DataFrame格式的数据,有一些创建方法,其中有细微的差别,我们来实践一个简洁常用的方法,此处创建的数据作为后续数据分析的data。
创建三个数据表,分别为年级信息表:grade,一年级成绩表:g_one_score,二年级成绩表:g_two_score。
#先导入需要的库
import numpy as np
import pandas as pd
import os
os.chdir("D:/知乎图/pandas_data/")#将工作路径转为此路径grade=pd.DataFrame({"年级":["一","一","二","二"],"班级":["一班","二班","一班","二班"],
"班级代号":[11,12,21,22],"班主任":["大绿","大红","大白","大紫"],"人数":[2,3,3,2]})g_one_score=pd.DataFrame({"班级代号":[11,11,12,12,12],"姓名":["小红","小绿","小蓝","小紫",
"小粉"],"数学":[97,96,90,98,99],"语文":[91,91,92,93,89],"英语":[79,76,80,97,100]})g_two_score=pd.DataFrame({"班级代号":[21,21,21,22,22],"姓名":["小黑","小白","小橙",
"小青","小黄"],"数学":[100,87,86,90,88],"语文":[92,87,96,93,89],"英语":[69,np.nan,92,90,79]})

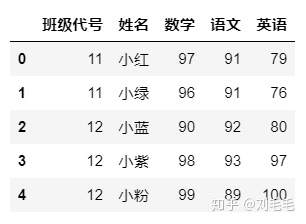
这里数据有点简陋,能说明问题即可。在表g_two_score表里有一个空值NaN,代表这个同学这门课缺考。
2,保存数据
我们生成的数据可保存为csv,或excel文件,方便以后调用。
##参数index设置为False,表示为不将index存入,不然下次调用,会多出一列。
grade.to_csv("grade.csv",index=False)g_one_score.to_csv("g_one_score.csv",index=False)
g_two_score.to_csv("g_two_score.csv",index=False)
此时,你的路径里多出以下三个文件。

3,读取数据
#读取数据
grade=pd.read_csv("grade.csv")
g_one_score=pd.read_csv("g_one_score.csv")
g_two_score=pd.read_csv("g_two_score.csv")
好了,兜了一圈,把数据读出来了,以上看似多余的操作,主要也是为了讲解pandas的用法,因为有时候,你只有csv文件,因此你需要读取操作,有时候,你需要存储操作。
4,查看和提取数据
4.1, 一般读取数据后,首先查看数据的大小,即shape。
print("grade:",grade.shape)
print("n")
print("g_one_score:",g_one_score.shape)
print("n")
print("g_two_score:",g_two_score.shape)

4.2, 查看每列的空缺值个数
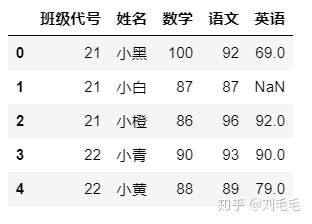
g_two_score.isnull()#isnull()函数查看空缺值

有时候是查看数据每列的空缺值个数,用来判断每个特征值是否有效,空缺值太大,在做数据挖掘时,此特征会丢掉,空缺值少,会想办法补上。
g_two_score.isnull().sum()

这里把补空缺值的方法讲了吧,思路有几种:①补同列上一行的值,②补同列下一行的值,③补指定的值。具体怎么填补,要在理解数据的基础上进行操作。使用的函数为:fillna()函数。

#我们,这里认为缺考成绩为0,因此用指定值0来填充。
g_two_score.fillna(0,inplace=True)
g_two_score
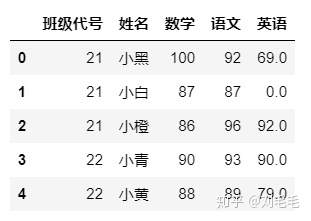
还有一个操作是填补此列的空缺值,将指定值参数赋值为此列的均值即可,那需要先求出此列均值。具体怎么做我们后面讲描述性统计方法时再说。
4.3, 查看数据表的值.values
#如果我们需要将数据的值提取出来,转化为二维数组或者矩阵形式,可这么做
g_two_score_values=g_two_score.values
g_two_score_values

4.4, 查看数据前五行,或后五行数据
g_two_score.head()#默认查看前五行,也可填入你想查看的行数。

g_two_score.tail(3)#默认查看后5行,也可填入想查看的行数
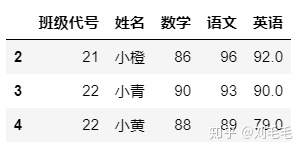
4.5, 查看数据的列名称,这个在做数据处理时,会常用
g_two_score.columns
Index(['班级代号', '姓名', '数学', '语文', '英语'], dtype='object')
4.6, 使用.loc[ ],.iloc[ ]进行数据提取查看。
g_two_score.iloc[0:3]#提取0,1,2,行数据,索引的方式与数组一样。

如果想只查看某些列的前三行数据可以这么做
g_two_score.iloc[0:3,1:3]
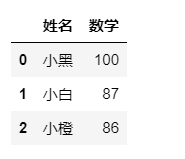
但是有时候,我们的数据很大,我们不能很方便得到想要查看列的索引,但是我们知道列名称,可以使用loc来操作。
g_two_score.loc[0:3,["姓名","语文"]]#等价于g_two_score.iloc[0:3,[1,3]]
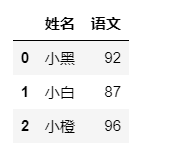
也可以直接提取指定列的信息
g_two_score["语文"]#得到的是一个Series
0 92
1 87
2 96
3 93
4 89
Name: 语文, dtype: int64
或者,我们想查看特定条件的行数据,比如提取小白和小橙的成绩信息,可以这么做
g_two_score["姓名"].isin(["小白","小橙"])#使用isin()函数判断,提取的行数
0 False
1 True
2 True
3 False
4 False
Name: 姓名, dtype: bool
g_two_score.loc[g_two_score["姓名"].isin(["小白","小橙"])]
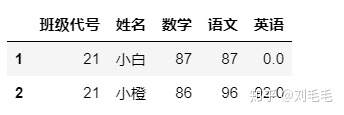
再或者,我们想查看其他特定条件的行数据,比如提取二班信息
代码如下
g_two_score.loc[g_two_score["数学"]>88]
g_two_score.loc[(g_two_score["数学"]>88)&(g_two_score["英语"]>85)]
g_two_score.loc[(g_two_score["数学"]>88)|(g_two_score["语文"]>90)]
g_two_score.loc[g_two_score["数学"]==100]g_two_score.loc[g_two_score["姓名"]!="小白"]
g_two_score.loc[~(g_two_score["姓名"]=="小白")]#取反操作,也可实现
###围观
可以不用.loc 也可实现此操作
g_two_score[g_two_score["数学"]>88]
g_two_score[(g_two_score["数学"]>88)&(g_two_score["英语"]>85)]
g_two_score[(g_two_score["数学"]>88)|(g_two_score["语文"]>90)]
g_two_score[g_two_score["数学"]==100]g_two_score[g_two_score["姓名"]!="小白"]
g_two_score[~(g_two_score["姓名"]=="小白")]#取反操作,也可实现
5,删除数据
使用drop()函数

例子如下:
g_two_score.drop("英语",axis=1)##删除“英语”这一列
g_two_score.drop(columns=["数学"],index=[0,1])
#删除数学这一列,和0,1行,这里,我们没有设index的名称,所以是自动生成的0,1,2,3,4
还有一种间接实现“删除”的方式,加双引号,只是不是真正的删除操作,就是前面讲过的取反操作,当你的数据很大,很多行,而你只想删除一小部分满足某条件的行,此时用drop实现不了,那我们可以提取,不满足这些条件的行,间接得到“删除”后的数据。
如:我们想提取删除语文成绩小于90,或者英语成绩小于80的数据
g_two_score[~((g_two_score["语文"]<90)|(g_two_score["英语"]<80))]

当然&#xff0c;如果你知道具体的行标&#xff0c;也可用drop()来做&#xff0c;要学会灵活应用。
6,描述性统计方法
有时候&#xff0c;我们需要知道数据的一些&#xff0c;统计信息&#xff1a;均值&#xff0c;最大值&#xff0c;最小值&#xff0c;总和。当然&#xff0c;这些只能在数值型数据上进行操作。
函数describe&#xff08;&#xff09;能统计各列诸多统计值
g_two_score.describe()#count非空元素的数目
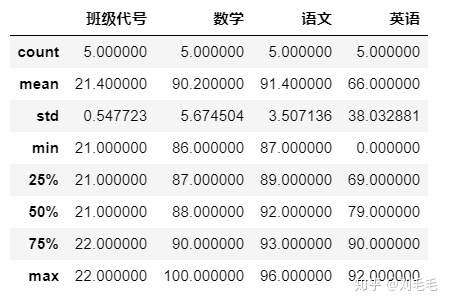
这里班级代号这一列并没有用&#xff0c;只不过&#xff0c;当时输入的也是数值。
count&#xff1a;非空元素个数。mean&#xff1a;均值。std&#xff1a;标准差。min&#xff1a;最小值。25%&#xff1a;四分之一分位数。max&#xff1a;最大值。
也可以单个求某列&#xff0c;或某些列的特定统计信息
print(g_two_score.quantile(0.25))#25%分位数
print("n")#换行
print(g_two_score["英语"].mean())
print("n")#换行
print(g_two_score[["语文","英语"]].min())
班级代号 21.0
数学 87.0
语文 89.0
英语 69.0
Name: 0.25, dtype: float64
66.0
语文 87.0
英语 0.0
dtype: float64
与describe&#xff08;&#xff09;得到的结果一致&#xff0c;没有错误
还记得之前补空缺值时的操作吗&#xff0c;我们说可以补均值&#xff0c;因为有时候&#xff0c;补均值会比较合理&#xff0c;实现方法如下&#xff1a;
g_two_score["英语"].fillna(g_two_score["英语"].mean())
0 69.0
1 82.5
2 92.0
3 90.0
4 79.0
Name: 英语, dtype: float64
如果加上参数inplace&#61;True,我们的原数据就填补完成了&#xff0c;不含空值&#xff0c;不过这里需指定单个的列。
7&#xff0c;合并
7.1&#xff0c;merge函数
用法
DataFrame1.merge(DataFrame2, how&#61;‘inner’, on&#61;None, left_on&#61;None, right_on&#61;None, left_index&#61;False, right_index&#61;False, sort&#61;False, suffixes&#61;(’_x’, ‘_y’))
或
pd.merge(DataFrame1,DataFrame2, how&#61;‘inner’, on&#61;None, left_on&#61;None, right_on&#61;None, left_index&#61;False, right_index&#61;False, sort&#61;False, suffixes&#61;(’_x’, ‘_y’))
参数
举例来看&#xff0c;比如我们想知道二班成绩表里的每位同学所属班级&#xff0c;班主任等grade表里的信息&#xff0c;我们的想法自然是将两个表连接起来。连接的依据字段为班级代号&#xff0c;即把班级代号相同的行连接起来。
grade.merge(g_two_score,on&#61;"班级代号",how&#61;"inner")
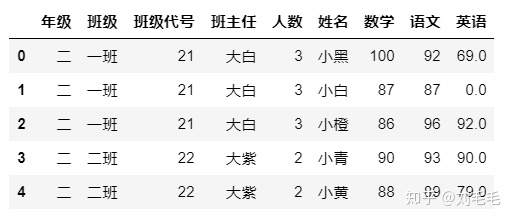
如果懂sql的同学&#xff0c;对于这部分的理解会比较容易&#xff0c;刚接触的同学理解会有一点困难&#xff0c;我再多写一句&#xff0c;这里的连接&#xff0c;你可以这么想&#xff0c;连接的过程可以想象为&#xff0c;笛卡尔积&#xff0c;即左表的每一行会与右表的每一行配对&#xff0c;然后依据on将所选字段对应相等的联结行留下来&#xff0c;其他的不符合的删掉&#xff0c;就是最终的结果。
这里说成联结比较专业&#xff0c;我一般写成连接了。
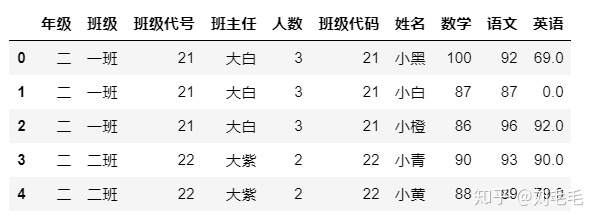
如果两个表里联结的字段名不同呢&#xff0c;比如在g_two_score里的“班级代号”是“班级代码”呢&#xff0c;怎么做&#xff0c;该left_on和right_on上场了。
#使用rename函数将g_two_score里的字段名“班级代号”重命名为“班级代码”&#xff0c;赋值给一个新表
g_two_copy&#61;g_two_score.rename(columns&#61;{"班级代号":"班级代码"})#将grade表和g_two_score表依据左表的“班级代号”和右表的“班级代码”来连接&#xff0c;代码如下
grade.merge(g_two_copy,left_on&#61;"班级代号",right_on&#61;"班级代码",how&#61;"inner")
现在试试左外联结on&#61;“left”&#xff0c;左外连接是将左表里多余的没有关联的行留下
pd.merge(grade,g_two_score,on&#61;"班级代号",how&#61;"left")

可以看到班级代号为11,12的没有关联的行&#xff0c;但是溜了下来&#xff0c;右外联结“right”&#xff0c;是将右表中没有关联的行留下来&#xff0c;全外连接“outer”是将两个表中没有关联的行全留下来。
7.2&#xff0c;concat
用法
pd.concat([DataFrame1,DataFrame2],axis&#61;0,join&#61;"outer",join_axes&#61;None,ignore_index&#61;False,keys&#61;None,sort&#61;True)
参数
举个例子来说明什么情况下使用concat
例1&#xff1a;xx水果店有三个员工&#xff0c;一周轮流上班&#xff0c;每天的员工需记录每天每种水果的销量&#xff0c;前三天小明值班&#xff0c;但她只记录了“苹果”“香蕉”“橘子”“火龙果”的销量&#xff1b;星期四&#xff0c;五&#xff0c;小红值班&#xff0c;她只记录了“苹果”“香蕉”“芒果”“猕猴桃”的销量&#xff1b;星期六&#xff0c;日&#xff0c;小海值班&#xff0c;他只记录了“橘子”“火龙果”“芒果”“猕猴桃”的销量。这三个员工不称职啊&#xff0c;哈哈&#xff0c;我们为了能说明问题&#xff0c;瞎编的哈。
###这也是构造数据的另一种方法。
d1&#61;pd.DataFrame(np.ones((3,4)),columns&#61;["苹果","香蕉","橘子","火龙果"],index&#61;["星期一","星期二","星期三"])
d2&#61;pd.DataFrame(2*np.ones((2,4)),columns&#61;["苹果","香蕉","芒果","猕猴桃"],index&#61;["星期四","星期五"])
d3&#61;pd.DataFrame(3*np.ones((2,4)),columns&#61;["橘子","火龙果","芒果","猕猴桃"],index&#61;["星期六","星期日"])
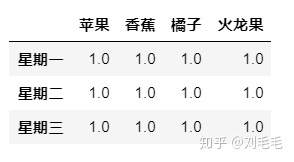

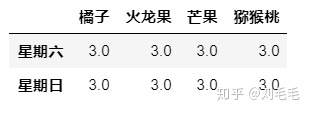
##我们跟前两个表来看一下&#xff0c;前五天的销售情况&#xff0c;主要看一下join的两种不同的取值差别
pd.concat([d1,d2],join&#61;"outer",axis&#61;0,sort&#61;False)##并集&#xff0c;没有数据按空值处理
pd.concat([d1,d2],join&#61;"inner",axis&#61;0,sort&#61;False)##交集
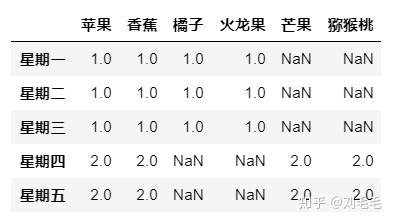
###join_axes
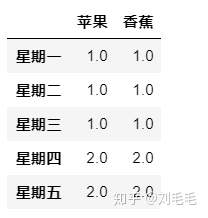
pd.concat([d1,d2],join&#61;"outer",axis&#61;0,join_axes&#61;[d1.columns],sort&#61;False)#只显示d1含有的水果名
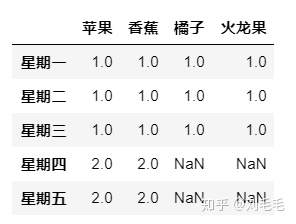
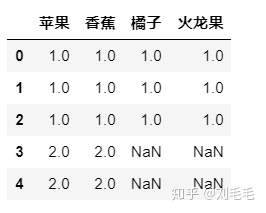
#忽略原有行标&#xff0c;默认系统生成。
pd.concat([d1,d2],join&#61;"outer",axis&#61;0,join_axes&#61;[d1.columns],ignore_index&#61;True,sort&#61;False)
###使用keys
pd.concat([d1,d2],join&#61;"outer",axis&#61;0,join_axes&#61;[d1.columns],keys&#61;["x","y"],sort&#61;False)
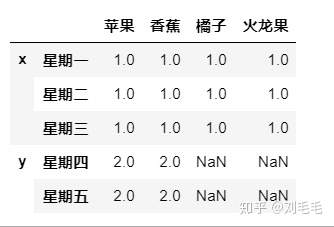
关于axis&#61;1的方向的合并&#xff0c;我就不举例子了&#xff0c;如果碰到&#xff0c;这样的问题&#xff1a;水果店有两个员工&#xff0c;一个人记录其中几个水果的销量&#xff0c;我们需要合并记录这一周两个员工记录的水果销量。这时候需要横向合并&#xff0c;具体问题具体来分析怎么合并。
7.3&#xff0c;append
这是一个最简单的合并函数&#xff0c;只能竖向合并
用法
DataFrame1.append&#xff08;DataFrame2&#xff0c;ignore_index&#61;False&#xff09;
等价于pd.concat([DataFrame1,DataFrame2])
还记不记得我们还有一个表&#xff1a;g_one_score,一班同学的成绩信息表&#xff0c;我们现在想将一般和二班同学的成绩合并在一起&#xff0c;可以这么做。
g_one_score.append(g_two_score,ignore_index&#61;True)##ignore_index参数跟concat里的一样
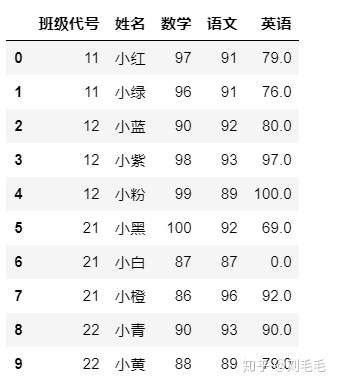
8&#xff0c;groupby函数与agg函数
8.1&#xff0c;grouby&#xff08;&#xff09;
groupby&#xff08;&#xff09;函数的作用与sql里的group by一样&#xff0c;按某列或几列的值实行分组。
按某一列对表中的某一列进行分组计算
##计算每个班的数学均值
g_two_score["数学"].groupby(g_two_score["班级代号"]).mean()
班级代号
21 91
22 89
Name: 数学, dtype: int64
按某一列对表中的多列进行分组计算
g_two_score[["数学","语文"]].groupby(g_two_score["班级代号"]).sum()

注&#xff1a;groupby里面的依据分组字段必须写成 g_two_score["班级代号"] 原因为需要分组的字段里不含有“班级代号”&#xff0c;如果写成这样
g_two_score[["数学","语文"]].groupby(["班级代号"]).sum()
###会报错&#xff0c;原因找不到字段“班级代号”
下面这样是可以的&#xff0c;这也是易出现的小错误的地方
g_two_score[["数学","语文","班级代号"]].groupby(["班级代号"]).count()
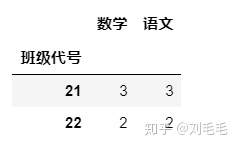
按多列对表中的多列进行分组计算
#先按“年级”再在每个年级里按班级分组&#xff0c;最后计算每个小组的个数
grade[["班主任","人数"]].groupby([grade["年级"],grade["班级"]]).count()
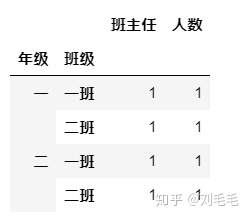
有时候是对整个表按照某一列或多列进行分组
grade.groupby([grade["年级"]]).count()
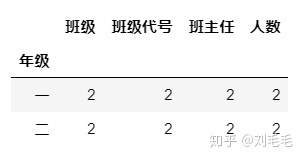
如果整个表进行分组后&#xff0c;只想看某一列的数据
grade.groupby([grade["年级"]])["人数"].count()
年级
一 2
二 2
Name: 人数, dtype: int64
注&#xff1a;上面我们看到数据分组后会跟着一个统计计算&#xff0c;我们来列一下有哪些统计计算。

还有些统计性分析的函数&#xff0c;会在做数据分析的时候用到&#xff0c;我们在这里提一下
#计算两个字段的相关性
g_two_score["数学"].corr(g_two_score["英语"])
#计算这个数据表的相关性&#xff0c;即任意两个字段的相关性
g_two_score.corr()
8.2&#xff0c;agg()
groupby函数经常与agg函数一起使用&#xff0c;我们看一下&#xff0c;agg是怎么用的。
对所有列应用一个相同的统计计算
gg&#61;g_two_score.groupby(["班级代号"])##先分组
gg.agg("mean")###后聚合计算
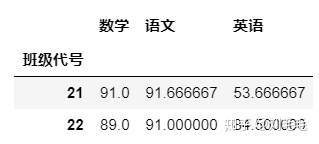
这个结果与
g_two_score.groupby(["班级代号"]).mean()
结果相同。
对所有列应用相同的多种统计计算
当我们想对分组后的数据进行多种统计计算时&#xff0c;比如&#xff1a;mean&#xff0c;std一起时&#xff0c;agg的有点就显现出来了。
gg&#61;g_two_score.groupby(["班级代号"])
gg.agg(["mean","std"])#多种统计函数使用列表
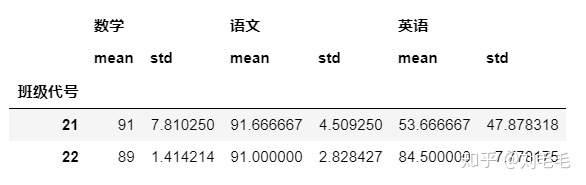
对所有列应用不同的多种统计计算
也可以对不同分组后的字段进行不同的统计计算&#xff0c;我们使用字典来传入。
gg&#61;g_two_score.groupby(["班级代号"])
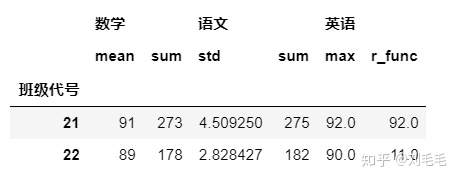
gg.agg({"数学":["mean","sum"],"语文":["std","sum"],"英语":"max"})
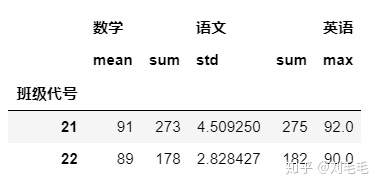
应用自定义函数
除此之外&#xff0c;还可以传入自己设置的函数。比如设置一个计算极值的函数。
def r_func(arr):#极差return arr.max()-arr.min()
gg&#61;g_two_score.groupby(["班级代号"])
gg.agg({"数学":["mean","sum"],"语文":["std","sum"],"英语":["max",r_func]})
感谢参考到的几篇文章&#xff01;
pandas 菜鸟教程_python_夭夜的博客-CSDN博客blog.csdn.net









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有