作者:HelloMsLin你好_林小姐 | 来源:互联网 | 2023-07-03 15:29
本文由编程笔记#小编为大家整理,主要介绍了藏经阁基于PaddlePaddle训练APP UI样式bug的预测模型相关的知识,希望对你有一定的参考价值。
长期以来对于UI样式问题的测试校验,多数依赖于人工测试,毕竟人眼识别样式问题是最快的。随着移动时代的快速发展,越来越多的移动设备、操作系统版本导致组合爆炸,测试人力成本上居高不下。
由此也衍生出很多UI自动化测试方案尝试提升效率、释放人力,通常通过断言的形式,check当前页面是否存在指定的元素,以及对应的属性值正确与否,但对于稍复杂的样式问题,如控件错位、文字重叠、页面留白等问题并不适用,见下图所示,文字出现重叠或遮挡,假设沿用Dom树元素解析与定位,可以定位到文本字符符合预期,但样式上则无法直接判断是否合理、是否有损用户视觉体验。
那么对于人眼可以快速识别的UI样式的一些低级bug,如何让计算机来识别,在计算机视觉这个课题领域就是非常基础的内容了。于是在开源框架paddlepaddle基础之上,对已知的一些典型UI样式问题进行了模型训练,通过实践帮助QA在APP自动化测试工作上提升了一定的工作效率。
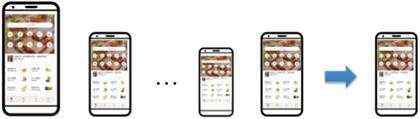
在糯米app的UI兼容性测试场景中,当使用不同型号的手机进行兼容性测试进行镜像操作的时候,每一步事件镜像过程中都保留该执行步骤对应的手机截图,如下图所示。假设其中一部手机页面完全不存在兼容性问题,可将其作为参照物,利用图像特征点匹配或相似度算法,如SIFT、SURF、直方图、pHash等,横向比对其余手机上的截图。通过这种有参照物横向比对的方式,可以发现其中存在疑似兼容性问题的页面。
每一步事件镜像:
经横向比对后,能帮助我们发现哪个手机上存在疑似的兼容性问题,但具体属于哪个类别的兼容性问题,暂且不能自动化地给出结果,因此需要通过一种更细粒度的手段来让机器帮助我们做出判断。
鉴于此,我们结合深度学习中图像分类的思路,将图像分类的类别变为UI Bug的类别,输入是经横向比对后疑似有兼容性问题的页面截图,那么输出则是经深度学习模型预测后的结果,结果中的标签对应具体的兼容性问题类别。
接下来,我们结合在实际测试场景中遇到的兼容性问题进行实践,为了进行UI Bug自动化校验,首先需要训练出一种模型,假设该模型能够预测出三种兼容性问题的类别,分别是键盘样式类、文字重叠类和页面留白类。模型的训练和预测部分,我们使用的是百度开源的PaddlePaddle深度学习框架,其特性在文章的最后做了概括说明。在实践中最困难的要属训练样本的构造,因为深度学习需要大批量的数据样本,即便我们搜集了很多产品线中已有的UIBug库中的问题图片,数量仍难以满足需求,而接下来的数据准备部分,会具体介绍我们是如何批量构造训练样本数据来攻克难题的,以及常见的构造方法。最后的效果验证,我们事先准备了几份包含兼容性问题的页面截图,目的是让模型去预测其所属的兼容性问题类别,以评估模型分类的效果。
1.数据准备
由于深度学习需要大量级的训练样本数据,通过手工地截取正负样本的图片似乎不太现实,因此需要一种自动化、批量地构造训练样本的方法。常见的方法有数据构造、data augmentation等。对于数据构造,通常需要结合图片的结构特点,经图片拼接自由组合便可以达到我们所需要的数据量级。对于data augmentation,通常通过随机平移、旋转、加噪声等方式,从已有小批量数据集中扩充出一批‘新’数据。
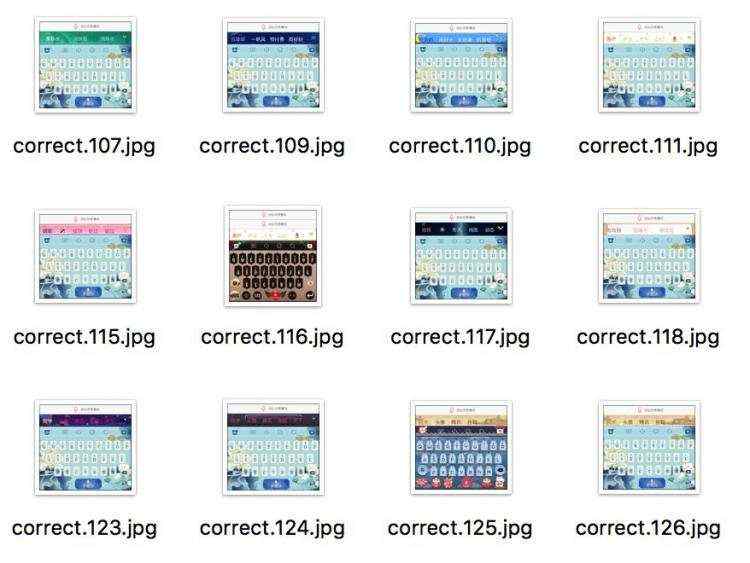
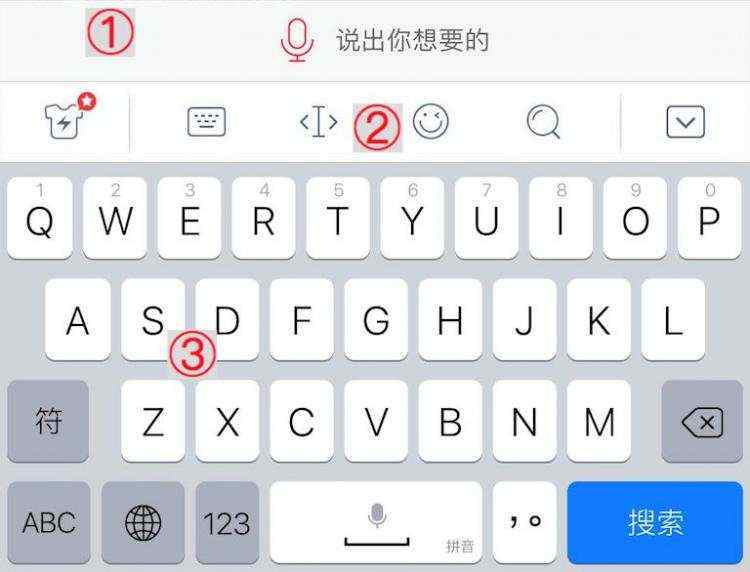
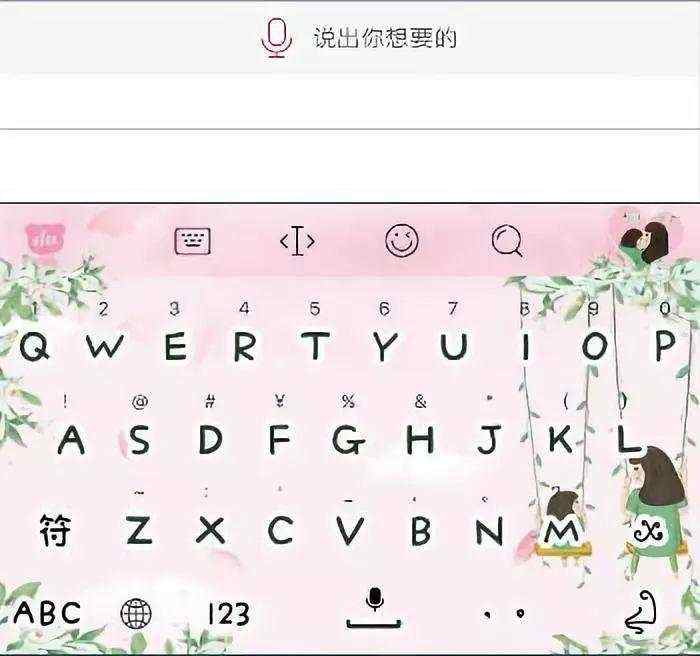
在准备‘键盘样式类’兼容性类别时,我们使用的是数据构造法。假设我们所需要2万张含正负样本键盘样式的图片,结合键盘图片的结构发现,如下图所示,其主体部分由①②③部分所组成,因此我们只需要针对每一部分截取一定数量的样式图片,再通过图片拼接的方式就可以自由组合生成所需数量的样本。而键盘样式的负样本中,其中一类的特点是中间的输入栏为空白,因此只需在②③部分中插入空白条便可构造出这类负样本。另外,对于没有固定结构特点的bug类别,如文字重叠等,我们需要一种更加随机地方式去粘贴和拼接图片素材,尽可能的贴合实际UIBug的样式。
2.模型定义
网络模型定义是深度学习的关键,而图片分类的模型通常采用CNN(卷积神经网络),由四块重要的‘积木’组成:全连接、激活函数、卷积和池化。全连接,模拟人类神经网络结构,使得每个神经元节点都和上一层所有神经元相连。从图中看出,当输入是一张3通道100*100大小的图片时,其后网络中每一层的节点都和3*100*100个输入节点相连接,可见网络之复杂,参数之多。激活函数,引入了非线性因素,否则输出永远是输入的线性组合。而与图像的二维矩阵的卷积操作可以提取图像从低级到高级的特征,卷积中局部连接和权重共享的属性可以减小神经网络参数。池化操作能够在一定程度上控制过拟合,通常在卷积层的后面会加上一个池化层进行下采样。最后经Softmax分类器,将输出结果归一化到0-1区间的概率值,从而对应各个类别。
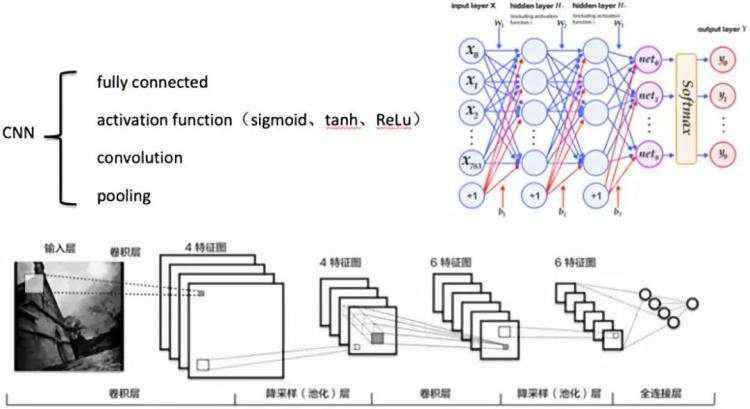
关于网络模型还有非常多的选择,从ImageNet竞赛历年结果来看,网络模型的层数越来越多,预测的效果也越来越好。
3.训练&效果验证
经训练得到了的模型支持对3种兼容性问题类别的判断,分别是键盘样式类、文字重叠类和页面留白类。为了验证分类的效果,通常我们在构造训练样本时就留有部分数据作为测试集(含正负样本的1000张键盘样式图片和文字重叠图片),经实际预测,分类的准确率达97%。当然,测试集中的图片都是人为构造生成的,为了使得结果更具说服力,我们从主流app中随机抽取若干包含键盘被调起的页面截图和含文字重叠问题的截图,如下图所示。
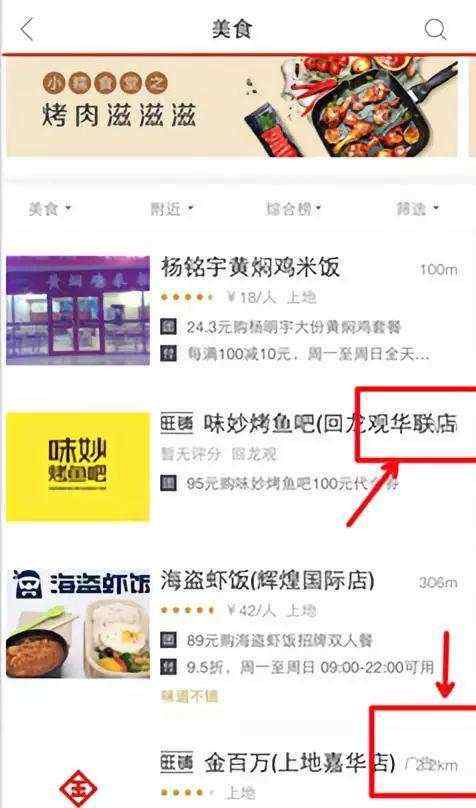
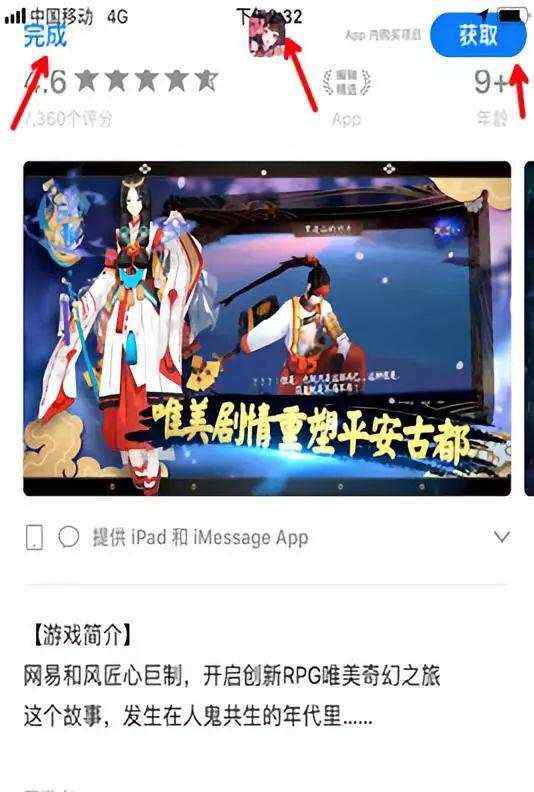
如下面流程图所示,在输入模型预测之前,先要对原始的图片进行预处理,主要包括图像区域的切割、图像大小的调整和文件格式的转换。相较于整图作为输入,图像按块切割后使得模型可以更好地提炼该区域的特征,从而减少其他区域的噪声干扰。常见的方法有,根据页面元素dom进行解析和切割,利用opencv的边缘检测算法进行切割等。此外,图像大小需要统一调整至固定值,常见的3通道图片也要转化成n维数组,便于模型的初始化和读取。预处理之后的键盘样式和文字重叠类别的图片,经模型预测,分类的准确率分别是95%和77%。分析badcase时发现,对文字重叠类图片的切割中包含有许多类特殊的图片,如图中字区域、因滑屏造成的自身被截断等,而这些图片区域中恰恰比较容易出现边缘被剪切或覆盖的情况,是应当提前过滤掉的,因此文字重叠类的识别准确率未来仍有提升的空间。
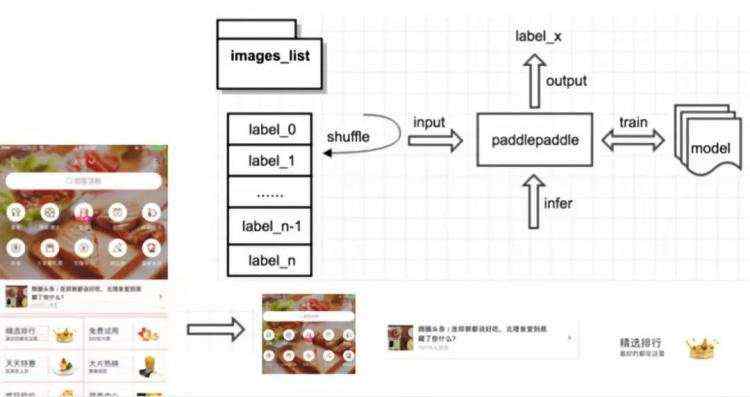
综上,从对实际问题的分类结果中,验证了该方案的可行性。为了使模型可以预测更多类别的兼容性问题,我们可以增加更多类别的训练样本以构造一个多分类的model。
4.PaddlePaddle的特性
PaddlePaddle是百度自主的深度学习开源框架,目前支持linux、MacOs、Docker上的安装和使用,具有环境搭建方便、配置简单、速度快、支持分布式和多机平行计算等优势。其在图像分类、词向量分析、个性化推荐、情感分析、语义角色标注、机器翻译等方向都有丰富的demo可供大家学习和参考。此外,PaddlePaddle相较于tensorflow和caffe而言,也拥有自己的技术优势,如下表所示。

经实践,验证了深度学习模型应用于UI Bug自动化校验是可行的,具有取代传统的UI校验的方式的潜力,可以适用于更复杂的兼容性问题分析和定位。
区别于传统‘断言式’的UI自动化校验,该方案对各类app更加通用和普适。我们通过自动化框架收集手百和糯米app上某一时段的端监控截图,运用我们的方案进行UIBug自动化校验,下面给出效果数据:总处理图片数470张,总校验次数10842次(整图+控件维度),发现有效bug13枚,举例如下(除端监控网络原因造成的截图异常外,已将发现的有效bug反馈给各业务方同学):

未来,我们会在保证模型识别的召回率和准确率的基础上,逐步增加支持的兼容性问题类别。
项金鑫
百度高级测试开发工程师,在深度学习模型应用于移动端UI测试领域拥有丰富的实践,开发的UIBug自检测工具为qa移动端手工测试节省了人力






 京公网安备 11010802041100号
京公网安备 11010802041100号