全称 Message Queue,被称为消息队列
队列,类似于一种 List 结构,专门来存储数据的队列
如果要往队列中存数据的话
可以从队头中存,1先进,存到队列中就是这样:3 -> 2 -> 1,从队尾取的时候,1先出,结果就是这样:1 -> 2 -> 3,这是很典型的先进先出队列
如果存的方式与上面一样:3 -> 2 -> 1,而取的时候从队头取,3先出,结果就变成了这样:3 -> 2 -> 1,这就是先进后出
如果队头、队尾都可以放数据,这样的队列被称为双端队列
Java 中也提供 Queue 的相关操作,但是 Java 里面的 API 都是基于内存级别的,而我们的微服务使用它的 API 来保存数据,那最多只能在它的机器里面使用
分布式系统中,我们需要消息中间件 ,是安装在服务器里的,我们的消息全部保存到这个服务器里面,所有微服务都可以通过这个服务器取消息,而 RabbitMQ 就是我们要使用的消息中间件
假设我们的一个普通业务,以用户注册为例,用户通过浏览器提交了账号、密码等注册信息,注册信息可能分为以下这三步

这是一种同步模式,用户在每一个步骤都会花费 50ms 的时间,加起来就是 150ms 的时间, 我们发现这是没有必要的
尤其是第2步跟第3步,如果我们使用下面这种模式,可以给它弄一个异步

用户将注册信息写入到数据库之后,我们创建两个异步任务,一个发送注册邮件,一个发送注册短信,当然我们需要最终的完整返回,但是我们只需要等待时间最长的一个返回,就可以获取到两个结果
这样,我们就将时间缩短到了 100ms ,看起来时间更快了,但是实际上,我们连异步都不需要
因为,我们发现注册邮件、注册短信,这两个任务,让它在后台慢慢发就行,成功或是失败,我们无需知道,只要它做了这个事就行,而且我们经常会有收不到短信、收不到邮件的情况,所以,遇到这种情况,我们还可以使用下面这种方式

我们如果将注册信息写入数据库成功了,接下来,我们将注册成功的消息写入消息队列,保存在消息中间件这个服务器中,假设:保存了一个1号用户注册成功的消息,至此,我们就直接给用户返回
因为给消息中间件写消息这个耗时是非常短的,数据库插入数据库可能很慢,需要 50ms ,而写消息,类似于直接操作 redis 一样,可能只花费 5ms,很快,那么用户收到这个响应只需要 55ms,但是用户能不能收到邮件、短信呢?
也可以,我们的消息既然存到了消息队列里面,别的服务就可以从消息队列里面拿到这个消息,假设:这个服务拿到1号用户注册成功的消息了,那么它就在后台该发邮件发邮件,该发短信发短信,我们不关心它什么时候发短信、发邮件,只要它干了这个事就行,但是用户会一起响应成功。
这就是异步处理,使用起来比异步任务更快,异步任务我们还必须等待消息返回,而这个异步处理,只需要给消息中间件的服务器发一个消息,让它在后台慢慢处理就行。
我们以下订单为例:比如,我们下了一个订单,我们下完订单之后,需要做出库操作,像我们以前做的,一般是使用下面这种方式

假设订单系统有3个参数,库存系统有5个参数,直接调用就可以,如果这个库存系统不升级,API 也不变,一直是这几个参数还好,
假设我们库存系统经常会升级, 减库存的接口经常发生变化,这样我们以前的这种调用方式,一旦库存系统升级了,则订单系统必须修改它的源代码,重新部署,这样就感觉会非常麻烦,所以我们可以引入消息队列,
订单系统只要下好订单,我们给消息队列里面写上一个消息,说我们哪个用户下了哪个订单购买了哪个商品,把这个消息保存到队列里面,我们不关心库存系统的接口是什么样,不管它要几个参数,我们只需要把我们的消息写进去,接下来库存系统要实时订阅我们队列里面的内容,只要有内容,库存系统就会收到我们订单系统写的消息,然后它自己分析消息,然后对库存进行修改

此时,我们发现,订单系统执行完任务之后,我们无需关心库存系统要调用什么接口,我们只需要写消息即可,所以我们就实现了应用解耦
以后,无论什么系统,想要知道我们订单成功之后要做什么,只需要订阅消息队列中订单成功的消息,
而订单系统不需要关心别的系统接口设计成什么样子,因为订单系统根本就不会调用它们
针对一些秒杀业务来说,瞬间流量会非常大,比如:瞬间百万个请求都要进来秒杀一个商品,这个商品要真正去执行业务,就算我们前端服务器可以接受百万请求,我们要执行业务代码,因为我们秒杀完之后,要下订单,整个流程会非常慢, 后台会一直阻塞,可能就会导致资源耗尽,最终导致宕机
此时,我们可以这样做,我们让大并发的请求全部进来,进来以后,先将它们存储到消息队列里面,存到消息队列以后,我们就可以不用管这个请求该怎么做了,直接给它响应:秒杀成功了或者其他
然后,消息队列中,后台真正的业务处理要下订单、减库存等等这些业务处理,我们不着急立即调用,只要存到消息队列里面,这些业务去订阅消息队列里面进来的这些秒杀请求,接下来,挨个处理:下订单…,即使后台每秒只能处理1个,那100W请求,也就花费100W秒,但永远都不会导致机器的资源耗尽,导致宕机所以我们可以达到前端的流量控制。

我们把所有的流量存到队列里面,后台根据它的能力,去来进行消费处理,不会导致机器宕机,这就是流量控制,也被称为流量削峰
将峰值削下来,全部存到队列里面
RabbitMQ是一个由erlang开发的AMQP(Advanved Message Queue Protocol)的开源实现。
消息代理(message broker)和目的地(destination)
消息代理:指的是一个代理代替我们发送、接收消息,
目的地:指消息的目标位置
发消息的整体流程就是:
当消息发送者要发送消息时,这个消息会先发给消息代理(也就是消息中间件服务器),消息代理会发到我们指定的目的地
只要是消息中间件,一定会有这两种模式
消息发送者发送消息,首先发送给消息代理, 消息代理收到消息之后,如果消息发送者说要发给一个队列,消息代理就会将其放入一个队列中,队列都是先进先出,消息先进来就会先取到,
别人如果要获取队列中的消息,怎么办?
别人可以监听队列里的消息内容,一旦队列里面有消息,这个人就可以拿到消息 ,
消息有唯一的发送者、接收者, 也就是说谁发送消息这是肯定的,谁最终拿到消息这也是肯定的,但是并不是说只能有一个接收者 ,可以很多人都来接收队列里面的消息,队列可以允许很多人同时监听消息
但是如果是点对点式(队列式),消息放到队列之后,最终只会交给一个人, 谁先抢到,就是谁的
消息一旦被别人抢到,就会从队列中移除,队列里面就没有这个消息了
发送者(发布者)先将消息发给消息代理, 消息代理要将消息发送到主题,这个主题可以有多个接收者(订阅者)同时监听(订阅)
,跟队列一样,
如果是队列,那么多个人监听,最终只会有一个人收到消息,
但如果是一个主题,主题是一种发布订阅模式,只要消息一到达,那么所有订阅消息的人都能收到消息
JMS(Java Message Service)JAVA消息服务
基于JVM消息代理的规范。ActiveMQ、HornetMQ是JMS实现
AMQP(Advanced Message Queuing Protocol)
| JMS(Java Message Service) | AMQP(Advanced Message Queuing Protocol) | |
|---|---|---|
| 定义 | Java api | 网络线级协议 |
| 跨语言 | 否 | 是 |
| 跨平台 | 否 | 是 |
| Model | 提供两种消息模型: (1)、Peer-2-Peer (2)、Pub/sub | 提供了五种消息模型: (1)、direct exchange (2)、fanout exchange (3)、topic change (4)、headers exchange (5)、system exchange 本质来讲,后四种和JMS的pub/sub模型没有太大差别, 仅是在路由机制上做了更详细的划分; |
| 支持消息类 型 | 多种消息类型: TextMessage MapMessage BytesMessage StreamMessage ObjectMessage Message (只有消息头和属性) | byte[] 当实际应用时,有复杂的消息,可以将消息序列化后发 送。 |
| 综合评价 | JMS 定义了JAVA API层面的标准;在java体系中, 多个client均可以通过JMS进行交互,不需要应用修 改代码,但是其对跨平台的支持较差; | AMQP定义了wire-level层的协议标准;天然具有跨平 台、跨语言特性。 |
@JmsListener(JMS)、@RabbitListener(AMQP)注解在方法上监听消息代理发布的消息@EnableJms、@EnableRabbit开启支持JmsAutoConfigurationRabbitAutoConfiguration
一旦消费者(Consumer)出现了问题,宕机或者各种,连接中断了,RabbitMQ就会实时的感知有消费者下线,消息没办法派发,它就会再次存储到队列(Queue)中,不会造成大面积的消息丢失,
消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。
消息的生产者,也是一个向交换器发布消息的客户端应用程序。
交换机 ,用来接收生产者发送的消息,并将这些消息路由给服务器中的队列。
Exchange有4种类型:direct(默认),fanout, topic, 和headers,不同类型的Exchange转发消息的策略有所区别
消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直
在队列里面,等待消费者连接到这个队列将其取走。
绑定,用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交
换器理解成一个由绑定构成的路由表。
Exchange 和Queue的绑定可以是多对多的关系。
网络连接,比如一个TCP连接。
信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内的虚拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。
消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。
虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个 vhost 本质上就是一个 mini 版的 RabbitMQ 服务器,拥有自己的队列、交换器、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接时指定,RabbitMQ 默认的 vhost 是 / 。
表示消息队列服务器实体

# 运行,第一次没安装会自动安装
docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management
# 开机自启
docker updata rabbitmq --restart=always
官方文档

消息生成者发送一个消息,消息先发给消息代理(Broker),由代理先将消息交给(Exchange)交换机,然后这个交换机下面可能会绑定(Bingdings)了很多队列(Queues),所以一个交换机跟很多种队列都有绑定关系,
一个交换机可以绑定很多队列,一个队列也可以被多个交换机绑定,所以它们之间有非常复杂的绑定关系,
接下来就由交换机决定,消息要按照什么绑定关系路由给哪个消息队列,这个关系就是消息路由
这个路由是根据一开始发的**路由键(routing-key)**指定的,由于这个消息是先发送给交换机,所以交换机不一样,它绑定关系不一样,最终路由到的地方也不一样,消费者收到的消息就不一样
Exchange分发消息时根据类型的不同分发策略有区别,目前共四种类型:
direct、header 是一致的,它们都是JMS中说的点对点通信方式实现
fanout、topic则是发布订阅的一些实现
交换机的类型不同,最终路由到的地方就不一样
你的ip:15672




一创建之后,点进交换机,交换机的绑定关系里面,就会发现已经与队列 indi 绑定上了

它将消息直接交给一个指定的队列,路由键需要按照绑定关系精确匹配

比如,现在有一个直接交换机,它绑定了3个队列,第一个叫 dog,第二个叫 dog.gurad,第三个叫 dog.puppy,如果说消息发送过来,我们用的路由键叫 dog,那它就会精确的只发送给 dog 队列,实现消息最终只能到达一个队列,这就叫直接类型交换机,也称为单播模式、点对点通信
路由键是跟交换机和队列的绑定关系进行匹配的,我们将这种匹配称之为路由键的完全匹配
发消息是发给交换机,监听消息是监听队列,交换机将消息交给队列了,那么监听这个队列的人就会拿到消息
先创建好交换机、队列,并建立绑定关系





如果交换机下绑定了3个队列,消息一到达交换机,这3个队列都会收到, 这个消息会广播出去,根本就不关心路由键是什么,把所有消息都通过交换机广播给它绑定的所有队列,被称为广播模式



虽然它也是广播模式,比如它绑定了几个交换机,但是它可以指定某些交换机来发送消息,其余没指定的,则不会收到消息,所以它是部分广播,主要是根据路由键匹配将消息发个队列,这就是主题-发布订阅模式
它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开。
它同样也会识别两个通配符:符号 “#” 和符号 “*”。
# 匹配 0 个或多个单词,
* 匹配一个单词
以上面的 usa.# 为例,所有 usa 开头的路由键会进入这个队列
而 #.news ,则是所有以 news 结尾的路由键会进入这个队列
Name:交换机名称
Type:交换机类型
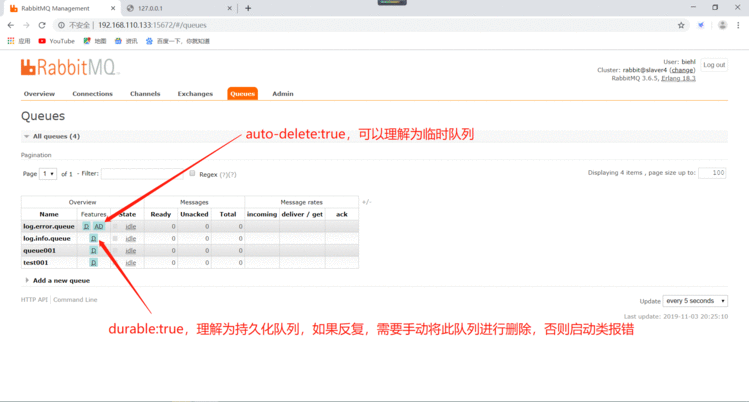
Durability:Durable(持久化)/ Transient(临时)
Auto delete:是否自动删除,会在没有任何队列绑定它时自动删除
Internal:是否为内部交换机,如果是,客户端则无法给交换机发消息,可能只供转发路由使用





以订单服务为例
spring-boot-starter-amqp
spring:
rabbitmq:
host: 192.168.2.190
port: 5672
virtual-host: /
启动类上添加
@EnableRabbit
/*
类和方法上面都可以加,一般加在类上
表示监听哪些队列
*/
@RabbitListener(queues = {"hello-java-queue"}) // queues:声明需要监听的所有队列
/*
与@RabbitListener组合使用可以区分不同重载的消息
只能加在方法上
指明哪个方法接收消息
*/
@RabbitHandler

https://gitee.com/UnityAlvin/gulimall/commits/master
在分布式系统中,比如现在有很多微服务,微服务连接上消息队列服务器,其它微服务可能还要监听这些消息,
但是可能会因为服务器抖动、宕机,MQ 的宕机、资源耗尽,以及无论是发消息的生产者、还是收消息的消费者,它们的卡顿、宕机等各种问题,都会导致消息的丢失,比如发送者发消息的时候,给弄丢了 ,看起来消息是发出去了,MQ网络抖动没接到, 或者MQ接到了,但是它消费消息的时候,因为网络抖动又没拿到,等等各种问题
所以在分布式系统里面,一些关键环节,我们需要保证消息一定不能不丢失,比如:订单消息发出去之后,该算库存的、该算积分的、该算优惠的等等 ,这些消息千万不能丢,因为这都是经济上的问题
所以,想要保证不丢失,也就是可靠抵达,无论是发消息,可靠的抵达MQ,还是收消息,MQ的消息可靠抵达到我们的消费端,我们一定要保证消息可靠抵达,包括如果出现错误,我们也应该知道哪些消息丢失了,
以前我们要做这种事情,可以使用事务消息,比如我们在发消息的时候,我们发消息的客户端首先会跟 MQ 建立一个连接,会在通道里面发消息,可以将通道设置成事务模式,这样发消息,只有整个消息发送过去,MQ消费成功给我们有完全的响应以后,我们才算消息成功,
但是使用事务消息,会使性能下降的很严重,官方文档说,性能会下降250倍…
为了保证在高并发期间能很快速的,确认哪些消息成功、哪些消息失败,我们引入了消息确认机制,

首先生产者准备一个消息,消息只要投递给 MQ 服务器,服务器收到以后,消息该怎么存怎么存,该投给哪投给哪,
所以 Broker 首先会将消息交给 Exhchange,再有 Exchange 送达给 Queue,所以整个发送消息的过程,牵扯到两个
为了保证消息的可靠送达,每个消息被成功, 我们引入了发送者的两个确认回调
第一个是确认回调,叫 confirmCallback,就是P端给B端 发送消息的过程,Broker 一旦收到了消息,就会回调我们的方法 confirmCallback,这是第一个回调时机,这个时机就可以知道哪些消息到达服务器了
但是服务器收到消息以后,要使用 Exchange 交换机,最终投递给 Queue,但是投递给队列这个过程可能也会失败,比如我们指定的路由键有问题,或者我们队列正在使用的过程中,被其它的一些客户端删除等操作,可能都会投递失败,投递失败就会调用 returnCallback
当然,这两种回调都是针对的发送端
同样的,消费端,只要消息安安稳稳的存到了消息队列,接下来就由我们消费端进行消费了,但是消费端引用消费,会引入 ack 机制(消息确认机制)
这个机制能保证, 让 Broker 知道哪些消息都被消费者正确的拿到了,如果消费者正确接到,这个消息就要从队列里面删除,如果没有正确接到,可能就需要重新投递消息
整个可靠抵达,分为两端处理,第一种是发送端的两种确认模式,第二个是消费端的 ack机制
spring:
rabbitmq:
publisher-confirms: true # 开启发送端确认
Broker 未将消息成功投递给 Queue 触发的回调
spring:
rabbitmq:
publisher-returns: true # 开启发送端消息抵达队列的确认
template:
mandatory: true # 只要消息抵达了队列,以异步发送优先回调这个returnconfirm
保证每个消息被正确消费,此时broker才可以删除这个消息
消费端默认是自动确认的,只要消息接收到,客户端会自动确认,服务端就会移除这个消息
queue无消费者,消息依然会被存储,直到消费者消费
消费端收到很多消息,自动回复给服务器ack,只有一个消息处理成功,消费端突然宕机了,结果MQ中剩下的消息全部丢失了
消费端如果无法确定此消息是否被处理完成,可以手动确认消息,即处理一个确认一个,未确认的消息不会被删除
只要我们没有明确告诉MQ收到消息。没有 Ack,消息就一直是 Unacked 状态,即使 consumer 宕机,消息也不会丢失,会重新变为 Ready,等待下次有新的 Consumer 连接进来时,再发给新的 Consumer
消费者获取到消息,成功处理,可以回复 Ack 给 Broker
ack() 用于肯定确认;broker 将移除此消息nack() 用于否定确认;可以指定 broker 是否丢弃此消息,可以批量reject() 用于否定确认;同上,但不能批量消息如果一直没有调用ack()的话,则会一直处于 Unacked 状态,这些 Unacked 状态的消息,都不会被丢弃,如果客户端宕机,等服务端感知到消费端宕机了,它就会将这个消息改为 Ready 状态,Ready 状态的消息,全部都会被重新投递

结合消费端与发送端的消息确认机制,就能保证消息一定发出去,也能一定让别人接收到,即使没接收到,也可以重新发送,最终达到消息百分百不丢失!



 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 