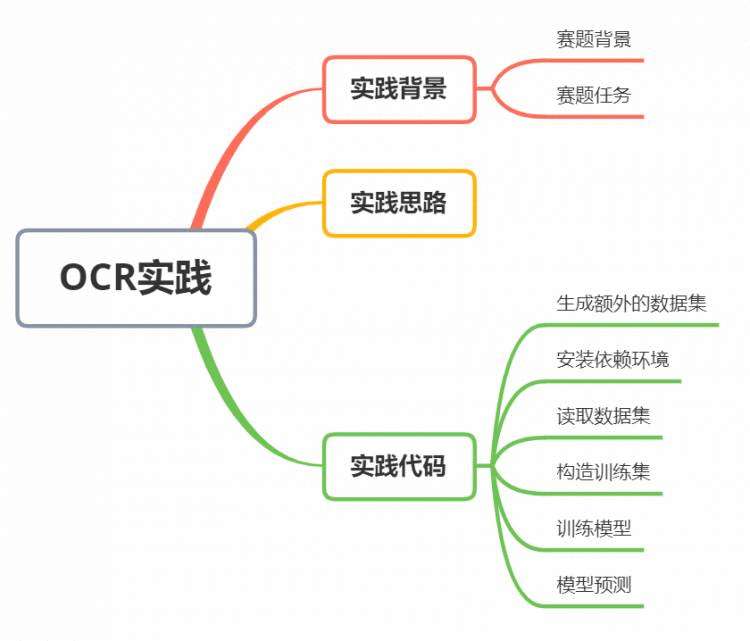
在完成数据预处理,数据加载与模型的组建后,你就可以进行模型的训练与预测了。飞桨框架提供了两种训练与预测的方法,一种是用paddle.Model对模型进行封装,通过高层API如Model.fit()、Model.evaluate()、Model.predict()等完成模型的训练与预测;另一种就是基于基础API常规的训练方式。
高层API实现的模型训练与预测如Model.fit()、Model.evaluate()、Model.predict()都可以通过基础API实现,本文先介绍高层API的训练方式,然后会将高层API拆解为基础API的方式,方便对比学习。
在封装模型前,需要先完成数据的加载与模型的组建,由于这一部分高层API与基础API通用,所以都可用下面的代码实现:
import paddle
from paddle.vision.transforms import ToTensor
# 加载数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
# 定义网络结构
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(1, -1),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
通过上述的代码,你就完成了训练集与测试集的构建,并创建了一个 mnist的网络模型。下面分别用两种方式完成模型的训练与预测。
你可以使用paddle.Model完成模型的封装,将网络结构组合成一个可快速使用高层API进行训练和预测的对象。代码如下:
model = paddle.Model(mnist)
import paddle
from paddle.vision.transforms import ToTensor
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
lenet = paddle.vision.models.LeNet()
# Mnist继承paddle.nn.Layer属于Net,model包含了训练功能
model = paddle.Model(lenet)
# 设置训练模型所需的optimizer, loss, metric
model.prepare(
paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy()
)
# 启动训练
model.fit(train_dataset, epochs=2, batch_size=64, log_freq=200)
# 启动评估
model.evaluate(test_dataset, log_freq=20, batch_size=64)
用paddle.Model完成模型的封装后,在训练前,需要对模型进行配置,通过Model.prepare接口来对训练进行提前的配置准备工作,包括设置模型优化器,Loss计算方法,精度计算方法等。
# 为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
做好模型训练的前期准备工作后,调用fit()接口来启动训练过程,需要指定至少3个关键参数:训练数据集,训练轮次和单次训练数据批次大小。
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(train_dataset,
epochs=5,
batch_size=64,
verbose=1)
对于训练好的模型进行评估可以使用evaluate接口,事先定义好用于评估使用的数据集后,直接调用evaluate接口即可完成模型评估操作,结束后根据在prepare中loss和metric的定义来进行相关评估结果计算返回。
返回格式是一个字典: * 只包含loss,{'loss': xxx} * 包含loss和一个评估指标,{'loss': xxx, 'metric name': xxx} * 包含loss和多个评估指标,{'loss': xxx, 'metric name1': xxx, 'metric name2': xxx}
# 用 evaluate 在测试集上对模型进行验证
eval_result = model.evaluate(test_dataset, verbose=1)
高层API中提供了predict接口来方便用户对训练好的模型进行预测验证,只需要基于训练好的模型将需要进行预测测试的数据放到接口中进行计算即可,接口会将经过模型计算得到的预测结果进行返回。
返回格式是一个list,元素数目对应模型的输出数目: * 模型是单一输出:[(numpy_ndarray_1, numpy_ndarray_2, …, numpy_ndarray_n)] * 模型是多输出:[(numpy_ndarray_1, numpy_ndarray_2, …, numpy_ndarray_n), (numpy_ndarray_1, numpy_ndarray_2, …, numpy_ndarray_n), …]
numpy_ndarray_n是对应原始数据经过模型计算后得到的预测数据,数目对应预测数据集的数目。
# 用 predict 在测试集上对模型进行测试
test_result = model.predict(test_dataset)
除了通过第一部分的高层API实现模型的训练与预测,飞桨框架也同样支持通过基础API对模型进行训练与预测。简单来说,Model.prepare()、Model.fit()、Model.evaluate()、Model.predict()都是由基础API封装而来。下面通过拆解高层API到基础API的方式,来了解如何用基础API完成模型的训练与预测。
import paddle
from paddle.vision.transforms import ToTensor
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
lenet = paddle.vision.models.LeNet()
loss_fn = paddle.nn.CrossEntropyLoss()
# 加载训练集 batch_size 设为 64
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
def train():
epochs = 2
adam = paddle.optimizer.Adam(learning_rate=0.001, parameters=lenet.parameters())
# 用Adam作为优化函数
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
predicts = lenet(x_data)
acc = paddle.metric.accuracy(predicts, y_data)
loss = loss_fn(predicts, y_data)
loss.backward()
if batch_id % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
adam.step()
adam.clear_grad()
# 启动训练
train()
飞桨框架通过基础API对模型进行训练与预测,对应第一部分的Model.prepare()与Model.fit():
# dataset与mnist的定义与第一部分内容一致
# 用 DataLoader 实现数据加载
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
mnist.train()
# 设置迭代次数
epochs = 5
# 设置优化器
optim = paddle.optimizer.Adam(parameters=mnist.parameters())
# 设置损失函数
loss_fn = paddle.nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0] # 训练数据
y_data = data[1] # 训练数据标签
predicts = mnist(x_data) # 预测结果
# 计算损失 等价于 prepare 中loss的设置
loss = loss_fn(predicts, y_data)
# 计算准确率 等价于 prepare 中metrics的设置
acc = paddle.metric.accuracy(predicts, y_data)
# 下面的反向传播、打印训练信息、更新参数、梯度清零都被封装到 Model.fit() 中
# 反向传播
loss.backward()
if (batch_id+1) % 900 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id+1, loss.numpy(), acc.numpy()))
# 更新参数
optim.step()
# 梯度清零
optim.clear_grad()
result:
epoch: 0, batch_id: 900, loss is: [0.29550618], acc is: [0.90625]
epoch: 1, batch_id: 900, loss is: [0.05875912], acc is: [0.984375]
epoch: 2, batch_id: 900, loss is: [0.05824642], acc is: [0.96875]
epoch: 3, batch_id: 900, loss is: [0.02940615], acc is: [1.]
epoch: 4, batch_id: 900, loss is: [0.05713747], acc is: [0.984375]
飞桨框架通过基础API对模型进行验证,对应第一部分的Model.evaluate():
# 加载测试数据集
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, drop_last=True)
loss_fn = paddle.nn.CrossEntropyLoss()
mnist.eval()
for batch_id, data in enumerate(test_loader()):
x_data = data[0] # 测试数据
y_data = data[1] # 测试数据标签
predicts = mnist(x_data) # 预测结果
# 计算损失与精度
loss = loss_fn(predicts, y_data)
acc = paddle.metric.accuracy(predicts, y_data)
# 打印信息
if (batch_id+1) % 30 == 0:
print("batch_id: {}, loss is: {}, acc is: {}".format(batch_id+1, loss.numpy(), acc.numpy()))
result:
batch_id: 30, loss is: [0.15860887], acc is: [0.953125]
batch_id: 60, loss is: [0.21005578], acc is: [0.921875]
batch_id: 90, loss is: [0.0889321], acc is: [0.953125]
batch_id: 120, loss is: [0.00115552], acc is: [1.]
batch_id: 150, loss is: [0.12016675], acc is: [0.984375]
飞桨框架通过基础API对模型进行测试,对应第一部分的Model.predict():
# 加载测试数据集
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, drop_last=True)
mnist.eval()
for batch_id, data in enumerate(test_loader()):
x_data = data[0]
predicts = mnist(x_data)
# 获取预测结果
print("predict finished")
飞桨框架2.0增加paddle.distributed.spawn函数来启动单机多卡训练,同时原有的paddle.distributed.launch的方式依然保留。
当调用paddle.Model高层API来实现训练时,想要启动单机多卡训练非常简单,代码不需要做任何修改,只需要在启动时增加一下参数-m paddle.distributed.launch。
# 单机单卡启动,默认使用第0号卡 不需要指定GPU运行,自动放到GPU ? 数据+模型 不用设置CUDA?
$ python train.py
# 单机多卡启动,默认使用当前可见的所有卡
$ python -m paddle.distributed.launch train.py
# 单机多卡启动,设置当前使用的第0号和第1号卡
$ python -m paddle.distributed.launch --gpus='0,1' train.py
# 单机多卡启动,设置当前使用第0号和第1号卡
$ export CUDA_VISIBLE_DEVICES=0,1
$ python -m paddle.distributed.launch train.py
如果使用基础API实现训练,想要启动单机多卡训练,需要对单机单卡的代码进行3处修改,具体如下:
import paddle
# 第1处改动 导入分布式训练所需的包
import paddle.distributed as dist
# 加载数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train')
test_dataset = paddle.vision.datasets.MNIST(mode='test')
# 定义网络结构
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(1, -1),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
# 第2处改动,初始化并行环境
dist.init_parallel_env()
# 用 DataLoader 实现数据加载
train_loader = paddle.io.DataLoader(train_dataset, batch_size=32, shuffle=True)
# 第3处改动,增加paddle.DataParallel封装
mnist = paddle.DataParallel(mnist)
mnist.train()
# 设置迭代次数
epochs = 5
# 设置优化器
optim = paddle.optimizer.Adam(parameters=model.parameters())
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0] # 训练数据
y_data = data[1] # 训练数据标签
predicts = mnist(x_data) # 预测结果
# 计算损失 等价于 prepare 中loss的设置
loss = paddle.nn.functional.cross_entropy(predicts, y_data)
# 计算准确率 等价于 prepare 中metrics的设置
acc = paddle.metric.accuracy(predicts, y_data)
# 下面的反向传播、打印训练信息、更新参数、梯度清零都被封装到 Model.fit() 中
# 反向传播
loss.backward()
if (batch_id+1) % 1800 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
# 更新参数
optim.step()
# 梯度清零
optim.clear_grad()
修改完后保存文件,然后使用跟高层API相同的启动方式即可。 注意: 单卡训练不支持调用init_parallel_env,请使用以下几种方式进行分布式训练。
# 单机多卡启动,默认使用当前可见的所有卡
$ python -m paddle.distributed.launch train.py
# 单机多卡启动,设置当前使用的第0号和第1号卡
$ python -m paddle.distributed.launch --gpus '0,1' train.py
# 单机多卡启动,设置当前使用第0号和第1号卡
$ export CUDA_VISIBLE_DEVICES=0,1
$ python -m paddle.distributed.launch train.py
launch方式启动训练,以文件为单位启动多进程,需要用户在启动时调用paddle.distributed.launch,对于进程的管理要求较高。飞桨框架2.0版本增加了spawn启动方式,可以更好地控制进程,在日志打印、训练退出时更友好。使用示例如下:
from __future__ import print_function
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
import paddle.distributed as dist
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear1 = nn.Linear(10, 10)
self._linear2 = nn.Linear(10, 1)
def forward(self, x):
return self._linear2(self._linear1(x))
def train(print_result=False):
# 1. 初始化并行训练环境
dist.init_parallel_env()
# 2. 创建并行训练 Layer 和 Optimizer
layer = LinearNet()
dp_layer = paddle.DataParallel(layer)
loss_fn = nn.MSELoss()
adam = opt.Adam(
learning_rate=0.001, parameters=dp_layer.parameters())
# 3. 运行网络
inputs = paddle.randn([10, 10], 'float32')
outputs = dp_layer(inputs)
labels = paddle.randn([10, 1], 'float32')
loss = loss_fn(outputs, labels)
if print_result is True:
print("loss:", loss.numpy())
loss.backward()
adam.step()
adam.clear_grad()
# 使用方式1:仅传入训练函数
# 适用场景:训练函数不需要任何参数,并且需要使用所有当前可见的GPU设备并行训练
if __name__ == '__main__':
dist.spawn(train)
# 使用方式2:传入训练函数和参数
# 适用场景:训练函数需要一些参数,并且需要使用所有当前可见的GPU设备并行训练
if __name__ == '__main__':
dist.spawn(train, args=(True,))
# 使用方式3:传入训练函数、参数并指定并行进程数
# 适用场景:训练函数需要一些参数,并且仅需要使用部分可见的GPU设备并行训练,例如:
# 当前机器有8张GPU卡 {0,1,2,3,4,5,6,7},此时会使用前两张卡 {0,1};
# 或者当前机器通过配置环境变量 CUDA_VISIBLE_DEVICES=4,5,6,7,仅使4张
# GPU卡可见,此时会使用可见的前两张卡 {4,5}
if __name__ == '__main__':
dist.spawn(train, args=(True,), nprocs=2)
# 使用方式4:传入训练函数、参数、指定进程数并指定当前使用的卡号
# 使用场景:训练函数需要一些参数,并且仅需要使用部分可见的GPU设备并行训练,但是
# 可能由于权限问题,无权配置当前机器的环境变量,例如:当前机器有8张GPU卡
# {0,1,2,3,4,5,6,7},但你无权配置CUDA_VISIBLE_DEVICES,此时可以通过
# 指定参数 gpus 选择希望使用的卡,例如 gpus='4,5',
# 可以指定使用第4号卡和第5号卡
if __name__ == '__main__':
dist.spawn(train, nprocs=2, gpus='4,5')





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有