一、数据仓库概念
数据仓库(Data Warehouse)
是为企业所有决策制定过程,提供所有系统数据支持的战略集合。

二、项目需求及架构设计
2.1 项目需求分析
1、项目需求
1)用户行为数据采集平台搭建
2)业务数据采集平台搭建
3)数据仓库维度建模
4)分析:用户、流量、会员、商品、销售、地区、活动等电商核心主题,统计的报表指标近100。
5)采用即席查询工具,随时进行指标分析
6)对集群性能进行监控,发生异常需要报警
7)元数据管理
8)质量监控
2.2 项目框架
2.2.1 技术选型
技术选型主要需要考虑的因素:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算
数据采集传输:Flume、Kafka、Sqoop、Logstash、DataX、
数据存储:Mysql、HDFS、HBase、Redis、MongoDB
数据计算:Hive、Tez、Spark、Flink、Storm
数据查询:Presto、Druid、Impala、Kylin
数据可视化:Echarts、Superset、QuickBI、DataV
任务调度:Azkaban、Oozie
集群监控:Zabbix
元数据管理:Atlas
数据质量监控:Griffin
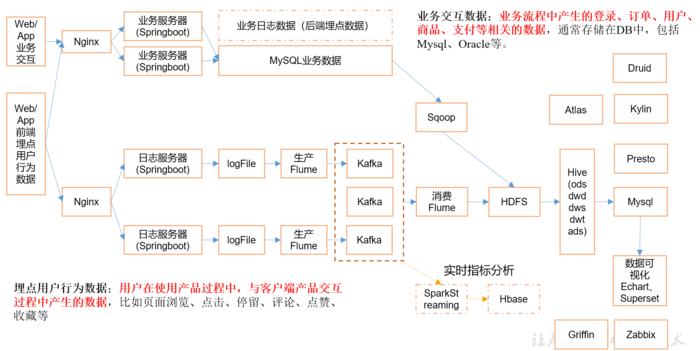
2.2.2 系统数据流程设计
2.2.3 框架版本选型

2.2.4 服务器选型
服务器是选择物理机还是云主机?
1)物理机:
128G内存,20核物理CPU,40线程,8THDD和2TSSD硬盘,戴尔品牌单台报价4万出头。一般物理机寿命5年左右。
2)云主机:
以阿里云为例,和上面大致相同配置,每年5万。
2.2.5 集群资源规划设计
1、集群规模
1)如何确认集群规模?(按每台服务器8T磁盘,128G内存)
(1)按每天日活跃用户100万,每人一天平均100条:100万*100条 = 1亿条
(2)每条日志1K左右,每天1亿条:100000000 / 1024 /1024 = 约100G
(3)半年内不扩容服务器来算:100G * 180 天 = 约18T
(4)保存3个副本:18T * 3 = 54T
(5)预留20%~30%Buffer=54T/0.7=77T
(6)需要约8T*10台服务器
2)如果要考虑数仓分层?数据采用压缩?需要重新计算
2、集群服务器规划
|
服务名称 |
子服务 |
服务器 hadoop102 |
服务器 hadoop103 |
服务器 hadoop104 |
|
HDFS |
NameNode |
√ |
|
|
|
DataNode |
√ |
√ |
√ |
|
|
SecondaryNameNode |
|
|
√ |
|
|
Yarn |
NodeManager |
√ |
√ |
√ |
|
Resourcemanager |
|
√ |
|
|
|
Zookeeper |
Zookeeper Server |
√ |
√ |
√ |
|
Flume(采集日志) |
Flume |
√ |
√ |
|
|
Kafka |
Kafka |
√ |
√ |
√ |
|
Flume(消费Kafka) |
Flume |
|
|
√ |
|
Hive |
Hive |
√ |
|
|
|
MySQL |
MySQL |
√ |
|
|
|
Sqoop |
Sqoop |
√ |
|
|
|
Presto |
Coordinator |
√ |
|
|
|
Worker |
|
√ |
√ |
|
|
Azkaban |
AzkabanWebServer |
√ |
|
|
|
AzkabanExecutorServer |
√ |
|
|
|
|
Druid |
Druid |
√ |
√ |
√ |
|
Kylin |
|
√ |
|
|
|
Hbase |
HMaster |
√ |
|
|
|
HRegionServer |
√ |
√ |
√ |
|
|
Superset |
|
√ |
|
|
|
Atlas |
|
√ |
|
|
|
Solr |
Jar |
√ |
|
|
|
Griffin |
|
√ |
|
|
|
服务数总计 |
|
19 |
9 |
9 |
三、数据生成模块
3.1 埋点数据基本格式
公共字段:基本所有安卓手机都包含的字段
业务字段:埋点上报的字段,有具体的业务类型
下面就是一个示例,表示业务字段的上传。
{
"ap":"xxxxx",//项目数据来源 app pc
"cm": { //公共字段
"mid": "", // (String) 设备唯一标识
"uid": "", // (String) 用户标识
"vc": "1", // (String) versionCode,程序版本号
"vn": "1.0", // (String) versionName,程序版本名
"l": "zh", // (String) language系统语言
"sr": "", // (String) 渠道号,应用从哪个渠道来的。
"os": "7.1.1", // (String) Android系统版本
"ar": "CN", // (String) area区域
"md": "BBB100-1", // (String) model手机型号
"ba": "blackberry", // (String) brand手机品牌
"sv": "V2.2.1", // (String) sdkVersion
"g": "", // (String) gmail
"hw": "1620x1080", // (String) heightXwidth,屏幕宽高
"t": "1506047606608", // (String) 客户端日志产生时的时间
"nw": "WIFI", // (String) 网络模式
"ln": 0, // (double) lng经度
"la": 0 // (double) lat 纬度
},
"et": [ //事件
{
"ett": "1506047605364", //客户端事件产生时间
"en": "display", //事件名称
"kv": { //事件结果,以key-value形式自行定义
"goodsid": "236",
"action": "1",
"extend1": "1",
"place": "2",
"category": "75"
}
}
]
}
示例日志(服务器时间戳 | 日志):
1540934156385|{
"ap": "gmall",
"cm": {
"uid": "1234",
"vc": "2",
"vn": "1.0",
"la": "EN",
"sr": "",
"os": "7.1.1",
"ar": "CN",
"md": "BBB100-1",
"ba": "blackberry",
"sv": "V2.2.1",
"g": "abc@gmail.com",
"hw": "1620x1080",
"t": "1506047606608",
"nw": "WIFI",
"ln": 0
},
"et": [
{
"ett": "1506047605364", //客户端事件产生时间
"en": "display", //事件名称
"kv": { //事件结果,以key-value形式自行定义
"goodsid": "236",
"action": "1",
"extend1": "1",
"place": "2",
"category": "75"
}
},{
"ett": "1552352626835",
"en": "active_background",
"kv": {
"active_source": "1"
}
}
]
}
}
下面是各个埋点日志格式。其中商品点击属于信息流的范畴
3.2 事件日志数
3.2.1 商品列表页(loading)
事件名称:loading
|
标签 |
含义 |
|
action |
动作:开始加载=1,加载成功=2,加载失败=3 |
|
loading_time |
加载时长:计算下拉开始到接口返回数据的时间,(开始加载报0,加载成功或加载失败才上报时间) |
|
loading_way |
加载类型:1-读取缓存,2-从接口拉新数据 |
|
extend1 |
扩展字段 Extend1 |
|
extend2 |
扩展字段 Extend2 |
|
type |
加载类型:自动加载=1,用户下拽加载=2,底部加载=3(底部条触发点击底部提示条/点击返回顶部加载) |
|
type1 |
加载失败码:把加载失败状态码报回来(报空为加载成功,没有失败) |
3.2.2 商品点击(display)
事件标签:display
|
标签 |
含义 |
|
|
action |
动作:曝光商品=1,点击商品=2, |
|
|
goodsid |
商品ID(服务端下发的ID) |
|
|
place |
顺序(第几条商品,第一条为0,第二条为1,如此类推) |
|
|
extend1 |
曝光类型:1 - 首次曝光 2-重复曝光 |
|
|
category |
分类ID(服务端定义的分类ID) |
|
3.2.3 商品详情页(newsdetail)
事件标签:newsdetail
|
标签 |
含义 |
|
|
entry |
页面入口来源:应用首页=1、push=2、详情页 推荐阅读
| |








 京公网安备 11010802041100号
京公网安备 11010802041100号