点上面“东哥IT笔记”,关注并星标
每天一篇业界最新技术分享
在前面几篇文章中,我们已经介绍了总体构架,客户端管理和查询管理。在查询管理中,有一个很重要的部分我们没有介绍,那就是查询优化,这也是本文所要介绍的内容。
所有的现代数据库都是基于cost进行优化的(Cost Based Optimization, CBO)。总体的思想就是看每一个操作的cost是多少,然后找出一个cost最小的路径来执行这些操作并获取结果。
本文会首先以最常的三种join为例来进行介绍,看看哪怕是简单的join,它背后的优化是如何进行工作的。在这些例子中,我们关注时间复杂度,这个其实和真实的数据库优化器的计算是有所不同的,它真实会关注CPU消耗,磁盘I/O消耗以及内存的需求。时间复杂度和CPU消耗其实是差不多的,我们这种懒人就直接使用时间复杂度来进行分析了。当然有时候我们还需要考虑磁盘的I/O消耗,因为很多时候真正的瓶颈就是在于磁盘I/O而不是CPU的使用率。
JOIN的操作
我们会来看三个最常见的join操作,merger Join, Hash Join以及Nested Loop Join。在正式开始之前,我们来引入两个名词,outer relation和inner relation,很简单outer relation就是join左边的数据集,inner relation就是join右边的数据集。比如A JOIN B, 我们把A称之为outer relation而B称之为inner relation。并且假设outer relation有N个元素,inner relation有M个元素。我们可以很容易知道A JOIN B和B JOIN A其实是不太相同的。
Nested loop join
Nested loop join是最简单的一种情况
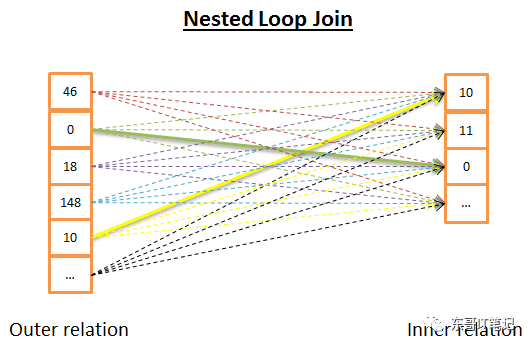
它的思想是,对每一个在outer ralation中的行,都去看是否在inner relation中存在。要是从伪码的角度来看,它是这样实现的:
nested_loop_join(arrayouter, array inner) for each row a in outer for each row b in inner if (match_join_condition(a,b)) write_result_in_output(a,b) end if end for end for
其实说白了就是全遍历的循环,所以时间复杂度是O(N*M)。
从磁盘I/O的角度来看,对每一个在outer relation中的行(N),都需要从inner relation中读出M行。所以就需要从磁盘读取N + N*M次。但是假如inner relation的行比较少,我们就不需要每次都从磁盘中读取,而是可以把它保存在memory中,这种情况下磁盘的读取就会少很多,只需要N+M次。所以,这种情况下,我们希望N的大小足够小,这样就可以使用memory来保存而不需要每次都进行磁盘的读取。
当然了,假如inner relation能够有index,那么它读取的磁盘I/O的次数会更少。
那么假如inner relation的数据很大,不能够保存在memory中怎么办呢,是不是就一定要进行N+N*M次的磁盘读取呢?其实并不尽然,这里有一个常见的优化方法,就是每次都读一个bunch的行,然后把这些行放到memory中,让他们和outer relation先进行匹配,等他们做完了,在读下一个bunch,这样一来,最终磁盘I/O的访问就得到了优化。
下面是伪码的实现:
//improved version to reduce the disk I/O.nested_loop_join_v2(fileouter, file inner) for each bunch ba in outer // ba is now in memory for each bunch bb in inner // bb is now in memory for each row a in ba for each row b in bb if (match_join_condition(a,b)) write_result_in_output(a,b) end if end for end for end for end for
有了这种优化之后,时间复杂度还是一样的,但是磁盘I/O的访问次数就变成了 bunch的次数(outer)+bunch 次数(outer)*bunch次数(inner)。所以总得来说可以通过增加bunch的大小来减少bunch的次数,这样的磁盘I/O访问就会变小。
Hash Join
Hash join相比上面的nested loop join稍微复杂一点,但是它的cost在大多数情况下则会小很多。
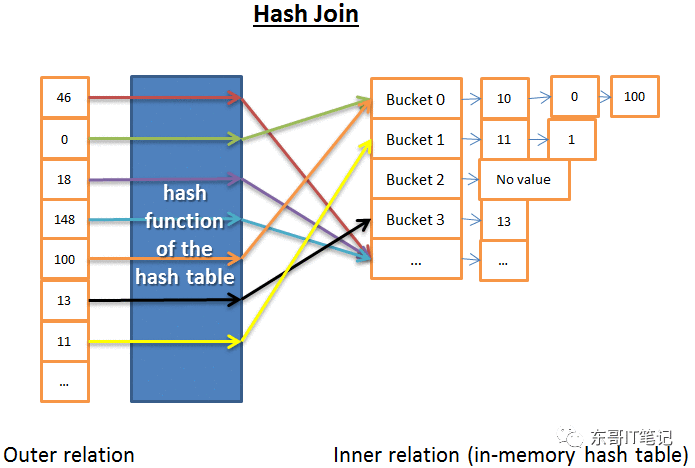
Hash Join的思想如下:
从inner relation中得到所有的元素
创建一个in memory的hash表
从outer realtion一个一个的得到元素
计算每一个的hash值,然后找到inner relation中对应的bucket
然后在bucket中查看是否有匹配的元素
在计算相关的时间复杂度之前,我们来做一些假设:
Inner relation被分成了X个bucket
Hash函数针对outer relation和inner relation都可以均匀分布,也就是说每一个bucket的大小差不多
在Bucket内部查找匹配的时候的消耗就是bucket的大小
所以时间复杂度就是 (M/X)*N + 创建hash表的cost + N*hash函数的cost。假如hash函数所创造的bucket的大小足够小,那么其实时间复杂度相当于O(M+N)。
另外还有一种hash join的算法,对内存来说很友好,但是磁盘I/O消耗则大一些:
为inner relation和outer relaition都创建hash表
把他们放到磁盘中
然后把两者通过一个bucket一个bucket地进行比较
Merge Join
Merge Join是唯一的会产生排好序的结果的Join。
Merge Join可以分成两步:
排序
使用merge sort(算法)进行排序是一个很好的选择,当然假如内存不是问题,我们还会有更好的方法。
只是有时候,很多时候其实已经都排好序了,比如:
Merge Join
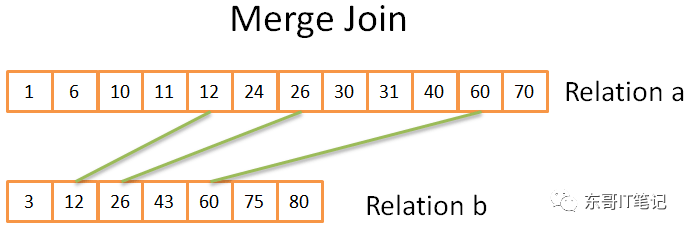
总得思想和merge sort是类似的,只是这里我们只选择两者相等的元素:
比较两个relation中的元素
假如相等,把他们放到result中,然后比较两者中的下一个元素
不相等,就比较小的relation中的下一个元素
重复上面步骤
这是一个很简单的示例,现实情况可能会比这个复杂一点,比如他们中间有多个相等的内容如何比较等等。不过我们就先来看看这个简单的情况。
先来看看时间复杂度,假如两个relation是都已经排序了,那么复杂度就是O(N+M)。假如两者都需要进行排序,那么复杂度就是 O(N*Log(N) +M*Log(M))
三种join的比较
毫无疑问,这三个join都有其使用的场景,没有哪一个是必然比另外两个好的(废话,否则为什么要三种),选择哪一种join其实取决于很多因素:
空闲memory的数量:假如没有足够的memory,显然没法使用hash join。
两个数据集的大小:比如你有一个很大的表和一个很小的表进行join,那么nested loop可能是一个比hash join更快的选择,因为你不需要花费时间去创建hash表。而假如你的两个表都很大,那么nested loop可能需要非常耗费CPU。
index:假如有B+ TREE的index,那么merge join可能是一个更好的选择
结果需要排序:假如你所需要的结果要求排序,那么可能选择merge join更好,因为你终归是要进行排序的。
假如relation已经排序了:这个没啥好说的,merge join是一个不错的选择。
join的类型:比如你使用的是相等join还是inner join, outer join或者self-join等等,这些都会影响最终的选择。
数据的分布:比如你想join名字中的姓,因为有很多重复的数据,那么你使用hash join可能就会遇到很多问题。
你是否想让多进程/线程执行join操作:这也会影响最终join类型的选择。
本文介绍了查询优化中两个表的join操作,我们了解了三种常见的join类型: nested loop join, merge join以及hash join,并把他们的原理和使用场景进行了解释。不过总得来说我们还是使用的最简单的两个表join来进行说明的,那么假如是多个表的join该如何处理呢,我们将会在下一篇文章中进行介绍。

 京公网安备 11010802041100号
京公网安备 11010802041100号