observer_cli是一个针对erlang虚拟机,基于recon实现的模仿werl的observer功能的工具。因为生产环境一般都是linux系统,而observer是不支持linux系统,有了observer_cli就可以在linux环境下更直观的观察环境,及早发现问题。以下是作者自己介绍:
Visualize Erlang/Elixir Nodes On The Command Line base on recon.
Provide a high-performance tool usable both in development and production settings.
Focus on important and detailed information about real-time running system.
Keep minimal consumption.
本文只会简单的介绍基础用法,着重点在如果编写一个自己的扩展插件,安装和使用部分参看作者写的内容更详尽
Git库地址
安装observer_cli支持rebar构建,如果你的项目支持rebar,只需要将observer加入到你的deps目录中
{deps, [{observer_cli, ".*",{git, https://github.com/zhongwencool/observer_cli.git, {branch, "master"}}}
]}.
作者用的rebar3,好像不需要填写项目地址这些?
如果用的rebar而不是rebar3,而且你的项目之前没有使用recon,那么还需要修改下项目本身的rebar.config
{deps, [{recon, ".*", {git, https://github.com/ferd/recon.git, {branch, "master"}}}
]}.
如果使用了recon那么只需要保证get-deps的时候recon在observer_cli check前get到即可
除了rebar构建,也支持erlang.mk的构建
另外Elixir也可以使用
这两种构建方式直接参照项目的ReadMe即可
使用
observer_cli:start().
来启动本地的observer_cli程序,可以填入一个时间作为刷新间隔,单位为毫秒,默认为1000
observer_cli不仅可以查看本地节点,也可以查看远程节点
observer_cli:start('test@127.0.0.1')
observer_cli:start('test@127.0.0.1', COOKIE).
observer_cli:start('test@127.0.0.1', [{COOKIE,COOKIE},{interval, 1000}]).
以上三种方式都可以启动,如果没有指定COOKIE的时候就需要自己保证当前node和目标node的COOKIE一致,当然远程调用的时候还是可以指定刷新间隔
本地节点和远程节点都必须将observer_cli的库加进来,自定义插件(后面会介绍)部分的环境变量设置部分必须在查看的节点上确保,而查看的目标节点必须能确实能完成自定义插件配置的功能,目标节点自定义插件的环境变量的设置不是必须的
主界面介绍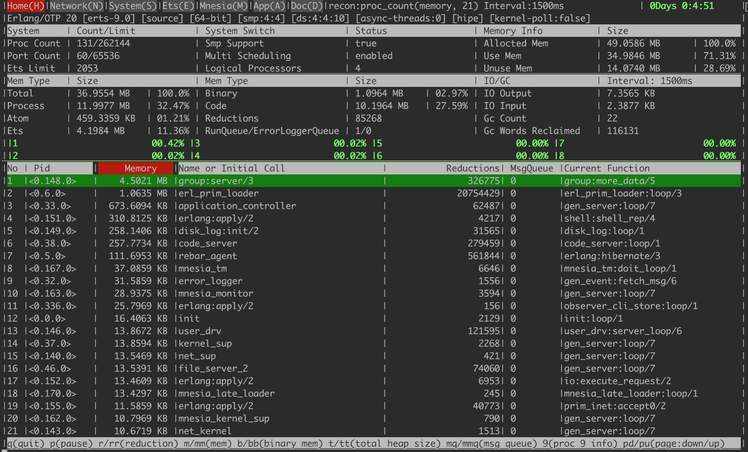
observer_cli提供的功能和observer非常像,而且依靠recon还完成了更细致的内存分配数据,例如内存的利用率等
标题依次为
关于内存和网络端口详细数据介绍可以查看recon,当然observer_cli也贴心的做了介绍observer_cli文档
最新版本的界面和上图有一丢丢的差距,最新的版本加入了自定义插件部分
主界面上展示的进程可以进入二级菜单针对单个进行进行详细的查看
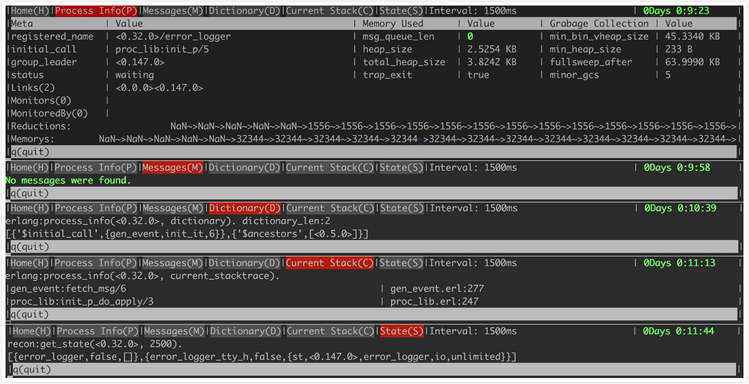
在Home页面输入当前进程的编号(最左边的数字)即可,进程较多时可以使用pu/pd进程翻页,刷新较快时使用p暂停页面操作
这里以Process界面举例,加入一个dump当前字典内容的命令,并在界面打印出dump文件所在目录,通过这个扩展也可以理解observer_cli实现的一些基础逻辑
Process界面主要由observer_cli_process模块进行管理,先看一下observer_cli_process模块的内容
start(Pid, Opts) ->#view_opts{process = #process{interval = RefreshMs}} = Opts,RenderPid = spawn_link(fun() ->?output(?CLEAR),render_worker(info, RefreshMs, Pid, ?INIT_TIME_REF, ?INIT_QUEUE, ?INIT_QUEUE)end),manager(RenderPid, Opts).manager(RenderPid, #view_opts{process = ProcOpts} = Opts) ->case parse_cmd(Opts, RenderPid) ofquit ->erlang:send(RenderPid, quit);{new_interval, NewInterval} ->erlang:send(RenderPid, {new_interval, NewInterval}),manager(RenderPid,Opts#view_opts{process = ProcOpts#process{interval = NewInterval}});ViewAction ->erlang:send(RenderPid, ViewAction),manager(RenderPid, Opts)end.render_worker(state, Interval, Pid, TimeRef, RedQ, MemQ) ->case render_state(Pid, Interval) ofok ->next_draw_view(state, TimeRef, Interval, Pid, RedQ, MemQ);error ->next_draw_view_2(state, TimeRef, Interval, Pid, RedQ, MemQ)end.
observer_cli_process本身是我们在选中了查看某一进程详细信息的时候触发并开始走创建流程,除了自己本身外会额外spawn一个进程用来管理控制台的显示
进程自己本身负责从命令行中读取命令解读后抓发给显示进程,同是还维护定时刷新逻辑和退出逻辑
负责绘制的进程根据当前绘制的选中的状态,会get数据然后输入到界面并进入下次循环,逻辑并不复杂
next_draw_view(Status, TimeRef, Interval, Pid, NewRedQ, NewMemQ) ->NewTimeRef = observer_cli_lib:next_redraw(TimeRef, Interval),next_draw_view_2(Status, NewTimeRef, Interval, Pid, NewRedQ, NewMemQ).next_draw_view_2(Status, TimeRef, Interval, Pid, NewRedQ, NewMemQ) ->receivequit ->quit;{new_interval, NewInterval} ->?output(?CLEAR),render_worker(Status, NewInterval, Pid, TimeRef, NewRedQ, NewMemQ);info_view ->?output(?CLEAR),render_worker(info, Interval, Pid, TimeRef, NewRedQ, NewMemQ);message_view ->?output(?CLEAR),render_worker(message, Interval, Pid, TimeRef, NewRedQ, NewMemQ);dict_view ->?output(?CLEAR),render_worker(dict, Interval, Pid, TimeRef, NewRedQ, NewMemQ);stack_view ->?output(?CLEAR),render_worker(stack, Interval, Pid, TimeRef, NewRedQ, NewMemQ);state_view ->?output(?CLEAR),render_worker(state, Interval, Pid, TimeRef, NewRedQ, NewMemQ);_Msg ->render_worker(Status, Interval, Pid, TimeRef, NewRedQ, NewMemQ)end.
next_draw_view和next_draw_view2的区别只有next_draw_view会额外根据当前的界面刷新时间给自己发送一个定时刷新消息而已,所以state的处理中,如果get失败了就直接进入next_draw_view2没必要再次循环刷新了
observer_cli_lib:next_redraw生成的消息最后会有_Msg分支catch住根据当前状态,完成当前界面的刷新
new_interval则是给全局的设置刷新间隔的API的handle,每个模块都会带
其他分支则就是具体的功能模块
现在我们开始给Process模块加入dump命令
render_last_line() ->observer_cli_lib:render_last_line("q(quit) dump(dump dict into file dict.txt)").
parse_cmd(ViewOpts, Pid) ->case observer_cli_lib:to_list(io:get_line("")) of"q\n" ->quit;"Q\n" ->quit;"P\n" ->info_view;"M\n" ->message_view;"D\n" ->dict_view;"C\n" ->stack_view;"S\n" ->state_view;"H\n" ->erlang:exit(Pid, stop),observer_cli:start(ViewOpts);"dump\n" ->{dump_dict,false}; //新加部分Number ->observer_cli_lib:parse_integer(Number)end.
这里我们在进入刷新逻辑的时候额外加了一个bool变量,因为dump是一个一次性的命令,不需要刷新,但是我们又要不能破坏刷新逻辑的同时,确保dump只执行一次,且能保持显示dump文件所在的目录
next_draw_view_2(Status, TimeRef, Interval, Pid, NewRedQ, NewMemQ) ->receivequit ->quit;{new_interval, NewInterval} ->?output(?CLEAR),render_worker(Status, NewInterval, Pid, TimeRef, NewRedQ, NewMemQ);info_view ->?output(?CLEAR),render_worker(info, Interval, Pid, TimeRef, NewRedQ, NewMemQ);message_view ->?output(?CLEAR),render_worker(message, Interval, Pid, TimeRef, NewRedQ, NewMemQ);dict_view ->?output(?CLEAR),render_worker(dict, Interval, Pid, TimeRef, NewRedQ, NewMemQ);stack_view ->?output(?CLEAR),render_worker(stack, Interval, Pid, TimeRef, NewRedQ, NewMemQ);state_view ->?output(?CLEAR),render_worker(state, Interval, Pid, TimeRef, NewRedQ, NewMemQ);{dump_dict, Done} ->?output(?CLEAR), //新加部分render_worker({dump_dict, Done}, Interval, Pid, TimeRef, NewRedQ, NewMemQ);_Msg ->render_worker(Status, Interval, Pid, TimeRef, NewRedQ, NewMemQ)end.render_worker({dump_dict, Done}, Interval, Pid, TimeRef, RedQ, MemQ) ->Menu = render_menu(dict, Interval),Line1 = "file:write_file(FileName,io_lib:format(p,[List]),[write]), ~n",LastLine = render_last_line(),{Done2, Line2} = case Done oftrue ->{ok, Pwd} = file:get_cwd(),{Done, io_lib:format("Dict write in ~s/~s ~n", [Pwd, "dict.txt"])};_ ->case dump_dict(Pid) ofundefined ->{undefined, "dict empty! ~n"};FileName ->{ok, Pwd} = file:get_cwd(),{true, io_lib:format("Dict write in ~s/~s ~n", [Pwd, FileName])}endend,?output([?CURSOR_TOP, Menu, Line1, Line2, LastLine]),next_draw_view({dump_dict, Done2}, TimeRef, Interval, Pid, RedQ, MemQ);dump_dict(Pid) ->case erlang:process_info(Pid, dictionary) of{dictionary, List} ->FileName = "dict.txt",file:write_file(FileName, io_lib:format("~p", [List]), [write]),FileName;undefined ->undefinedend.
render_worker 的内容并不算复杂,根据dump_dict命令带入的参数决定是否进行dump操作,如果是由dump_dict命令来完成指定Pid的dump操作,如果dump成功就返回true状态,如果已经是true就保持原状态
dump_dict写的很粗糙,如果要进生产环境记得包装
render_worker的结束我们直接进入下次dump_dict的循环,确保界面上显示的dump文件所在目录不会被定时刷新逻辑刷新成其他
现在启动来看下命令执行结果
主界面

执行后

执行结果

ok,看来成功了,至此我们就完成了对Process的一个简单的扩展
如果要做刷新逻辑那就更简单了只需要编写自己的render函数,确保每次刷新时get到最新的数据并返回即可
这些新的扩展功能必须要保证要查看的目标节点拥有这些逻辑,如果是用的远程节点查看,远程节点只需要有基础版本的observer_cli库即可
自定义插件使用这里先摘抄一段作者的使用介绍,原文已经介绍的很详尽了
- Configure observer_cli,tell observer_cli how to find your plugin.
- Write observer_cli_plugin behaviour.
主要内容在需要完成的3个回调,回调格式如下:
-callback kv_label() -> [Rows] whenRows :: #{key => string(), key_width => pos_integer(),value => string()|integer()|{byte, pos_integer()}, value_width => pos_integer()}.
要注意的原文这里还是用的name,作者的文档还没更新,使用key即可
这里定义的是类似System界面的那种键值对结构,如果不想使用可以直接返回一个空字符串,一般返回一个界面的总览
-callback sheet_header() -> [SheetHeader] whenSheetHeader :: #{title => string(), width => pos_integer(), shortcut => string()}.
这部分返回表头其中Shortcut指的是如果表格需要排序,指定快捷键后就可以根据当前列排序,还需要注意的是,关键词也会加入到title显示中,所有width设置的时候也需要考虑进去,当然还要考虑下面的数据的具体长度
-callback sheet_body() -> [SheetBody] whenSheetBody :: list().
表内容,主要注意和表头一一对应即可,value支持绝大多数的erlang数据类型,
如果要显示内存大小之类的字节大小,可以使用observer_cli_lib:to_byte函数,不过用了后排序就不准了。。。
要修复也可以实现,新包装一个数据结构,然后在observer_cli_plugin:render_sheet_body函数中将
DataSet = lists:map(fun(I) ->{0, lists:nth(SortRow, I), I} end,Module:sheet_body()),
在这里对I进行检查和特殊处理,如果是需要转变的数据直接转变
is_memory_type({memory,_}) -> true;
is_memory_type(_) -> false.render_sheet_body(Module, CurPage, Rows, SortRow, Widths) ->DataSet &#61; lists:map(fun(I) ->Value &#61; lists:nth(SortRow, I),I1 &#61; lists:map(fun(V) ->case is_memory_type(V) oftrue ->observer_cli_lib:to_byte(element(2, V));_ ->Vendend, I),case is_memory_type(Value) oftrue ->{0, element(2, Value), I1};_ ->{0, Value, I1}endend,Module:sheet_body()),SortData &#61; observer_cli_lib:sublist(DataSet, Rows, CurPage),[beginList &#61; mix_value_width(Item, Widths, []),?render(List)end || {_, _, Item} <- SortData].
这里可以细致点&#xff0c;包装一个observer_cli_memory结构然后include进来&#xff0c;然后配合宏使用
也就是目标节点主要提供这三个回调函数&#xff0c;然后配置到observer_cli 的application env
下就可以在插件界面使用&#xff0c;环境变量配置格式如下
%% module - Specific module implements plugin behavior. It&#39;s mandatory.
%% title - Menu title. It&#39;s mandatory.
%% shortcut - Switch plugin by shortcut. It&#39;s mandatory.
%% interval - Refresh interval ms. It&#39;s optional. default is 1500ms.
%% sort_column - Sort the sheet by this index. It&#39;s optional default is 2.{plugins,[#{module &#61;> observer_cli_plug_behaviour1, title &#61;> "XPlug",interval &#61;> 1500, shortcut &#61;> "X", sort_column &#61;> 3},#{module &#61;> observer_cli_plug_behaviour2, title &#61;> "YPlug",interval &#61;> 1600, shortcut &#61;> "Y", sort_column &#61;> 3}]
}
一般来说我们不会直接修改deps目录的内容&#xff0c;所以可以在你的项目启动的时候&#xff0c;额外配置一个appenv文件&#xff0c;针对observer_cli的application增加plugins变量即可&#xff0c;最好不要直接修改deps下的app文件&#xff0c;需要注意的是这个设置部分是调用发起的节点必须有&#xff0c;也就是界面显示所在的节点&#xff0c;也就是说如果用的远程节点查看&#xff0c;则查看用的这个节点必须有这些环境变量才行&#xff0c;而布标节点必提供配置中模块指定的回调
下面我们加入一个查看当前服务器玩家进程的自定义插件为例介绍这个功能
在项目内建立observer_cli_role模块&#xff0c;名字可以随意指定
kv_label() ->[[#{key &#61;> "online_role", key_width &#61;> 20,value &#61;> user_default:n(), value_width &#61;> 10}]].sheet_header() ->[#{title &#61;> "RoleID", width &#61;> 15},#{title &#61;> "RoleName", width &#61;> 20},#{title &#61;> "level", width &#61;> 10, shortcut &#61;> "Lv"},#{title &#61;> "VipLv", width &#61;> 10, shortcut &#61;> "VLv"},#{title &#61;> "FID", width &#61;> 15},#{title &#61;> "FamilyName", width &#61;> 20},#{title &#61;> "Pid", width &#61;> 15},#{title &#61;> "Memory", width &#61;> 20, shortcut &#61;> "Me"},#{title &#61;> "Reductions", width &#61;> 24, shortcut &#61;> "Re"},#{title &#61;> "MsgQL", width &#61;> 10, shortcut &#61;> "Mq"}].
sheet_body() ->[beginPid &#61; user_default:rs_pid(RoleID),RolePublic &#61; user_default:get_role_public(RoleID),[RoleID,maps:get(rolename, RolePublic),maps:get(rolelv, RolePublic),maps:get(viplv, RolePublic),maps:get(familyid, RolePublic),maps:get(familyname, RolePublic),Pid,{memory,(element(2, erlang:process_info(Pid, memory)))},element(2, erlang:process_info(Pid, reductions)),element(2, erlang:process_info(Pid, message_queue_len))]end || RoleID <- user_default:onlines()].
这里面用了一些user_default模块假设存在的功能。这些功能不是非要在user_default模块提供&#xff0c;调用自己项目的内容即可&#xff0c;注意内存那格&#xff0c;使用了前面说的{memory, Memory}格式&#xff0c;如果没有修改过排序显示部分最好直接显示数字本身&#xff0c;否则会报错&#xff0c;启动后切换到自定义插件下&#xff0c;效果如图

设定了快捷键的列就可以使用快捷键进行排序&#xff0c;修改后&#xff0c;内存显示修改后的方式&#xff0c;排序也不会有问题。
ok&#xff0c;现在可以模仿写一个你自己的插件了&#xff0c;如果自写插件部分有错误&#xff0c;会在目标节点那边抛出异常&#xff0c;会由项目本身的日志逻辑catch住方便调试。










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 