cuDF(https://github.com/rapidsai/cudf)是一个基于Python的GPU DataFrame库,用于处理数据,包括加载、连接、聚合和过滤数据。向GPU的转移允许大规模的加速,因为GPU比CPU拥有更多的内核。
笔者觉得,对于我来说一个比较好的使用场景是,代替并行 ,在pandas处理比较慢的时候,切换到cuDF,就不用写繁琐的并行了。
官方文档:
相关参考:
nvidia-rapids︱cuDF与pandas一样的DataFrame库
文章目录 1 cuDF背景与安装 2 一些demo 2.1 新建dataframe 2.2 pandas 与 cuDF切换 2.3 选中某行列 2.4 apply_rows和apply_chunks 2.5 groupby
1 cuDF背景与安装 1.1 背景 cuDF在过去一年中的发展速度非常之快。每个版本都加入了令人兴奋的新功能、优化和错误修复。0.10版本也不例外。cuDF 0.10版本的一些新功能包括 groupby.quantile()、Series.isin()、从远程/云文件系统(例如hdfs、gcs、s3)读取、Series和DataFrame isna()、按分组功能中的任意长度Series分组 、Series 协方差和Pearson相关性以及从DataFrame / Series .values 属性返回 CuPy数组。此外,apply UDF函数API经过了优化,并且加入了通过.iloc访问器的收集和散播方法。
除了提供所有上述出色的功能、优化和错误修复之外,cuDF 0.10版本还花费大量的精力构建未来。该版本将cuStrings存储库合并到cuDF中,并为合并两个代码库做好了准备,使字符串功能能够被更紧密地集成到cuDF中,以此提供更快的加速和更多的功能。此外,RAPIDS添加了cuStreamz元数据包,因此可以使用cuDF和Streamz库简化GPU加速流处理。cuDF继续改进其Pandas API兼容性和Dask DataFrame互操作性,使我们的用户可以最大程度地无缝使用cuDF。
在幕后,libcudf的内部架构正在经历一次重大的重新设计。0.10版本加入了最新的cudf :: column和cudf :: table类,这些类大大提高了内存所有权控制的强健性,并为将来支持可变大小数据类型(包括字符串列、数组和结构)奠定了基础。由于已构建对整个libcudf API中的新类的支持,这项工作将在下一个版本周期中继续进行。此外,libcudf 0.10添加了许多新的API和算法,包括基于排序、支持空数据的分组功能、分组功能分位数和中位数、cudf :: unique_count,cudf :: repeat、cudf :: scatter_to_tables等。与以往一样,此版本还包括许多其他改进和修复。
RAPIDS内存管理器库RMM也正在进行一系列重组。这次重组包括一个基于内存资源的新架构,该架构与C ++ 17 std :: pmr :: memory_resource大多兼容。这使该库更容易在公共接口之后添加新类型的内存分配器。0.10还用Cython取代了CFFI Python绑定,从而使C ++异常可以传播到Python异常,使更多可调整的错误被传递给应用程序。下一个版本将继续提高RMM中的异常支持。
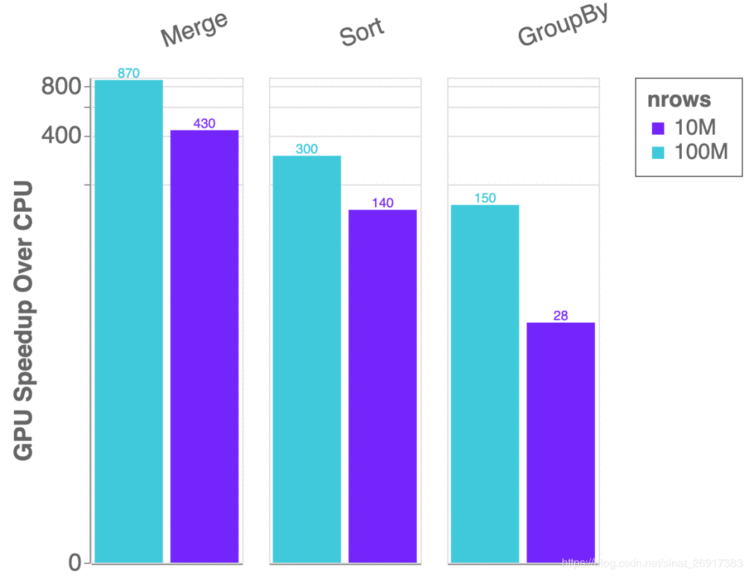
最后,你会注意到cuDF在这个版本中速度有了显著提升,包括join(最多11倍)、gather和scatter on tables(速度也快2-3倍)的大幅性能改进,以及更多如图5所示的内容。
1.2 安装 有conda可以直接安装,也可以使用docker,参考:https://github.com/rapidsai/cudf
conda版本,cudf version == 0.10
- c rapidsai - c nvidia - c numba - c conda- forge \cudf= 0.10 python= 3.6 cudatoolkit= 9.2 - c rapidsai - c nvidia - c numba - c conda- forge \cudf= 0.10 python= 3.6 cudatoolkit= 10.0 - c rapidsai - c nvidia - c numba - c conda- forge \cudf= 0.10 python= 3.6 cudatoolkit= 10.1
docker版本,可参考:https://rapids.ai/start.html#prerequisites
docker pull rapidsai/ rapidsai: cuda10. 1 - runtime- ubuntu16. 04 - py3. 7 - - gpus all - - rm - it - p 8888 : 8888 - p 8787 : 8787 - p 8786 : 8786 \rapidsai/ rapidsai: cuda10. 1 - runtime- ubuntu16. 04 - py3. 7
2 一些demo 2.1 新建dataframe import cudfimport numpy as npfrom datetime import datetime, timedeltat0 = datetime. strptime( '2018-10-07 12:00:00' , '%Y-%m-%d %H:%M:%S' ) = 5 = cudf. DataFrame( { 'id' : np. arange( n) , 'datetimes' : np. array( [ ( t0+ timedelta( seconds= x) ) for x in range ( n) ] ) } )
Build DataFrame via list of rows as tuples:
>> > import cudf>> > df = cudf. DataFrame( [ ( 5 , "cats" , "jump" , np. nan) , ( 2 , "dogs" , "dig" , 7.5 ) , ( 3 , "cows" , "moo" , - 2.1 , "occasionally" ) , ] ) >> > df0 1 2 3 4 0 5 cats jump null None 1 2 dogs dig 7.5 None 2 3 cows moo - 2.1 occasionally
2.2 pandas 与 cuDF切换 pandas到 cuDF
>>> import pandas as pd
cuDF 到pandas
>> > import cudf>> > gdf = cudf. DataFrame( { 'a' : [ 1 , 2 , None ] , 'b' : [ 3 , None , 5 ] } ) >> > gdf. fillna( 4 ) . to_pandas( ) 0 1 3 1 2 4 2 4 5 >> > gdf. fillna( { 'a' : 3 , 'b' : 4 } ) . to_pandas( ) 0 1 3 1 2 4 2 3 5
2.3 选中某行列 df = cudf. DataFrame( { 'a' : list ( range ( 20 ) ) , 'b' : list ( range ( 20 ) ) , 'c' : list ( range ( 20 ) ) } )
df. iloc[ 1 ] a 1 1 1 : 1 , dtype: int64
2.4 apply_rows和apply_chunks apply_rows
import cudfimport numpy as npfrom numba import cudadf = cudf. DataFrame( ) [ 'in1' ] = np. arange( 1000 , dtype= np. float64) def kernel ( in1, out) : for i, x in enumerate ( in1) : print ( 'tid:' , cuda. threadIdx. x, 'bid:' , cuda. blockIdx. x, 'array size:' , in1. size, 'block threads:' , cuda. blockDim. x) out[ i] = x * 2.0 outdf = df. apply_rows( kernel, incols= [ 'in1' ] , outcols= dict ( out= np. float64) , kwargs= dict ( ) ) print ( outdf[ 'in1' ] . sum ( ) * 2.0 ) print ( outdf[ 'out' ] . sum ( ) ) >> > 999000.0 >> > 999000.0
apply_chunks
import cudf
2.5 groupby from cudf import DataFrame= DataFrame( ) [ 'key' ] = [ 0 , 0 , 1 , 1 , 2 , 2 , 2 ] [ 'val' ] = [ 0 , 1 , 2 , 3 , 4 , 5 , 6 ] = df. groupby( [ 'key' ] , method= 'cudf' ) def mult ( df) : df[ 'out' ] = df[ 'key' ] * df[ 'val' ] return dfresult = groups. apply ( mult) print ( result)
输出:
key val out
之后,用到的时候再追加。。













 京公网安备 11010802041100号
京公网安备 11010802041100号