在数据库系统中,既有存放数据的文件,也有存放日志的文件。日志在内存中也是有缓存Log buffer,也有磁盘文件log file,本文主要描述存放日志的文件。
MySQL中的日志文件,有这么两类常常讨论到:undo日志与redo日志。
1 undo
1.1 undo是啥
undo日志用于存放数据修改被修改前的值,假设修改 tba 表中 id=2的行数据,把Name=’B’ 修改为Name = ‘B2’ ,那么undo日志就会用来存放Name=’B’的记录,如果这个修改出现异常,可以使用undo日志来实现回滚操作,保证事务的一致性。
对数据的变更操作,主要来自 INSERT UPDATE DELETE,而UNDO LOG中分为两种类型,一种是 INSERT_UNDO(INSERT操作),记录插入的唯一键值;一种是 UPDATE_UNDO(包含UPDATE及DELETE操作),记录修改的唯一键值以及old column记录。
1.2 undo参数
MySQL跟undo有关的参数设置有这些:
1 mysql> show global variables like '%undo%';2 +--------------------------+------------+3 | Variable_name | Value |4 +--------------------------+------------+5 | innodb_max_undo_log_size | 1073741824 |6 | innodb_undo_directory | ./ |7 | innodb_undo_log_truncate | OFF |8 | innodb_undo_logs | 128 |9 | innodb_undo_tablespaces | 3 |
10 +--------------------------+------------+
11
12 mysql> show global variables like '%truncate%';
13 +--------------------------------------+-------+
14 | Variable_name | Value |
15 +--------------------------------------+-------+
16 | innodb_purge_rseg_truncate_frequency | 128 |
17 | innodb_undo_log_truncate | OFF |
18 +--------------------------------------+-------+
控制最大undo tablespace文件的大小,当启动了innodb_undo_log_truncate 时,undo tablespace 超过innodb_max_undo_log_size 阀值时才会去尝试truncate。该值默认大小为1G,truncate后的大小默认为10M。
设置undo独立表空间个数,范围为0-128, 默认为0,0表示表示不开启独立undo表空间 且 undo日志存储在ibdata文件中。该参数只能在最开始初始化MySQL实例的时候指定,如果实例已创建,这个参数是不能变动的,如果在数据库配置文 件 .cnf 中指定innodb_undo_tablespaces 的个数大于实例创建时的指定个数,则会启动失败,提示该参数设置有误。
2 redo
2.1 redo是啥
当数据库对数据做修改的时候,需要把数据页从磁盘读到buffer pool中,然后在buffer pool中进行修改,那么这个时候buffer pool中的数据页就与磁盘上的数据页内容不一致,称buffer pool的数据页为dirty page 脏数据,如果这个时候发生非正常的DB服务重启,那么这些数据还没在内存,并没有同步到磁盘文件中(注意,同步到磁盘文件是个随机IO),也就是会发生数据丢失,如果这个时候,能够在有一个文件,当buffer pool 中的data page变更结束后,把相应修改记录记录到这个文件(注意,记录日志是顺序IO),那么当DB服务发生crash的情况,恢复DB的时候,也可以根据这个文件的记录内容,重新应用到磁盘文件,数据保持一致。
这个文件就是redo log ,用于记录 数据修改后的记录,顺序记录。它可以带来这些好处:
- 当buffer pool中的dirty page 还没有刷新到磁盘的时候,发生crash,启动服务后,可通过redo log 找到需要重新刷新到磁盘文件的记录;
- buffer pool中的数据直接flush到disk file,是一个随机IO,效率较差,而把buffer pool中的数据记录到redo log,是一个顺序IO,可以提高事务提交的速度;
假设修改 tba 表中 id=2的行数据,把Name=’B’ 修改为Name = ‘B2’ ,那么redo日志就会用来存放Name=’B2’的记录,如果这个修改在flush 到磁盘文件时出现异常,可以使用redo log实现重做操作,保证事务的持久性。
这里注意下redo log 跟binary log 的区别,redo log 是存储引擎层产生的,而binary log是数据库层产生的。假设一个大事务,对tba做10万行的记录插入,在这个过程中,一直不断的往redo log顺序记录,而binary log不会记录,知道这个事务提交,才会一次写入到binary log文件中。binary log的记录格式有3种:row,statement跟mixed,不同格式记录形式不一样。
2.2 redo 参数
- innodb_log_files_in_group
redo log 文件的个数,命名方式如:ib_logfile0,iblogfile1… iblogfilen。默认2个,最大100个。
文件设置大小,默认值为 48M,最大值为512G,注意最大值指的是整个 redo log系列文件之和,即(innodb_log_files_in_group * innodb_log_file_size )不能大于最大值512G。
- innodb_log_group_home_dir
文件存放路径
Redo Log 缓存区,默认8M,可设置1-8M。延迟事务日志写入磁盘,把redo log 放到该缓冲区,然后根据 innodb_flush_log_at_trx_commit参数的设置,再把日志从buffer 中flush 到磁盘中。
-
innodb_flush_log_at_trx_commit
-
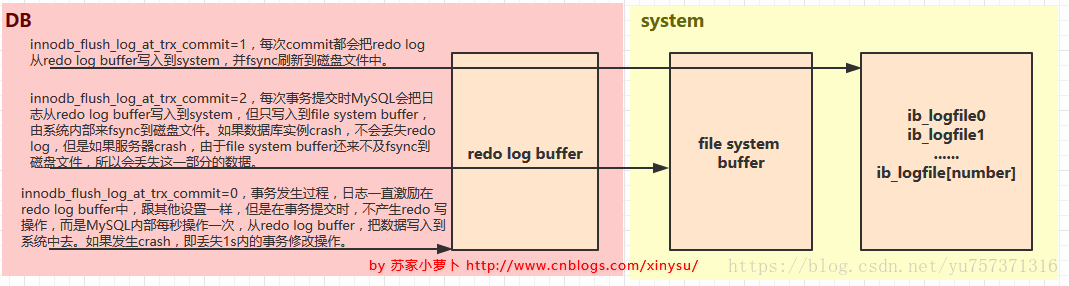
innodb_flush_log_at_trx_commit=1,每次commit都会把redo log从redo log buffer写入到system,并fsync刷新到磁盘文件中。
- innodb_flush_log_at_trx_commit=2,每次事务提交时MySQL会把日志从redo log buffer写入到system,但只写入到file system buffer,由系统内部来fsync到磁盘文件。如果数据库实例crash,不会丢失redo log,但是如果服务器crash,由于file system buffer还来不及fsync到磁盘文件,所以会丢失这一部分的数据。
-
innodb_flush_log_at_trx_commit=0,事务发生过程,日志一直激励在redo log buffer中,跟其他设置一样,但是在事务提交时,不产生redo 写操作,而是MySQL内部每秒操作一次,从redo log buffer,把数据写入到系统中去。如果发生crash,即丢失1s内的事务修改操作。
-
注意:由于进程调度策略问题,这个“每秒执行一次 flush(刷到磁盘)操作”并不是保证100%的“每秒”。
-
2.3 redo 空间管理
实际上redo log有两部分组成:redo log buffer 跟redo log file。buffer pool中把数据修改情况记录到redo log buffer,出现以下情况,再把redo log刷下到redo log file:
Redo log buffer空间不足
事务提交(依赖innodb_flush_log_at_trx_commit参数设置)
后台线程
做checkpoint
实例shutdown
binlog切换
3.1 Undo + Redo事务的简化过程
假设有A、B两个数据,值分别为1,2,开始一个事务,事务的操作内容为:把1修改为3,2修改为4,那么实际的记录如下(简化):
A.事务开始.
B.记录A=1到undo log.
C.修改A=3.
D.记录A=3到redo log.
E.记录B=2到undo log.
F.修改B=4.
G.记录B=4到redo log.
H.将redo log写入磁盘。
I.事务提交






 京公网安备 11010802041100号
京公网安备 11010802041100号