mysql nosql
MySQL是更好的NoSQL。 在考虑NoSQL用例(例如键/值存储)时,MySQL在性能,易用性和稳定性方面更具意义。 MySQL是一个可靠的引擎,具有许多在线资料,从操作和故障案例到复制和不同的使用模式,不一而足。 因此,与未经测试的新型NoSQL引擎相比,它具有优势。
近年来,NoSQL引擎已成为主流。 许多开发人员将NoSQL引擎(例如MongoDB,Cassandra,Redis或Hadoop)视为构建应用程序的首选,认为它们是弃用旧SQL引擎的单个产品系列。
选择使用NoSQL数据库通常是基于炒作,或者是错误的假设,即关系数据库不能像NoSQL数据库那样好执行。 在选择数据库时,工程师通常会忽略运营成本以及其他稳定性和成熟度方面的问题。 有关不同NoSQL(和SQL)引擎的局限性和缺点的更多信息,请参阅Aphyr的Jepsen系列文章。
这篇文章将解释为什么我们发现将MySQL用于键/值用例比大多数专用NoSQL引擎要好,并提供了以这种方式使用MySQL时应遵循的指南。
Wix网站解析
当某人单击指向Wix站点的链接时,他的浏览器会将HTTP请求发送到具有站点地址的Wix服务器。 无论地址是指向具有自定义域的Wix高级站点(例如domain.com )还是位于Wix域的子域上的免费站点(例如user.wix.com/site ), 都会发生这种情况 。 该服务器必须通过执行站点的键/值查找URL来从站点地址解析请求的站点。 我们将URL表示为以下讨论的途径。
路由表用于将站点地址解析为站点对象。 因为站点可能会暴露在多条路线上,所以这种关系是多对一的。 找到该站点后,应用程序将加载该站点以供使用。 站点对象本身具有复杂的结构,其中包括两个子对象列表-站点使用的不同服务。 这是我们的对象的示例模型,假设使用标准SQL数据库和规范化架构:
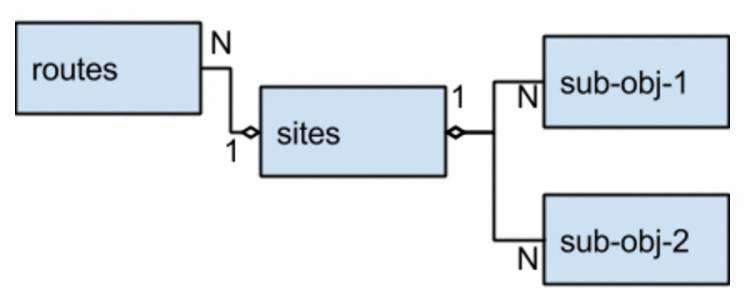
当使用传统的标准化模型更新站点时,我们需要使用事务来更新多个表,以确保我们保持数据的一致性。 (请注意,事务正在使用DB级锁,以防止从受影响的表中进行并发写入,有时甚至是从受影响的表中读取。)继续使用此模型,我们可能在每个表中都有一个串行键,外键和一个索引。路由表中的URL字段。
但是,标准化的模式化建模方式存在许多问题:
- 锁限制了对表的访问,因此在高吞吐量的用例中,它可能会限制我们的性能。
- 读取对象涉及一些SQL查询(在这种情况下为4)或联接-再次涉及延迟。
- 串行密钥强加了锁定,并再次限制了写入吞吐量。
这些问题构成了我们可以从MySQL(或任何其他SQL引擎)获得的吞吐量和并发性的限制。 由于这些缺点,以及用例实际上是关键/价值这一事实,因此许多开发人员选择寻找提供更好的吞吐量和并发性的NoSQL解决方案,即使是以稳定性,一致性或可用性为代价。
在Wix,我们发现,与具有标准化数据模型(如上述模型)MySQL和大多数NoSQL引擎相比,将MySQL创造性地用作键/值存储时,可以做得更好。 只需将MySQL用作NoSQL引擎即可。 我们现有的系统具有可伸缩性/吞吐量/并发性/延迟数字,这对于任何NoSQL引擎而言都是令人印象深刻的。 这是我们的一些数据:
- 跨三个数据中心的主动-主动-主动设置。
- 吞吐量约为200,000 RPM。
- 路由表的数量级为100,000,000个记录,存储空间为10GB。
- 站点表的数量级为1亿条记录,200 GB的存储空间。
- 读取延迟平均为1.0-1.5毫秒(实际上,一个数据中心为0.2-0.3毫秒)。
请注意,对于大多数关键/价值引擎(包括开源和基于云的引擎)而言,大约1.0毫秒的延迟被认为是令人印象深刻的! 我们使用MySQL(被认为是基本SQL引擎)实现了这一点。
这是我们正在使用的实际架构:

CREATE TABLE `routes` (`route` varchar(255) NOT NULL,`site_id` varchar(50) NOT NULL,`last_update_date` bigint NOT NULL,PRIMARY KEY (`key`),KEY (`site_id`)
)CREATE TABLE `sites` (`site_id` varchar(50) NOT NULL,`owner_id` varchar(50) NOT NULL,`schema_version` varchar(10) NOT NULL DEFAULT '1.0',`site_data` text NOT NULL,`last_update_date` bigint NOT NULL,PRIMARY KEY (`site_id`)
) /*ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=16*/;
任何未在查询中用作条件的字段都被折叠到单个Blob字段(site_data文本字段)中。 这包括子obj表以及对象表本身上的任何字段。 还要注意,我们没有使用串行密钥。 取而代之的是,我们使用varchar(50),它存储客户端生成的GUID值-在下一节中将详细介绍。
下面是我们正在使用的查询,它具有高吞吐量和低延迟:
select * from sites where site_id = (select site_id from routes where route = ?
)
它的工作方式是首先通过唯一索引对路由表执行查询,该索引仅返回一个结果。 然后,我们通过主键查找站点,再次查找一条记录。 嵌套查询语法确保我们仅对数据库执行一次往返操作以运行两个SQL查询。
上面显示的结果是,在高流量和高更新率的情况下,平均性能约为1毫秒。 即使不使用事务,更新也是半事务的。 这是因为我们在一个插入语句中输入了完整的站点,并且在我们输入路由之前,它不会在查询中找到。 因此,如果我们先进入站点,然后进入路线,即使在站点表中可能有孤立数据的极端情况下,也要确保我们具有一致的状态。
将MySQL用作NoSQL引擎的准则
利用从上面的示例(以及Wix的其他此类案例)获得的经验,我们制定了一些简短的准则来将MySQL用作NoSQL引擎。
将MySQL用作NoSQL引擎时,要记住的主要事情是避免使用数据库锁或复杂的查询。
- 不要使用会引入锁的事务。 而是使用应用交易。
- 不要使用串行键。 串行密钥引入了锁定并使主动-主动配置复杂化。
- 使用客户端生成的唯一密钥。 我们使用GUID。
在设计要针对读取进行优化的架构时,请遵循以下其他准则:
- 不规范。
- 仅存在要建立索引的字段。 如果索引不需要字段,则将其存储在一个Blob /文本字段中(例如JSON或XML)。
- 不要使用外键。
- 设计架构以启用读取查询中的一行。
- 不要执行表alter命令。 表alter命令引入了锁定和停机时间。 相反,请使用实时迁移。
查询数据时:
- 通过主键或索引查询记录。
- 不要使用联接。
- 不要使用聚合。
- 在副本而不是主数据库上运行内务查询(BI,数据浏览等)。
我们打算撰写另一篇博客文章,其中包含有关实时迁移和应用交易的更多信息。
摘要
这篇文章最重要的一点是,允许您以不同的方式思考。 将MySQL用作NoSQL引擎真是太好了,这不是它设计的工作方式。 如本文所演示的,此示例使用MySQL而不是为键/值访问而构建的专用NoSQL引擎。 在Wix上,MySQL是键/值案例(以及其他案例)的首选引擎,因为它易于使用和操作,并且是一个很棒的生态系统。 而且,它提供的延迟,吞吐量和并发度指标可以与大多数NoSQL引擎相匹配(甚至超过)。
翻译自: https://www.javacodegeeks.com/2015/12/scaling-100m-mysql-better-nosql.html
mysql nosql





 京公网安备 11010802041100号
京公网安备 11010802041100号