mysql5.6 innlDB 在CHAR、VARCHAR、TEXT类型的列上可以定义全文索引,但因为无法中文分词所以对中文的支持很差,但从MySQL5.7开始,MySQL内置了ngram全文检索插件,用来支持中文分词,并且对MyISAM和InnoDB引擎有效。
在没法升级5.7的情况下,5.6有变通的办法,就是将整句的中文拆分成单个汉字,并按urlencode、区位码、base64、拼音等进行编码使之以"字母+数字"的方式存储于数据库中。转换完达到如下的效果:
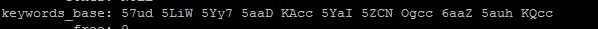
存储的是将汉字编码后的结果,用空格连起来,这样就可以使用5.6的全文索引来进行搜索,注意的是要将搜索的内容也先同样编码再进行搜索。
下面给出一种基于base64的汉字变换方式
/**
* 关键词整理函数(用作mysql的全文索引制作的搜索)
* 1.将字符串全角转半角、去空格、大写转小写、分成单个字符并base64编码、最后用空格连接类,方便mysql索引,做搜索关键字
* 2.将数字转全角做索引区分标识,全角数字为标识专用
**/
function keywords($str){//全角转半角
$str = strtr($str,[‘1‘ => ‘1‘,‘2‘ => ‘2‘,‘3‘ => ‘3‘,‘4‘ => ‘4‘,‘5‘ => ‘5‘,‘6‘ => ‘6‘,‘7‘ => ‘7‘,‘8‘ => ‘8‘,‘9‘ => ‘9‘,‘0‘ => ‘0‘,
‘A‘ => ‘A‘,‘B‘ => ‘B‘,‘C‘ => ‘C‘,‘D‘ => ‘D‘,‘E‘ => ‘E‘,‘F‘ => ‘F‘,‘G‘ => ‘G‘,‘H‘ => ‘H‘,‘I‘ => ‘I‘,‘J‘ => ‘J‘,‘K‘ => ‘K‘,‘L‘ => ‘L‘,‘M‘ => ‘M‘,‘N‘ => ‘N‘,‘O‘ => ‘O‘,‘P‘ => ‘P‘,‘Q‘ => ‘Q‘,‘R‘ => ‘R‘,‘S‘ => ‘S‘,‘T‘ => ‘T‘,‘U‘ => ‘U‘,‘V‘ => ‘V‘,‘W‘ => ‘W‘,‘X‘ => ‘X‘,‘Y‘ => ‘Y‘,‘Z‘ => ‘Z‘,
‘a‘ => ‘a‘,‘b‘ => ‘b‘,‘c‘ => ‘c‘,‘d‘ => ‘d‘,‘e‘ => ‘e‘,‘f‘ => ‘f‘,‘g‘ => ‘g‘,‘h‘ => ‘h‘,‘i‘ => ‘i‘,‘j‘ => ‘j‘,‘k‘ => ‘k‘,‘l‘ => ‘l‘,‘m‘ => ‘m‘,‘n‘ => ‘n‘,‘o‘ => ‘o‘,‘p‘ => ‘p‘,‘q‘ => ‘q‘,‘r‘ => ‘r‘,‘s‘ => ‘s‘,‘t‘ => ‘t‘,‘u‘ => ‘u‘,‘v‘ => ‘v‘,‘w‘ => ‘w‘,‘x‘ => ‘x‘,‘y‘ => ‘y‘,‘z‘ => ‘z‘,
‘~‘ => ‘~‘,‘`‘ => ‘`‘,‘!‘ => ‘!‘,‘@‘ => ‘@‘,‘#‘ => ‘#‘,‘$‘ => ‘$‘,‘%‘ => ‘%‘,‘^‘ => ‘^‘,‘&‘ => ‘&‘,‘*‘ => ‘*‘,‘(‘ => ‘(‘,‘)‘ => ‘)‘,‘_‘ => ‘_‘,‘-‘ => ‘-‘,‘+‘ => ‘+‘,‘=‘ => ‘=‘,
‘{‘ => ‘{‘,‘}‘ => ‘}‘,‘[‘ => ‘[‘,‘]‘ => ‘]‘,‘|‘ => ‘|‘,‘\‘ => ‘\\‘,‘:‘ => ‘:‘,‘;‘ => ‘;‘,‘"‘ => ‘"‘,‘'‘ => ‘\‘‘,
‘<‘ => ‘ ‘,‘,‘>‘ => ‘>‘,‘.‘ => ‘.‘,‘?‘ => ‘?‘,‘/‘ => ‘/‘,‘ ‘ => ‘ ‘]);//去空格
$str = str_replace(‘ ‘,‘‘,$str);//大写转小写
$str = strtolower($str);//数字统一格式为阿拉伯数字
$str = strtr($str,[‘零‘ => 0,‘一‘ => 1,‘二‘ => 2,‘三‘ => 3,‘四‘ => 4,‘五‘ => 5,‘六‘ => 6,‘七‘ => 7,‘八‘ => 8,‘九‘ => 9]);//分成单个字符并base64编码
$str_len = strlen($str);//获取关键字集合
$arr &#61;[];$str_len &#61; mb_strlen($str);for($i &#61; 0;$i <$str_len;&#43;&#43; $i){$keyword &#61; strtr(base64_encode(mb_substr($str,$i,1)),‘&#43;/&#61;‘,‘abc‘);if(!in_array($keyword,$arr)){ //去除重复的关键字
$arr[] &#61; $keyword;
}
}return $arr;
}
例如将字符串 ‘小明小红是朋友‘ 输入改函数&#xff0c;返回的结果是数组如下
array(6) {
[0]&#61;>
string(4) "5bCP"[1]&#61;>
string(4) "5piO"[2]&#61;>
string(4) "57qi"[3]&#61;>
string(4) "5piv"[4]&#61;>
string(4) "5pyL"[5]&#61;>
string(4) "5YaL"}
分别对应相应的汉字&#xff0c;注意小明和小红都有小这个字&#xff0c;所以去掉重复的字&#xff0c;只有六个编码。
然后用空格将数组连起来
$keywords &#61; implode(‘ ‘,keywords($keyword));
将$keywords 存入数据库。
进阶&#xff1a;
如果匹配的关键词包含一些常用的字&#xff0c;会出现大量的结果。
例如搜索书名 霸道总裁&#xff0c;可能会出现&#xff0c;裁缝&#xff0c;总经理&#xff0c;这样的结果
全文搜索是按照相关度从高到底返回的结果&#xff0c;可以只去去前面一些相关度较高的结果。
或者先查询出相关度最高是多少(相关度是一个数值)&#xff0c;然后除以二&#xff0c;限定结果的相关度都大于这个最大相关度的一半。
参考
//通过最大相关度/2过滤一部分无关结果//查询出最大相关度是多少
$score &#61; $this->sql(‘xs.nh‘)->query(‘SELECT MATCH(keywords_base) AGAINST (?) AS score FROM nh ORDER BY score DESC LIMIT 1‘,[$keywords]);//构造查询语句
$this->where[‘MATCH(keywords_base) AGAINST‘] &#61; [$keywords,‘> ‘.$score[0][‘score‘] / 2];
![BUUCTF [ZJCTF 2019] NiZhuanSiWei 解题报告](https://img6.php1.cn/3cdc5/c45f/1c8/3b2568bcc38297e4.jpeg)



 京公网安备 11010802041100号
京公网安备 11010802041100号