
我们用JDBC 等连接MySQL 其实就是,jdbc是客户端来连接MySQL服务器。
Mysql服务器中负责对表中数据的读取和写入工作的部分是存储引擎,支持的存储引擎就是倒数第二行的innobd、memory、myisam等。
存储引擎的上一层是 处理数据的, 下一层是真的文件系统。
InnoDB
我们要讲的是innodb,它是将表中的数据存储到磁盘上的存储引擎。
InnoDB存储引擎不需要一条一条的把记录从磁盘上读出来,InnoDB采取的方式是:
将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,
InnoDB中页的大小一般为 16 KB
也就是说,当需要从磁盘中读数据时每一次最少将从磁盘中读取16KB的内容到内存中,每一次最少也会把内存中的16KB内容写到磁盘中
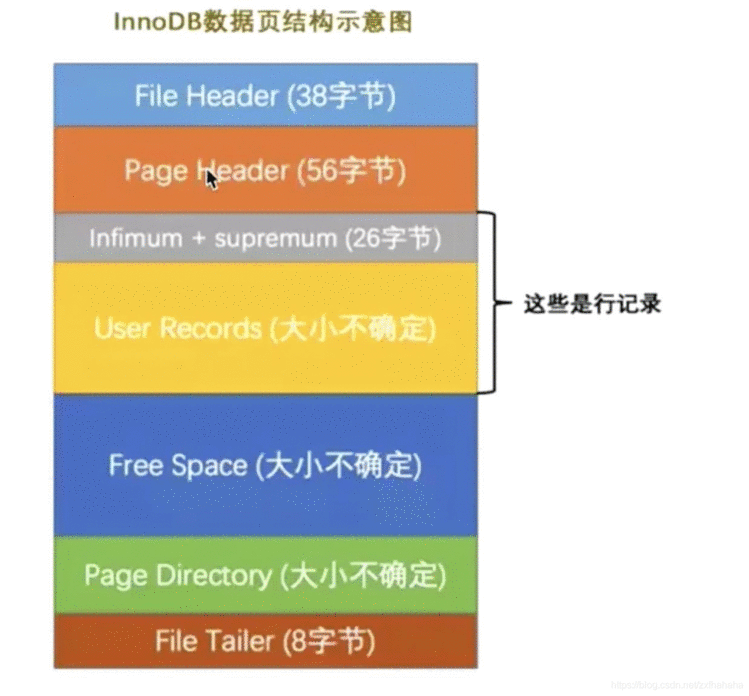
InnoDB数据页结构
每次InnoDB拿的页即数据页,为16kb,这16kb大小的存储空间可以被划分为多个部分,示意图如下:
名称
中文名
占用空间
简单描述
File Header
文件头部
38字节
页的一些通用信息
Page Header
页面头部
56字节
数据页专有的一些信息
Infimum + Supremum
最小记录和最大记录
26字节
两个虚拟的行记录
User Records
用户记录
不确定
实际存储的行记录内容
Free Space
空闲空间
不确定
页中尚未使用的空间
Page Directory
页面目录
不确定
页中的某些记录的相对位置
File Trailer
文件尾部
8字节
校验页是否完整
InnoDB 行格式
我们平时是以记录为单位向表中插入数据的,这些记录在磁盘上的存放方式被称为行格式。
行格式分别是Compact、Redundant、Dynamic和Compressed行格式
Compact
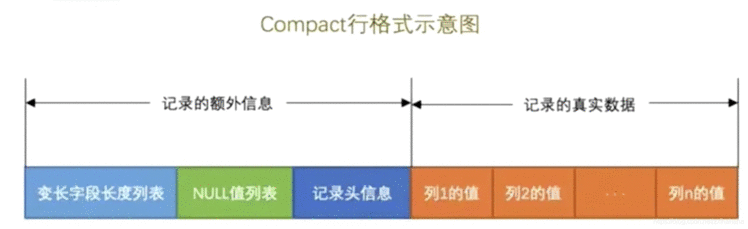
记录的真实数据:
记录的真实数据除了我们自己定义的列的数据外,还加了隐藏列:
列名
是否必须
占用空间
描述
row_id
否
6字节
行id,唯一标识一条记录
transaction_id
是
6字节
事务id
roll_pointer
是
7字节
回滚指针
InnoDB对主键的生成策略
优先使用用户自定义主键作为主键,如果没定义,则选取一个unique键作为主键,如果没有定义unique键,则会为表默认添加一个row_id 作为主键.
行溢出
一页只能存16kb, 而一个varchar的类型的列最多就可以存65533个字节,这样就会造成一页存不了一条记录.
在Compact和Reduntant格式中, 记录真实数据数据处只会存储该列的一部分数据,把剩余的数据分散存储在其他几个页中,记录指向这些页的地址.
行格式除了记录真实数据外,还会记录额外信息:
变长字段长度列表
比如我们有varchar[varchar是可变长度的,所以占用空间不确定] ,这里就会记录这个varchar对应的真实的长度
NULL值列表
把这行数据里是null的都记录下来. 具体就是将每个允许存储null的列对应一个二进制位,二进制位位1时,代表该列的值位null.
记录头信息
记录头信息用于描述记录,由固定的5个字节组成,即40个二进制位,不同的位代表不同的意思:

Dynamic和Compressed
Dynamic和Compressed类似于行格式, 只是处理行溢出不同,他们不会在记录的真实数据处存储一部分数据,而是把所有的数据都存储到其他页面,只有在记录的真实数据处存储其他页面的地址.
Compressed行格式会采用压缩算法对页面进行压缩.
索引
B+ 树
我们把数据按下面的格式存,每个页面都按照索引列的值建立了页目录.
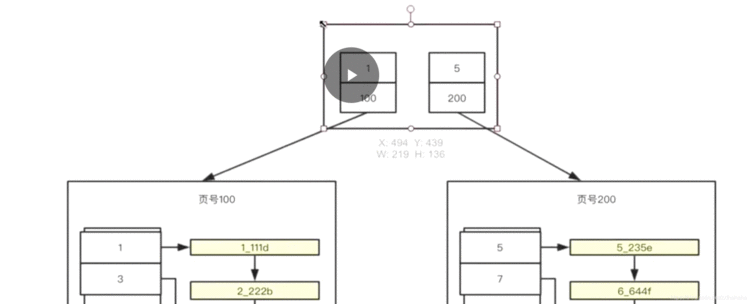
其实就是B+树:
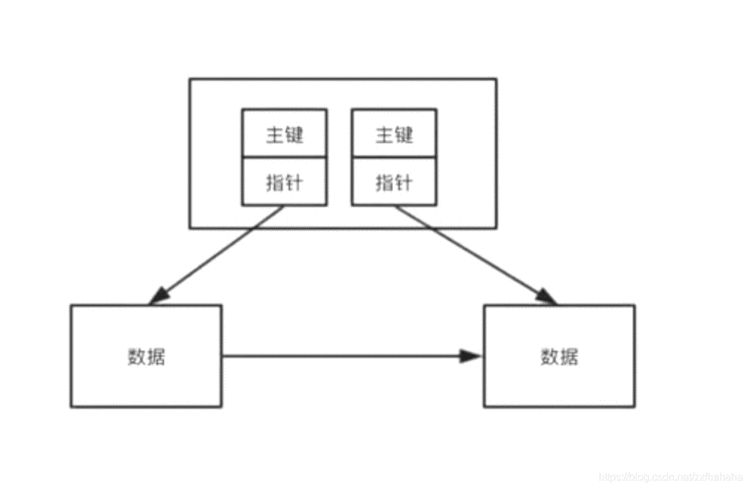
上面的是模拟,InnoDB的做法:
当第一页满了以后,会把第一页复制一份,把原来的第一页作为页目录.
这样可以保证入口永远不变.
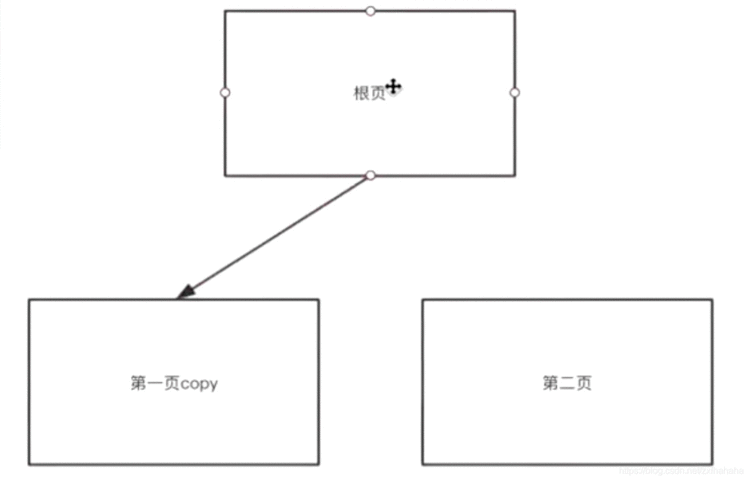
叶子结点存了所有排好序的数据
聚集索引和辅助索引
聚集索引
按照每个表的主键构造一颗B+树,同时页节点存放的是整张表的行记录数据,每一个叶子节点都被称为数据页。
聚集索引是逻辑上连续不是物理连续
聚集索引对于主键的排序查找和范围查找速度非常快
辅助索引
叶子节点并不包含记录的全部数据,每个叶子节点中的索引行中存的不是这一行数据而是主键.
通过这个主键去找对应的行数据
建立索引
建立索引 其实就是选择要排序的键, 按照我们选的键 进行排序 建立新的B+树
意思是用b c d 三个列 来建立索引, 就是b的值相同 就比较c 再比较d
create index idx_t1_bcd on t1(b,c,d)
索引的代价
空间上的代价
一个索引都为对应一棵B+树,树中每一个节点都是一个数据页,一个页默认会占用16KB的存储空间,所以一个索引也是会占用磁盘空间的。
时间上的代价
每次对表中的数据进行增删改操作时,都要去修改各个B+树索引





 京公网安备 11010802041100号
京公网安备 11010802041100号