作者:的士风云 | 来源:互联网 | 2024-12-12 18:10
本文介绍了在MySQL数据库中去除重复记录的有效方法,包括使用SQL语句直接操作以及利用第三方工具Spoon进行数据清洗。文章详细解释了如何通过SQL命令选择性地保留具有最小或最大ID的记录,并提供了针对大规模数据集的操作建议。
在MySQL数据库管理中,去除重复记录是一项常见的任务。本文将介绍几种有效的方法来处理这个问题,确保数据的准确性和完整性。
(一)使用SQL语句删除重复记录:
1. 保留最小ID的记录:
可以通过执行以下SQL语句来删除重复记录,同时保留每个分组中ID最小的记录:
DELETE FROM test WHERE id NOT IN (SELECT * FROM (SELECT MIN(id) FROM test GROUP BY name) AS tmpTable);
2. 保留最大ID的记录:
如果希望保留每个分组中ID最大的记录,则可以修改上述查询为:
DELETE FROM test WHERE id NOT IN (SELECT * FROM (SELECT MAX(id) FROM test GROUP BY name) AS tmpTable);
示例应用:
假设我们有一个名为log_visit_20131210的日志表,其中包含大量重复记录。我们可以使用类似的SQL语句来清理这些重复项:
DELETE FROM log_visit_20131210 WHERE id NOT IN (SELECT * FROM (SELECT MIN(id) FROM log_visit_20131210 GROUP BY domain, url, c_date, c_ip) AS tmpTable);
对于非常大的数据集,如包含数百万条记录的表,这种方法可能会比较耗时且资源密集。因此,在实际操作前应考虑备份数据并评估性能影响。
(二)使用Spoon工具进行数据去重:
Spoon(Kettle)是一个强大的ETL工具,它提供了一个直观的界面和丰富的功能,可以用来处理各种数据转换任务,包括去除重复记录。使用Spoon,用户可以轻松配置数据流以实现高效的数据清洗。
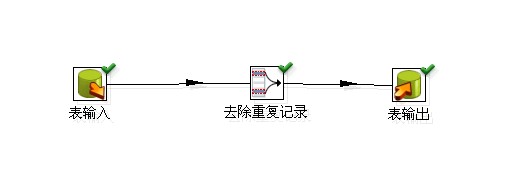
综上所述,无论是直接使用SQL语句还是借助于像Spoon这样的工具,都有助于有效地管理和维护MySQL数据库中的数据质量。







 京公网安备 11010802041100号
京公网安备 11010802041100号