

流行病学或者医学论文中,对研究对象基本情况的描述通常以表格的形式进行,并且放在结果部分的开头,即Table 1,主要内容是研究对象一般情况和研究变量或协变量的分组展示。
前几天文章修回过程中,花了两天时间分析数据,修改文章,其中有近1天的时间都在手动录入数据(从R studio里把分析结果整理到Excel或者word),这样除了花费时间外,还非常容易出错。之前一直想找时间通过R markdown把制作表格的过程程序化,可是效果并不理想。
这次痛定思痛,先从table 1开始,发现了几个不错的方法。其中一种个人觉得可读性和可编辑性都比较强,于是学习了一下,作为一个非常实用的工具分享给大家。
这里主要参考一篇博客Fast-track publishing using knitr: table mania,对细节进行了加工和注释。
1
数据的准备数据主要来自于boot包的melanoma。加载后,看下数据的基本结构。
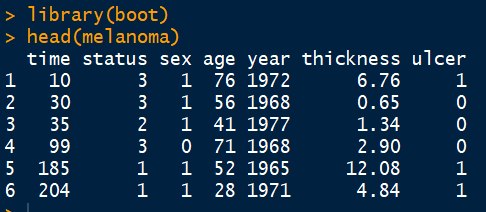
接下来对数据进行简单的整理,为后续分析做准备;
将分类变量定义为因子型并设置标签(这里建议设置一个新的变量,仅用于table 1的制作,不影响后续的分析);

2
安装和加载R包 Gmisc
后面两个包是加载“Gmisc”时要求加载的。
3
自定义函数、制作表格根据已有函数自定义函数,并制作表格。定义一个函数,输入数据集的变量并得到该变量的统计结果:
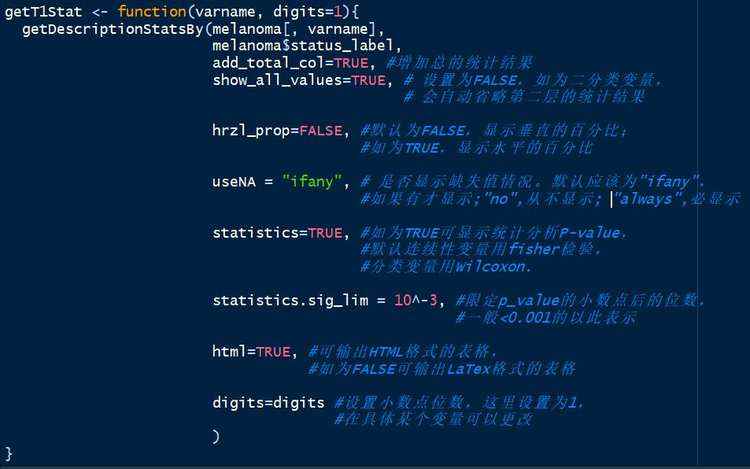
函数定义完成后,建立一个空的列表,以储存每个变量的分析结果,并进行分析,将结果储存在列表中:

将所有结果merge到一个矩阵中,并建立rgroup(table1第一列的变量名) 和 n.rgroup(table 1第一列每个变量的行数):
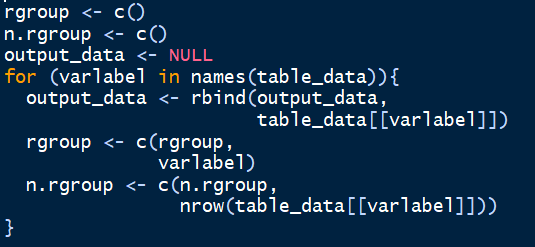
# 然后就一键生成html表格啦
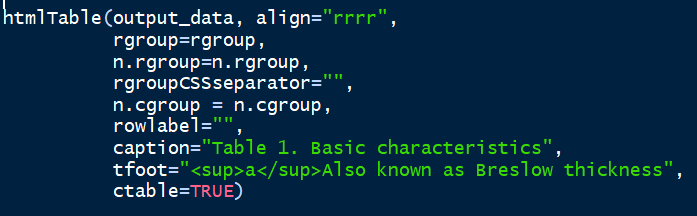
结果如下:
当然,有些情况下,需要多加一个分组标题栏(column spanner),该怎么加呢?
如下:
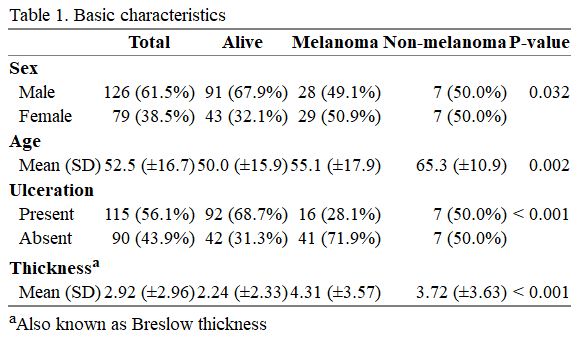
结果如下:

4
导出结果
在R studio viewer窗口点击白色按钮,即可在浏览器中打开,然后复制粘贴到word可以进一步加工修饰。
是不是很刺激呢。
应该还有其他的导出方法,不过这个已经很方便了。
拓展功能选
⒈ 二分类变量只显示一个(比如男性和女性)。只要在getDescriptionStatsBy的"show_all_values"参数设置为FALSE即可;
⒉ 显示缺失值。getDescriptionStatsBy的"useNA"参数设置为"ifany",表示如果有缺失值就显示缺失值情况;如设置为“no”,表示始终不显示缺失值情况;“always”则表示无论是否有缺失值都显示缺失值情况;
⒊ Total一列是可以去掉的,getDescriptionStatsBy的"add_total_col"参数设置为FALSE即可。
不足之处
⒈ 差异性检验是采用非参的方法,虽然没有错,但是一般符合参数检验条件的数据还是要使用参数检验的方法,这里可以自行检验后再修改P-value;
⒉ Mean (SD)的展示形式有个括号感觉有点别扭,还不知道怎么去掉,有方法的小伙伴欢迎分享交流。
另外有一些其他的制作table 1的R包,比如table 1(R包的名字)包,tableone包,还有其他生成表格的R包(plyr等),个人浏览下来感觉这个最容易理解和掌握,其他包的功能有兴趣的可以再自行挖掘对比。
- END -

征 稿 启 事
「医学方」现正式向粉丝们公开征稿!内容须原创首发,与科研相关,一经采用,会奉上丰厚稿酬(300-2000元),详情请戳。
“医学方”始终致力于服务“医学人”,将最前沿、最有价值的临床、科研原创文章推送给各位临床医师、科研人员。

医学方已推出“实验室那些事儿”“SCI写作技巧”“文献精读与解析”“医学英语轻松学”“国自然基金申请”“临床数据挖掘”、“基因数据挖掘”、“R语言教程”、“医学统计学”、“微创动物实验培训”等多个专题课程,如需了解课程详细推文,可关注“医学方”公众号,点击“精品专题”进入
腾讯课堂:https://medfun.ke.qq.com
网易云课堂:http://study.163.com/u/ykt1467466791112
客服电话:15821255568
客服微信:yixuefang1234

温馨提示:医学方还设有专门的讨论群哦~各位明星导师都在群中,可以解答各位的遇到的问题,如有兴趣,可以加客服微信后加入群聊...








 京公网安备 11010802041100号
京公网安备 11010802041100号