2020年6月17日一大早就看到了github推送的1.0版本更新的通知消息,在历经数个月的版本迭代中,1.0版本终于面世了。相比之前的0.x版本,此次allennlp在很多方面进行了改动,这里从我个人的使用角度出发,讲解一下版本变动。
https://github.com/allenai/allennlp/releasesgithub.com
1、将旧库拆分为两个辛苦,allennlp只负责核心逻辑,模型的定义、测试部分拆分到了下述连接
https://github.com/allenai/allennlp-modelsgithub.com
2、Iterators 部分从自定义,转换为兼容Pytorch中的DataLoaders。
好处:效率更高,兼容更好(例如与fastai的兼容)
3、多GPU使用更加高效。旧版本是一个进程,多个GPU,由于GIL的存在会使效率不高。新版本使每个GPU一个进程,这样速度会提升很多。
使用spawn的方式进行多GPU训练这里有个小问题,N个GPU时如何让每个GPU只分配到 数据/N 那么多的数据呢?
AllenNLP在1.0 prerelease中提到
In addition, if it is important that your dataset is correctly sharded such that one epoch strictly corresponds to one pass over the data, your dataset reader should contain the following logic to read instances on a per-worker basis:
rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
for idx, inputs in enumerate(data_file):if idx % world_size == rank:yield self.text_to_instance(inputs)
4、SingleIdTokenIndexer使用feature_name参数来使用Token中的相应字段。
好处:之前我们想使用Token中的词性字段,需要单独配置PosTokenIndexer,这些其实都是冗余的,此版本将其简化为
feature_name : `str`, optional (default=`"text"`)We will use the :class:`Token` attribute with this name as input. This is potentiallyuseful, e.g., for using NER tags instead of (or in addition to) surface forms as your inputs(passing `ent_type_` here would do that). If you use a non-default value here, you almostcertainly want to also change the `namespace` parameter, and you might want to give a`default_value`.
5、make_vocab命令没了,相同的功能由train中的dry-run参数来实现。
fintuning命令也没了。。。
subparser.add_argument("--dry-run",action="store_true",help="do not train a model, but create a vocabulary, show dataset statistics and ""other training information",)
6、新增BatchCallback与EpochCallback。顾名思义,在每个batch结束或epoch结束后,会调用相应的回调函数做一些事情。
class BatchCallback(Registrable):"""An optional callback that you can pass to the `GradientDescentTrainer` that will be called atthe end of every batch, during both training and validation. The default implementationdoes nothing. You can implement your own callback and do whatever you want, such as savingpredictions to disk or extra logging."""def __call__(self,trainer: "GradientDescentTrainer",batch_inputs: List[List[TensorDict]],batch_outputs: List[Dict[str, Any]],epoch: int,batch_number: int,is_training: bool,is_master: bool,) -> None:passclass EpochCallback(Registrable):"""An optional callback that you can pass to the `GradientDescentTrainer` that will be called atthe end of every epoch (and before the start of training, with `epoch=-1`). The defaultimplementation does nothing. You can implement your own callback and do whatever you want, suchas additional modifications of the trainer's state in between epochs."""def __call__(self,trainer: "GradientDescentTrainer",metrics: Dict[str, Any],epoch: int,is_master: bool,) -> None:pass
7、旧版本的模型保存是保存20个epoch的模型,而现在只保存2个。
. Also, the default for that setting is now2, so AllenNLP will no longer fill up your hard drive!
8、dataloader里不用指定字段了,allennlp会自动推测tokens等预设的字段进行排序
"data_loader": {"batch_sampler" :{"type": "bucket","batch_size": 8,"padding_noise": 0.0}},
除此之外,此次版本发布了一些新的模型、新的交互式的guide、支持通过apex进行16位运算、与transformer库结合更加紧密等等。此外一些jsonnet的配置方式也发生了更新,例如
The way Vocabulary options are specified in config files has changed. See#3550. If you want to load a vocabulary from files, you should specify"type": "from_files", and use the key"directory"instead of"directory_path".
这些都能在github的最新版release中找到,同时相应的配置可以参考
测试配置文件夹下有很多jsonnet配置项。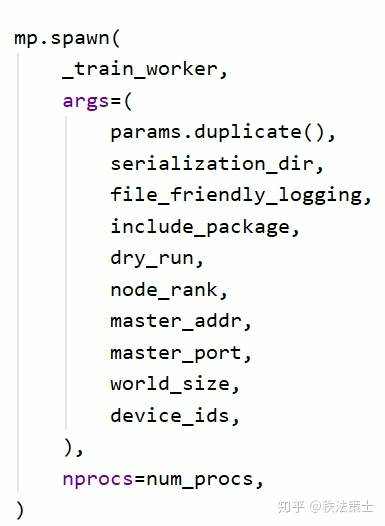







 京公网安备 11010802041100号
京公网安备 11010802041100号